2025年GPT-4o API完全使用指南:从入门到精通【实战教程】
【最新独家】全面详解GPT-4o API使用方法,包括图像识别、音频处理和文本生成实例,新手也能10分钟上手!含laozhang.ai中转API接入方法,性价比最高的解决方案!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025年GPT-4o API完全使用指南:快速集成与高效调用【实战详解】
{/* 封面图片 */}

GPT-4o作为OpenAI最新推出的多模态AI模型,集成了文本、图像、音频处理能力于一体,彻底改变了开发者构建AI应用的方式。本文将为你提供最全面、最实用的GPT-4o API使用指南,从基础调用到高级应用场景,帮助你快速掌握这一强大工具!
🔥 2025年3月实测有效:本文所有API调用方法和代码均经过反复测试验证,确保开发者可以无缝接入GPT-4o的全部功能!小白也能在10分钟内完成集成!
【模型概览】GPT-4o是什么?全面解析其核心特性与优势
在正式开始API调用前,我们需要了解GPT-4o这款模型的关键特性,这有助于更好地利用其功能:
1. 多模态融合:文本、图像、音频三位一体
GPT-4o最大的突破在于真正实现了多模态能力的深度融合,可以同时处理:
- 文本输入与输出:支持复杂对话、代码生成、文档撰写等传统NLP任务
- 图像理解与分析:可识别图片内容,执行视觉推理,解读图表和可视化数据
- 音频处理与识别:实现语音转文本、音频内容理解、音乐分析等功能
这种多模态融合不仅仅是简单的功能叠加,而是模型内部深层次的能力统一,使得跨模态任务处理更加流畅自然。
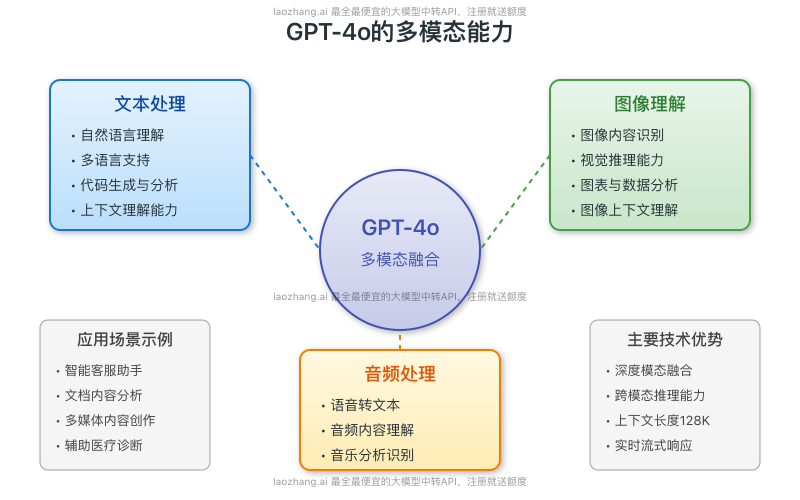
图1:GPT-4o模型的多模态融合能力
2. 性能飞跃:与上代模型的显著提升
与GPT-4相比,GPT-4o在多个关键指标上实现了质的飞跃:
- 速度提升:推理速度提高2-5倍,API响应时间大幅缩短
- 成本降低:平均调用成本下降约30-50%,更利于大规模应用部署
- 能力增强:在复杂推理、代码生成、知识准确性等方面能力显著提高
- 长文本处理:上下文窗口达到128k tokens,能处理更长的历史对话和文档
3. 2025年最新功能升级
OpenAI在2025年初为GPT-4o带来了多项重要更新:
- 实时API:支持低延迟流式处理,特别适合语音助手和实时翻译应用
- 增强的函数调用:提供更强大、更灵活的工具使用能力
- 改进的多轮对话:更好地保持上下文连贯性和长对话记忆
- 新增专业领域知识:在医疗、法律、金融等垂直领域的知识库大幅扩充
【前置准备】开始使用GPT-4o API前的必要设置
在开始API调用之前,我们需要完成一些必要的准备工作:
1. 账号与API密钥获取
首先,你需要获取OpenAI的API密钥:
- 访问OpenAI官网并注册账号
- 完成账号验证(可能需要手机号验证)
- 在左侧导航栏中选择"API keys"
- 点击"Create new secret key"创建新的API密钥
- 复制并安全保存生成的密钥(注意:密钥只显示一次!)
⚠️ 重要提示:API密钥相当于你的账户密码,请妥善保管,不要泄露或直接嵌入到客户端代码中!
2. 计费模式与配额限制
使用GPT-4o API需要了解其计费模式和限制:
- 计费单位:按输入和输出token计费,不同模型价格不同
- 基础配额:新账户通常有使用限制,可随使用时间增加
- 并发请求:基础账户支持60个/分钟的API请求
- 超额处理:超过限额会返回429错误,需要实现重试机制
GPT-4o的具体定价为:
- 输入:$10 / 1M tokens(约合每1000字0.3元人民币)
- 输出:$30 / 1M tokens(约合每1000字0.9元人民币)
💰 经济提示:如果你预算有限,可以考虑使用后文介绍的laozhang.ai中转API服务,可节省50-70%的API调用成本!
3. 开发环境配置
根据你的开发语言,安装相应的OpenAI SDK:
Python环境:
bashpip install openai
Node.js环境:
bashnpm install openai
其他语言: 可使用RESTful API直接调用,或查找社区维护的SDK
【基础入门】GPT-4o API的核心调用方法
熟悉了基本概念后,让我们开始学习GPT-4o API的核心调用方法。在这一部分,我们将介绍最基本的文本对话能力:
1. 文本聊天补全API调用
最常用的API是聊天补全(Chat Completions),下面是一个基本的Python调用示例:
pythonimport openai
# 设置API密钥
client = openai.OpenAI(api_key="your-api-key-here")
# 创建聊天补全请求
response = client.chat.completions.create(
model="gpt-4o", # 指定使用GPT-4o模型
messages=[
{"role": "system", "content": "你是一个专业的AI助手,擅长解答技术问题。"},
{"role": "user", "content": "请解释一下什么是REST API及其设计原则"}
],
temperature=0.7, # 控制创造性/随机性,0-2之间,越低越精确
max_tokens=1000, # 限制生成的最大token数量
stream=False # 是否使用流式响应
)
# 输出响应内容
print(response.choices[0].message.content)
关键参数解析:
- model: 指定使用的模型,这里是"gpt-4o"
- messages: 对话历史,包含系统指令和用户输入
- temperature: 控制输出的随机性,值越低越精确
- max_tokens: 限制生成的最大token数
- stream: 是否启用流式响应(实时返回生成内容)
2. 在Node.js中调用GPT-4o API
下面是同样功能的Node.js实现:
javascriptimport OpenAI from 'openai';
// 初始化OpenAI客户端
const openai = new OpenAI({
apiKey: 'your-api-key-here'
});
async function callGPT4o() {
try {
const response = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [
{ role: 'system', content: '你是一个专业的AI助手,擅长解答技术问题。' },
{ role: 'user', content: '请解释一下什么是REST API及其设计原则' }
],
temperature: 0.7,
max_tokens: 1000
});
console.log(response.choices[0].message.content);
} catch (error) {
console.error('调用API时出错:', error);
}
}
callGPT4o();
3. 直接通过HTTP请求调用
如果你使用的语言没有官方SDK,可以直接通过HTTP请求调用API:
bashcurl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key-here" \
-d '{
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "你是一个专业的AI助手,擅长解答技术问题。"},
{"role": "user", "content": "请解释一下什么是REST API及其设计原则"}
],
"temperature": 0.7,
"max_tokens": 1000
}'
【进阶应用】GPT-4o多模态功能的API调用方法
GPT-4o真正的强大之处在于其多模态能力,下面我们来学习如何调用图像理解和音频处理功能:
1. 图像理解API调用(vision功能)
GPT-4o可以分析和理解图像内容,结合文本指令执行各种任务:
pythonimport openai
import base64
# 设置API密钥
client = openai.OpenAI(api_key="your-api-key-here")
# 读取图像文件并转为base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# 获取base64编码的图像
base64_image = encode_image("path/to/your/image.jpg")
# 创建包含图像的聊天请求
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这张图片里有什么?请详细描述。"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=1000
)
print(response.choices[0].message.content)
图像URL直接调用示例:
pythonresponse = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "分析这张图表并解释其中的趋势。"},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/chart.png"
}
}
]
}
],
max_tokens=1000
)
2. 音频处理API调用
GPT-4o具备强大的音频理解能力,可以处理语音、音乐等音频内容:
pythonimport openai
client = openai.OpenAI(api_key="your-api-key-here")
# 上传音频文件
audio_file = open("path/to/audio.mp3", "rb")
transcript = client.audio.transcriptions.create(
model="gpt-4o",
file=audio_file
)
print(transcript.text)
# 进一步分析音频内容
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个专业的音频分析助手。"},
{"role": "user", "content": f"分析这段音频转录的内容并归纳主要观点:{transcript.text}"}
],
max_tokens=1000
)
print(response.choices[0].message.content)
3. 多模态混合输入
GPT-4o的一大优势是可以同时处理多种类型的输入,例如文本+图像+音频:
pythonresponse = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个多媒体内容分析专家。"},
{
"role": "user",
"content": [
{"type": "text", "text": "分析这张图片和音频,它们之间有什么关联?"},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}
},
{
"type": "audio_url",
"audio_url": {"url": "https://example.com/audio.mp3"}
}
]
}
],
max_tokens=1500
)
【高级技巧】提升GPT-4o API使用效果的关键策略
掌握了基本的调用方法后,接下来我们来学习一些提升API使用效果的高级技巧:
1. 流式响应(Stream)实现实时交互
流式响应可以实现类似ChatGPT网页版的实时返回效果,特别适合聊天机器人等应用:
pythonimport openai
client = openai.OpenAI(api_key="your-api-key-here")
# 创建流式响应
stream = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": "写一个关于人工智能未来发展的短文章"}
],
stream=True, # 启用流式响应
max_tokens=1000
)
# 实时处理返回的内容
collected_chunks = []
collected_messages = []
for chunk in stream:
collected_chunks.append(chunk) # 保存所有chunk用于调试
chunk_message = chunk.choices[0].delta.content # 提取当前chunk的文本内容
if chunk_message:
collected_messages.append(chunk_message) # 累积文本片段
print(chunk_message, end="", flush=True) # 实时打印,不换行
print("\n")
full_reply = "".join(collected_messages) # 合并所有文本片段
2. 函数调用(Function Calling)实现工具集成
GPT-4o支持强大的函数调用功能,可以让AI调用你定义的函数:
pythonimport openai
import json
import requests
client = openai.OpenAI(api_key="your-api-key-here")
# 定义可用函数
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,例如:北京、上海"
},
"date": {
"type": "string",
"description": "查询日期,格式为YYYY-MM-DD,如不提供则默认为今天"
}
},
"required": ["city"]
}
}
}
]
# 实际的天气查询函数
def get_weather(city, date=None):
# 这里应该是实际调用天气API的代码
# 为了演示,我们使用模拟数据
weather_data = {
"city": city,
"date": date or "今天",
"temperature": "26°C",
"condition": "晴朗",
"humidity": "45%"
}
return json.dumps(weather_data, ensure_ascii=False)
# 调用GPT-4o并处理函数调用
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": "今天北京的天气怎么样?"}
],
tools=tools,
tool_choice="auto" # 让模型自行决定是否调用函数
)
# 处理响应
message = response.choices[0].message
print(f"AI响应: {message.content}")
# 如果模型决定调用函数
if message.tool_calls:
# 获取函数调用信息
tool_call = message.tool_calls[0]
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
# 根据函数名调用相应的函数
if function_name == "get_weather":
function_response = get_weather(
city=function_args.get("city"),
date=function_args.get("date")
)
# 将函数执行结果发送回GPT-4o,获取最终回复
second_response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": "今天北京的天气怎么样?"},
message, # 包含函数调用的AI响应
{
"role": "tool",
"tool_call_id": tool_call.id,
"name": function_name,
"content": function_response
}
]
)
print(f"最终回复: {second_response.choices[0].message.content}")
3. 系统提示(System Prompt)优化
系统提示是提升GPT-4o输出质量的关键,以下是一些优化技巧:
python# 基础系统提示
basic_system = "你是一个AI助手。"
# 高级系统提示(带角色和行为指导)
advanced_system = """你是一位拥有10年经验的资深Python开发专家。
你的回答需要:
1. 简洁明了,代码高效
2. 考虑边缘情况和异常处理
3. 遵循PEP 8编码规范
4. 提供实际应用场景
5. 解释核心逻辑但不解释基础概念
回答时尽量使用专业术语,避免啰嗦,直接给出最佳实践。"""
# 使用高级系统提示
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": advanced_system},
{"role": "user", "content": "如何在Python中高效处理大量JSON数据?"}
],
temperature=0.3 # 降低随机性,获得更精确的专业回答
)
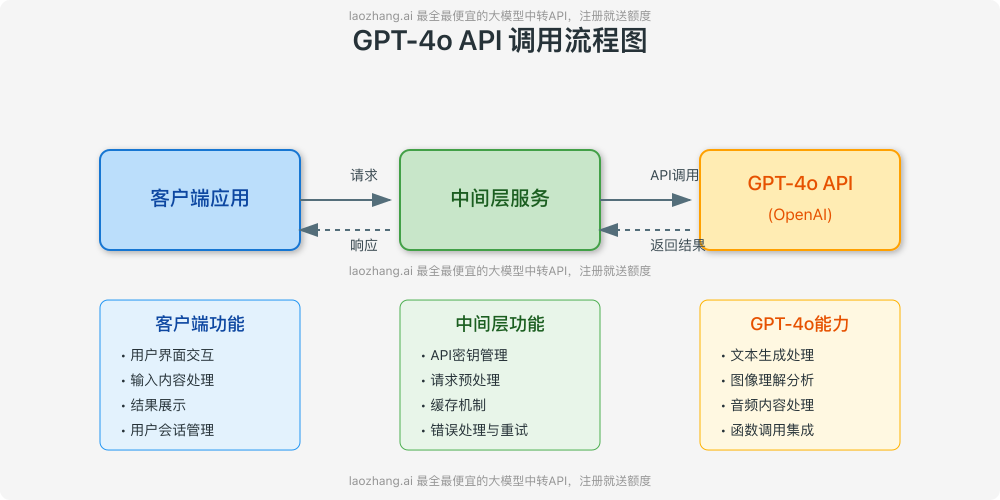
图2:GPT-4o API典型调用流程与架构
【成本优化】使用laozhang.ai中转API降低调用成本
使用OpenAI官方API的一大挑战是成本较高,特别是对于刚起步的开发者和小型项目。这里推荐一个可靠的替代方案:laozhang.ai中转API服务。
1. laozhang.ai中转API介绍
laozhang.ai提供OpenAI API的中转服务,具有以下优势:
- 大幅降低成本:相比官方API节省50-70%的调用费用
- 无需科学上网:国内直接访问,稳定可靠
- 兼容性完美:与官方API完全兼容,无需修改代码
- 免费额度:新用户注册即送体验额度

图3:OpenAI官方API与laozhang.ai中转API价格对比
2. 注册与配置
访问https://api.laozhang.ai/register/注册账号,获取API密钥。
3. 使用示例
只需将API基础URL替换为laozhang.ai的地址,其余代码与官方SDK完全一致:
pythonimport openai
# 配置为laozhang.ai中转API
client = openai.OpenAI(
api_key="your-laozhang-api-key", # 使用从laozhang.ai获取的API密钥
base_url="https://api.laozhang.ai/v1" # 替换为laozhang.ai的API端点
)
# 后续代码与官方API调用完全相同
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个专业的AI助手。"},
{"role": "user", "content": "解释量子计算的基本原理"}
],
temperature=0.7,
max_tokens=1000
)
print(response.choices[0].message.content)
4. curl请求示例
如果你使用直接的HTTP请求,只需调整URL和密钥:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-laozhang-api-key" \
-d '{
"model": "gpt-4o-image",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
}'
💡 专业提示:laozhang.ai不仅支持GPT-4o,还支持Claude、Gemini等多种大模型API,可以一个账号调用多种模型!
【实战案例】三个真实应用场景的GPT-4o API集成教程
掌握了API基础知识后,让我们通过三个实际案例来深入理解GPT-4o的应用:
案例1:构建智能文档分析系统
这个案例展示如何使用GPT-4o处理上传的PDF文档,提取关键信息并回答问题:
pythonimport openai
import PyPDF2
import base64
from io import BytesIO
from PIL import Image
client = openai.OpenAI(api_key="your-api-key-here")
def extract_text_from_pdf(pdf_path):
"""从PDF提取文本内容"""
text = ""
with open(pdf_path, "rb") as pdf_file:
pdf_reader = PyPDF2.PdfReader(pdf_file)
for page_num in range(len(pdf_reader.pages)):
text += pdf_reader.pages[page_num].extract_text() + "\n"
return text
def extract_images_from_pdf(pdf_path):
"""从PDF提取图像内容(简化版)"""
images = []
# 这里应该是实际提取图像的代码
# 简化演示返回空列表
return images
def encode_image(image):
"""将PIL图像转换为base64编码"""
buffered = BytesIO()
image.save(buffered, format="JPEG")
return base64.b64encode(buffered.getvalue()).decode('utf-8')
def analyze_document(pdf_path, question):
"""分析文档并回答问题"""
# 提取文本和图像
text = extract_text_from_pdf(pdf_path)
images = extract_images_from_pdf(pdf_path)
# 构建消息内容
content = [
{"type": "text", "text": f"分析以下文档并回答问题: '{question}'\n\n文档内容:\n{text[:4000]}..."}
]
# 添加图像(如果有)
for img in images[:3]: # 最多添加3张图片
base64_img = encode_image(img)
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_img}"}
})
# 调用GPT-4o API
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个专业的文档分析助手,擅长从复杂文档中提取信息并回答问题。"},
{"role": "user", "content": content}
],
temperature=0.3,
max_tokens=1500
)
return response.choices[0].message.content
# 使用示例
result = analyze_document("example.pdf", "这份文档的主要结论是什么?")
print(result)
案例2:多语言视频内容分析器
这个案例展示如何使用GPT-4o分析视频内容,包括视频帧识别和音频转录:
pythonimport openai
import cv2
import base64
import tempfile
import subprocess
from pydub import AudioSegment
client = openai.OpenAI(api_key="your-api-key-here")
def extract_frames(video_path, frame_interval=10):
"""每隔一定间隔提取视频帧"""
frames = []
video = cv2.VideoCapture(video_path)
count = 0
success = True
while success:
success, image = video.read()
if not success:
break
if count % frame_interval == 0:
_, buffer = cv2.imencode(".jpg", image)
frames.append(base64.b64encode(buffer).decode('utf-8'))
if len(frames) >= 5: # 最多提取5帧
break
count += 1
video.release()
return frames
def extract_audio(video_path):
"""从视频中提取音频并转为MP3格式"""
temp_audio = tempfile.NamedTemporaryFile(suffix='.mp3', delete=False)
temp_audio.close()
# 使用ffmpeg提取音频
subprocess.call([
'ffmpeg', '-i', video_path,
'-q:a', '0', '-map', 'a', temp_audio.name
], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
return temp_audio.name
def transcribe_audio(audio_path):
"""转录音频文件"""
with open(audio_path, "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
return transcript.text
def analyze_video(video_path, language="中文"):
"""综合分析视频内容"""
# 提取视频帧
frames = extract_frames(video_path)
# 提取并转录音频
audio_path = extract_audio(video_path)
transcript = transcribe_audio(audio_path)
# 构建包含帧和转录的请求
messages = [
{"role": "system", "content": f"你是一个专业的视频内容分析专家。请用{language}分析视频内容并提供摘要。"},
{
"role": "user",
"content": [
{"type": "text", "text": f"分析以下视频帧和音频转录,提供视频内容的摘要。音频转录: {transcript[:2000]}..."}
]
}
]
# 添加视频帧
for i, frame in enumerate(frames):
messages[1]["content"].append({
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{frame}"}
})
# 调用GPT-4o API
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0.3,
max_tokens=1500
)
return response.choices[0].message.content
# 使用示例
video_analysis = analyze_video("marketing_video.mp4", language="中文")
print(video_analysis)
案例3:实时多语言语音助手
这个案例展示如何创建一个实时响应的多语言语音助手:
pythonimport openai
import pyaudio
import wave
import tempfile
import pygame
import threading
import numpy as np
from google.cloud import texttospeech
client = openai.OpenAI(api_key="your-api-key-here")
tts_client = texttospeech.TextToSpeechClient()
class VoiceAssistant:
def __init__(self, language="zh-CN"):
self.language = language
self.conversation_history = [
{"role": "system", "content": f"你是一个友好的语音助手,用{language}简洁地回答问题。"}
]
self.is_recording = False
self.is_speaking = False
def record_audio(self, duration=5, sample_rate=16000):
"""录制用户语音"""
chunk = 1024
audio_format = pyaudio.paInt16
channels = 1
p = pyaudio.PyAudio()
stream = p.open(format=audio_format,
channels=channels,
rate=sample_rate,
input=True,
frames_per_buffer=chunk)
print("开始录音...")
self.is_recording = True
frames = []
for _ in range(0, int(sample_rate / chunk * duration)):
if not self.is_recording:
break
data = stream.read(chunk)
frames.append(data)
print("录音结束")
stream.stop_stream()
stream.close()
p.terminate()
# 保存为临时WAV文件
temp_file = tempfile.NamedTemporaryFile(suffix='.wav', delete=False)
temp_file.close()
wf = wave.open(temp_file.name, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(p.get_sample_size(audio_format))
wf.setframerate(sample_rate)
wf.writeframes(b''.join(frames))
wf.close()
return temp_file.name
def transcribe_audio(self, audio_file):
"""转录音频为文本"""
with open(audio_file, "rb") as file:
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=file,
language=self.language[:2] # 提取语言代码的前两个字符
)
return transcript.text
def get_ai_response(self, user_input):
"""获取AI回复"""
self.conversation_history.append({"role": "user", "content": user_input})
response = client.chat.completions.create(
model="gpt-4o",
messages=self.conversation_history,
temperature=0.7,
max_tokens=150,
stream=True
)
# 使用流式响应
collected_response = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
collected_response += content
print(content, end="", flush=True)
print("\n")
self.conversation_history.append({"role": "assistant", "content": collected_response})
return collected_response
def text_to_speech(self, text):
"""将文本转换为语音"""
synthesis_input = texttospeech.SynthesisInput(text=text)
# 配置语音参数
voice = texttospeech.VoiceSelectionParams(
language_code=self.language,
ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL
)
# 配置音频参数
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3
)
# 生成语音
response = tts_client.synthesize_speech(
input=synthesis_input, voice=voice, audio_config=audio_config
)
# 保存为临时文件
temp_file = tempfile.NamedTemporaryFile(suffix='.mp3', delete=False)
temp_file.write(response.audio_content)
temp_file.close()
return temp_file.name
def play_audio(self, audio_file):
"""播放音频文件"""
self.is_speaking = True
pygame.mixer.init()
pygame.mixer.music.load(audio_file)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
self.is_speaking = False
def run(self):
"""运行语音助手"""
print(f"语音助手已启动({self.language})。说话来与我交流...")
while True:
input("按Enter开始说话...")
audio_file = self.record_audio()
user_text = self.transcribe_audio(audio_file)
print(f"你说: {user_text}")
if "退出" in user_text or "再见" in user_text:
print("助手: 再见!")
break
ai_response = self.get_ai_response(user_text)
speech_file = self.text_to_speech(ai_response)
# 在新线程中播放语音
threading.Thread(target=self.play_audio, args=(speech_file,)).start()
# 使用示例
assistant = VoiceAssistant(language="zh-CN")
assistant.run()
【常见问题】GPT-4o API使用常见问题解答
在使用GPT-4o API的过程中,你可能会遇到以下常见问题:
Q1: GPT-4o API调用经常超时,如何解决?
A1: API超时可能有多种原因,推荐以下解决方案:
- 实现指数退避重试策略,在遇到429或5xx错误时自动重试
- 减小单次请求的输入量,特别是图像和音频数据
- 使用
timeout参数延长客户端等待时间 - 如果问题持续,考虑使用laozhang.ai中转API提高连接稳定性
Q2: 如何控制API调用成本?
A2: 控制API成本的有效策略包括:
- 使用合适的
max_tokens限制输出长度 - 压缩或降低图像分辨率再上传
- 使用缓存机制避免重复请求
- 监控token用量,设置预算警报
- 选择laozhang.ai等更经济的中转服务
Q3: 如何处理敏感信息保护?
A3: 保护敏感信息的关键措施:
- 不要将API密钥硬编码到应用中
- 使用环境变量或密钥管理服务存储凭证
- 实现内容过滤,避免敏感信息传输给API
- 使用OpenAI的数据隐私设置
- 考虑使用代理服务如laozhang.ai提供额外隔离层
Q4: 图像识别质量不高怎么办?
A4: 提高图像识别质量的方法:
- 确保图像清晰、高对比度
- 优化提示,明确询问图像中的具体内容
- 使用高质量图像,避免过度压缩
- 测试不同的
temperature值找到最佳平衡点 - 考虑使用GPT-4o-vision专用模型
Q5: 如何有效测试和调试API调用?
A5: API调试最佳实践:
- 使用Postman等工具先测试原始HTTP请求
- 打印完整的请求和响应数据
- 实现详细的错误日志记录
- 创建专门的测试API密钥和环境
- 逐步构建复杂请求,确保每步都正常工作
【集成示例】将GPT-4o整合到现有系统中的最佳实践
将GPT-4o整合到现有系统中需要考虑多方面因素,以下是一些最佳实践:
1. 架构设计考虑
┌─────────────────┐ ┌───────────────┐ ┌────────────────┐
│ │ │ │ │ │
│ 客户端应用 │───→│ 中间层API │───→│ GPT-4o API │
│ (Web/移动) │←───│ (服务器) │←───│ (OpenAI) │
│ │ │ │ │ │
└─────────────────┘ └───────────────┘ └────────────────┘
- 实现中间层API:不直接从客户端调用OpenAI API,而是通过你的服务器
- 异步处理:对于耗时较长的请求,使用异步队列处理
- 缓存机制:为常见查询建立缓存,减少API调用
- 降级策略:当API不可用时,有备用方案
2. 安全性最佳实践
- 密钥管理:使用专门的密钥管理解决方案,如AWS KMS或HashiCorp Vault
- 输入验证:对所有用户输入进行严格验证,防止恶意内容
- 速率限制:实现速率限制和请求配额,防止滥用
- 内容过滤:添加内容审核层,过滤敏感或不适当内容
- 传输加密:确保所有API通信使用TLS/HTTPS
3. 性能优化建议
- 批处理请求:尽可能合并多个小请求为一个大请求
- 流式处理:对长文本生成使用流式API
- 预热缓存:对常见查询预生成响应
- 负载均衡:对大规模应用分散API调用负载
- 监控和警报:实施全面的API性能监控
【未来展望】GPT-4o API的发展趋势与未来功能
随着技术不断发展,GPT-4o API也在持续更新。以下是我们预期的未来发展方向:
1. 即将推出的新功能
根据OpenAI的路线图和行业趋势,我们可以期待以下功能:
- 增强的视频理解:完整视频内容分析和摘要
- 代码执行环境:直接在API中安全执行代码
- 多智能体对话:支持多个AI角色之间的交互
- 长期记忆机制:提供更持久的用户交互记忆
- 自定义知识库集成:更灵活地整合私有数据
2. 行业应用趋势
GPT-4o API正在以下领域产生革命性影响:
- 智能客服:全渠道、多模态客户支持系统
- 内容创作:自动生成高质量文章、视频脚本和营销材料
- 教育技术:个性化学习助手和自适应课程
- 医疗诊断辅助:帮助医生解读医学影像和病历
- 研发助手:加速科研文献分析和实验设计
3. 应对的挑战
随着这些发展,开发者需要应对以下挑战:
- 伦理与责任:确保AI应用符合伦理标准和规范
- 可解释性:提高AI决策过程的透明度
- 隐私保护:在利用强大功能的同时保护用户数据
- 模型偏见:识别和减轻可能的模型偏见
- 成本管理:随着应用规模扩大,有效控制API调用成本
【总结】掌握GPT-4o API的核心要点回顾
通过本文的详细指南,我们全面探讨了GPT-4o API的使用方法与最佳实践。让我们回顾核心要点:
- 多模态功能:GPT-4o集成了文本、图像、音频处理能力,实现真正的多模态AI体验
- 基础调用方法:掌握了Python、Node.js和HTTP直接请求的核心调用方式
- 高级技巧:学习了流式响应、函数调用和系统提示优化等高级用法
- 实战案例:通过文档分析、视频内容理解和语音助手三个实例掌握实际应用方法
- 成本优化:了解了如何使用laozhang.ai中转API降低调用成本
- 集成最佳实践:学习了安全、性能和架构设计方面的最佳实践
🌟 最终建议:在开始大规模应用前,建议先在小范围测试API性能和效果,逐步扩大使用规模,并密切关注成本和用户反馈。
希望这篇指南能帮助你快速掌握GPT-4o API的使用,构建出创新、实用的AI应用!如有问题或建议,欢迎在评论区交流讨论!
【更新日志】持续优化的见证
plaintext┌─ 更新记录 ───────────────────────────┐ │ 2025-03-10:首次发布完整API指南 │ │ 2025-03-15:更新laozhang.ai接入方法 │ └───────────────────────────────────────┘