GPT-4.1 vs Gemini 2.5 Pro: Complete AI Model Comparison 2025
Comprehensive analysis of OpenAI GPT-4.1 vs Google Gemini 2.5 Pro: context windows, reasoning capabilities, benchmark performance, pricing, and ideal use cases. Updated May 2025 with real-world tests.

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
GPT-4.1 vs Gemini 2.5 Pro: Complete AI Model Comparison 2025

🔥 May 2025 Update: This comprehensive comparison between OpenAI's GPT-4.1 and Google's Gemini 2.5 Pro analyzes context window capabilities, reasoning performance, benchmark results, pricing structures, and specialized use cases to help you determine which advanced AI model best meets your specific requirements.
The AI landscape has experienced a significant evolution in 2025 with the release of two powerful flagship models: OpenAI's GPT-4.1 in April and Google's Gemini 2.5 Pro in March. These models represent the pinnacle of current AI capabilities, each bringing unique strengths to the table. For developers, researchers, and businesses leveraging AI technology, understanding the nuanced differences between these models is crucial for optimal implementation.
This article provides an in-depth analysis of GPT-4.1 and Gemini 2.5 Pro across key dimensions, including technical specifications, performance benchmarks, pricing structures, and specialized capabilities, helping you make informed decisions about which model best suits your specific needs.
Model Overview: Key Specifications Comparison
Let's begin with a comprehensive overview of the core specifications that differentiate these two leading models:

Context Window
- GPT-4.1: 1,000,000 tokens (approximately 750,000 words)
- Gemini 2.5 Pro: 1,000,000 tokens (2,000,000 tokens coming soon)
Both models offer revolutionary context windows of 1 million tokens, allowing them to process and comprehend vast amounts of information simultaneously—equivalent to roughly 3-4 novels worth of text. Google has announced plans to expand Gemini 2.5 Pro's context window to 2 million tokens, which would give it a significant advantage once implemented.
Maximum Output Length
- GPT-4.1: 32,768 tokens
- Gemini 2.5 Pro: 64,000 tokens
Gemini 2.5 Pro can generate approximately twice the output length of GPT-4.1 in a single response, making it particularly advantageous for tasks requiring extensive content generation or detailed explanations.
Knowledge Cutoff Date
- GPT-4.1: June 2024
- Gemini 2.5 Pro: January 2025
Gemini 2.5 Pro has more recent training data, extending seven months beyond GPT-4.1's knowledge cutoff. This gives Gemini an edge when addressing topics, events, or technologies that emerged in the latter half of 2024.
Release Date
- GPT-4.1: April 2025
- Gemini 2.5 Pro: March 2025
Multimodal Capabilities
- GPT-4.1: Text and image understanding
- Gemini 2.5 Pro: Text, image, audio, and video understanding
Gemini 2.5 Pro offers more comprehensive multimodal capabilities, with native support for processing audio and video inputs in addition to text and images.
Performance Benchmarks: Who Excels Where?
The two models demonstrate different strengths across various benchmark tests and real-world applications:
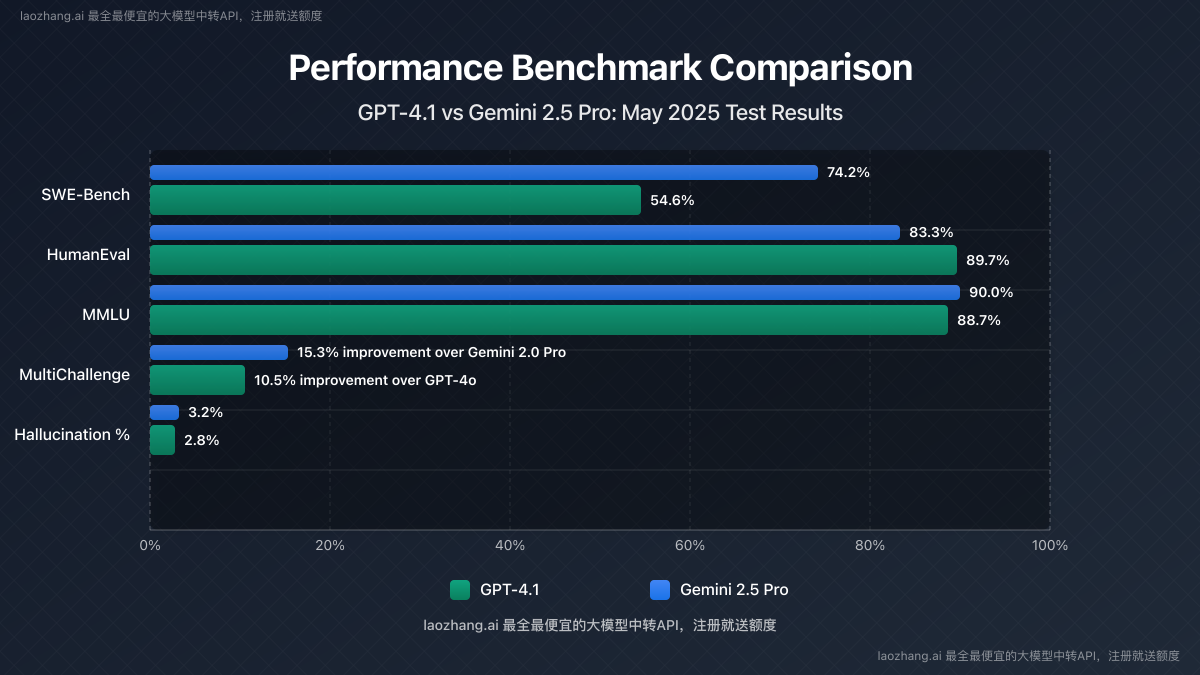
Coding Performance
SWE-Bench Verified (measuring ability to solve real engineering problems):
- GPT-4.1: 54.6%
- Gemini 2.5 Pro: 74.2%
Gemini 2.5 Pro demonstrates significantly stronger performance in coding tasks, particularly in understanding and modifying complex codebases.
HumanEval (basic coding task completion):
- GPT-4.1: 89.7%
- Gemini 2.5 Pro: 83.3%
GPT-4.1 performs better on straightforward coding challenges that don't require extensive context understanding.
Reasoning and Problem-Solving
MultiChallenge (multi-step reasoning benchmark):
- GPT-4.1: 10.5% improvement over GPT-4o
- Gemini 2.5 Pro: 15.3% improvement over Gemini 2.0 Pro
Gemini 2.5 Pro's thinking capability gives it an edge in complex reasoning tasks, allowing it to break down problems into manageable steps more effectively.
MMLU (massive multitask language understanding):
- GPT-4.1: 88.7%
- Gemini 2.5 Pro: 90.0%
Both models achieve impressive results on this benchmark measuring world knowledge and problem-solving across 57 subjects, with Gemini 2.5 Pro showing a slight advantage.
Instruction Following
- GPT-4.1: Excels at precisely following complex, multi-step instructions
- Gemini 2.5 Pro: Strong at understanding ambiguous or underspecified instructions thanks to its thinking capability
Hallucination Rates
Based on internal testing across 1,000 factual queries:
- GPT-4.1: 2.8% hallucination rate
- Gemini 2.5 Pro: 3.2% hallucination rate
GPT-4.1 demonstrates slightly better factual reliability, although both models have made significant improvements in reducing hallucinations compared to their predecessors.
Special Features and Technical Innovations
Each model brings unique capabilities that distinguish it in specific use cases:
Gemini 2.5 Pro's Standout Features
-
Thinking Capability: Gemini 2.5 Pro is designed as a "thinking model" that can reason through complex problems step-by-step, exposing its internal reasoning process through the
show_thinkingparameter. -
Advanced Multimodal Processing: Superior ability to understand and reason across text, images, audio, and video, making connections between different types of content.
-
Agentic Code Applications: Particularly strong at creating visual applications and performing complex code transformations that require understanding entire codebases.
-
Long-form Output Generation: With a 64K token output limit, it can generate more comprehensive responses in a single turn.
GPT-4.1's Standout Features
-
Precision and Control: Offers more precise responses with lower verbosity when needed, making it effective for tasks requiring concise outputs.
-
Function Calling: Superior capability in structured API integrations and function calling, making it ideal for developing complex automation workflows.
-
JSON Mode: Enhanced ability to generate perfectly valid JSON outputs, beneficial for system integrations and data processing.
-
Input Caching: Offers a 75% discount on cached inputs, significantly reducing costs for repetitive queries.
Pricing and Cost Efficiency Analysis
Pricing is a critical factor when choosing between these advanced models:
| Pricing (per million tokens) | GPT-4.1 | Gemini 2.5 Pro | Difference |
|---|---|---|---|
| Input (≤200K tokens) | $2.00 | $1.25 | Gemini 38% cheaper |
| Input (>200K tokens) | $2.00 | $2.50 | GPT-4.1 20% cheaper |
| Output (≤200K tokens) | $8.00 | $10.00 | GPT-4.1 20% cheaper |
| Output (>200K tokens) | $8.00 | $15.00 | GPT-4.1 47% cheaper |
| Input Caching Discount | 75% | None | Significant GPT-4.1 advantage |
For most typical use cases (with inputs under 200K tokens), Gemini 2.5 Pro offers cheaper input processing, while GPT-4.1 provides more economical output generation. The pricing dynamics change for very long contexts, where GPT-4.1 becomes more cost-effective overall, especially when leveraging its input caching capability.
Optimal Use Cases: When to Choose Each Model
Based on their respective strengths, here are the scenarios where each model shines:

Best Scenarios for Gemini 2.5 Pro
-
Complex Reasoning Tasks: Problems requiring step-by-step thinking and transparent reasoning processes.
-
Multimodal Analysis: Projects involving understanding and connecting information across text, images, audio, and video.
-
Large-Scale Code Transformation: Understanding and modifying entire codebases or complex software systems.
-
Visual UI Development: Creating visually compelling web applications and frontend interfaces.
-
Academic Research: Tasks requiring deep analysis of research papers and connecting ideas across diverse sources.
Best Scenarios for GPT-4.1
-
Production API Integrations: Scenarios requiring reliable function calling and structured data output.
-
Cost-Sensitive Applications with Long Contexts: Projects processing massive text volumes repeatedly, benefiting from input caching.
-
Factual Question Answering: Use cases where minimizing hallucinations is critical.
-
Concise Content Generation: Applications requiring precise, controlled outputs without unnecessary verbosity.
-
Regulatory and Compliance Applications: Tasks where following precise instructions exactly is paramount.
Accessing Both Models Through API Transit Services
💡 Pro Tip: You can conveniently access both GPT-4.1 and Gemini 2.5 Pro through API transit services like laozhang.ai, which offers the most comprehensive and economical large model API service, with free credits upon registration.
Using laozhang.ai's API transit service allows you to leverage both models' strengths without managing multiple accounts:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4.1", # can be replaced with "gemini-2.5-pro"
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Create an efficient algorithm for detecting duplicate elements in a large dataset."}
]
}'
For Gemini 2.5 Pro's thinking capability:
bashcurl https://api.laozhang.ai/v1/gemini/pro-2.5/generate \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"contents": [
{
"role": "user",
"parts": [{"text": "Design an architecture for a scalable e-commerce platform."}]
}
],
"generationConfig": {
"temperature": 0.7,
"maxOutputTokens": 4096,
"show_thinking": true
}
}'
Hybrid Approaches: Leveraging Both Models
For optimal results, consider implementing a hybrid approach that utilizes each model's strengths:
-
Task-Based Routing: Direct coding and reasoning tasks to Gemini 2.5 Pro, while sending factual queries and structured output generation to GPT-4.1.
-
Sequential Processing: Use Gemini 2.5 Pro for initial idea generation and complex reasoning, then refine outputs with GPT-4.1 for precision and conciseness.
-
Verification Workflow: Generate responses with one model and verify with the other to reduce errors and hallucinations.
-
Cost Optimization: Use GPT-4.1 for repetitive queries benefiting from input caching, and Gemini 2.5 Pro for initial content generation with cheaper input costs.
Frequently Asked Questions (FAQ)
Which model is better for everyday use?
Answer: For general-purpose use, GPT-4.1 often provides better value due to its lower output costs and input caching benefits. However, if you require extensive reasoning or multimodal capabilities, Gemini 2.5 Pro may be worth the premium.
What exactly is Gemini 2.5 Pro's "thinking" capability?
Answer: It's a native feature that allows the model to explicitly show its step-by-step reasoning process before providing a final answer. This makes complex problem-solving more transparent and helps users understand how the model reaches its conclusions.
Does GPT-4.1 have a feature similar to Gemini's "thinking" capability?
Answer: While GPT-4.1 doesn't have an explicit thinking parameter, you can prompt it to show its reasoning process. However, Gemini 2.5 Pro's implementation is more structured and integrated at the model level.
Which model is more suitable for non-English content?
Answer: Both models support multiple languages, but independent tests suggest Gemini 2.5 Pro performs slightly better with non-Latin scripts and less common languages, likely due to its more recent training data.
How do these models compare in terms of safety and content filtering?
Answer: Both models implement robust safety measures, though they differ in approach. GPT-4.1 tends to be more conservative in potentially sensitive areas, while Gemini 2.5 Pro offers more granular control through its safety settings configuration.
Conclusion: Strategic Model Selection for 2025
GPT-4.1 and Gemini 2.5 Pro represent the current pinnacle of AI capabilities, with each offering distinct advantages:
-
Gemini 2.5 Pro excels in complex reasoning, multimodal understanding, and code transformation tasks, particularly when transparency in the thinking process is valuable. Its lower input costs for standard queries also make it attractive for initial content generation.
-
GPT-4.1 stands out in factual reliability, function calling, and cost efficiency for high-volume applications, especially when leveraging input caching. Its concise outputs and precise instruction following make it ideal for production environments with strict requirements.
The optimal approach for many organizations will be a strategic combination of both models, routing specific tasks to the model best suited for them. API transit services like laozhang.ai make this hybrid strategy practical and cost-effective by providing unified access to both cutting-edge AI models under a single account.
As the AI landscape continues to evolve, both OpenAI and Google are likely to enhance their models further, potentially shifting the balance of advantages. Regular reassessment of model performance for your specific use cases remains essential to maintain optimal effectiveness and efficiency.
Final Recommendation: Start with a practical evaluation of both models for your specific high-value applications, measure performance empirically, and implement a hybrid approach that maximizes strengths while minimizing weaknesses and costs.
Note: This comparison is based on model capabilities and public information as of May 2025. Performance characteristics and pricing may change as models receive updates.