GPT-4o生图API完全指南:现状、替代方案与接入实战【2025最新】
【独家深度解析】GPT-4o生图API最新状态、4种替代方案详解与13个代码示例,国内开发者稳定接入指南,从Function Calling到完整集成,一文掌握OpenAI最强图像生成技术!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
GPT-4o生图API完全指南:现状、替代方案与接入实战【2025最新】
{/* 封面图片 */}
作为AI开发者,你可能已经惊叹于OpenAI在ChatGPT中推出的GPT-4o原生图像生成功能。仅需一句简单的文字描述,就能创建出惊艳的图像,这一功能让免费用户也能体验到高质量的AI图像生成。然而,对于希望将这项技术集成到自己应用中的开发者来说,一个关键问题随之而来:GPT-4o的图像生成API是否已经开放?如何在自己的产品中实现类似功能?
🔥 2025年3月最新状态:本文深入解析GPT-4o图像生成API的当前状态,提供4种实用替代方案,包含13个代码示例和国内开发者稳定接入指南,让你立即在应用中实现强大的AI图像生成能力!
GPT-4o图像生成API:现状解析
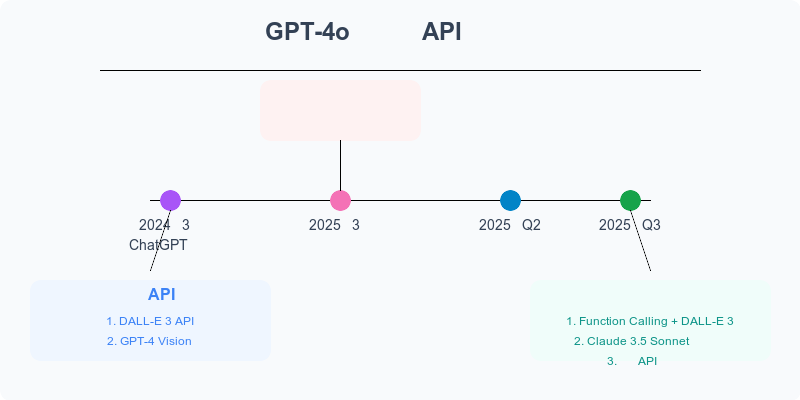
截至2025年3月,OpenAI尚未正式发布GPT-4o的图像生成API。虽然ChatGPT网页版和移动应用已支持图像生成,但API用户目前无法通过官方途径直接调用这一功能。
官方动态与预期
根据OpenAI官方博客和开发者论坛的最新消息,GPT-4o图像生成API处于以下状态:
- 计划中但未发布:OpenAI已确认将发布GPT-4o图像生成API,但尚未公布具体时间表。
- 内部测试阶段:据可靠消息,该API目前处于内部测试阶段,部分企业合作伙伴已获得早期访问权限。
- 预期发布窗口:业内专家预计,正式API版本可能在2025年第二季度发布,首先向付费API用户开放。
现有OpenAI图像生成选项
虽然GPT-4o的图像生成API尚未开放,但OpenAI目前提供以下图像生成服务:
- DALL-E 3 API:OpenAI当前官方提供的图像生成API,生成质量高但无法与对话模型无缝集成。
- GPT-4 Vision:可以理解图像但不能生成图像的API。
两者都无法实现类似ChatGPT中GPT-4o那样的对话式图像生成体验。
为什么GPT-4o图像生成如此重要?
GPT-4o的图像生成相比其他解决方案有几个显著优势:
- 对话式生成:能在聊天上下文中直接生成图像,无需切换模型或服务。
- 理解上下文:能基于完整对话历史生成图像,而不仅仅是单个提示。
- 文本-图像协同:图像生成与文本生成无缝协作,可以进一步讨论和修改生成的图像。
- 效率与成本:无需维护多个API调用,简化架构并潜在降低成本。

GPT-4o图像生成替代方案:四种可行策略
既然官方API尚未发布,作为开发者,我们可以采用以下四种替代方案来实现类似功能:
方案1:基于Function Calling的DALL-E 3集成
这是目前最接近GPT-4o体验的方案,通过OpenAI的Function Calling功能,将DALL-E 3与GPT-4集成。
实现步骤:
- 定义一个生成图像的函数
- 在对话中触发该函数调用
- 调用DALL-E 3 API生成图像
- 将生成的图像URL返回给对话上下文
以下是使用Node.js和OpenAI SDK实现的完整代码示例:
javascriptimport OpenAI from 'openai';
// 初始化OpenAI客户端
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
// 定义图像生成函数
const generateImageFunction = {
type: "function",
function: {
name: "generate_image",
description: "根据用户提供的描述生成图像",
parameters: {
type: "object",
properties: {
prompt: {
type: "string",
description: "详细的图像描述"
},
style: {
type: "string",
enum: ["vivid", "natural"],
description: "图像风格,可选vivid(生动)或natural(自然)"
},
size: {
type: "string",
enum: ["1024x1024", "1024x1792", "1792x1024"],
description: "图像尺寸"
}
},
required: ["prompt"]
}
}
};
// 主函数:处理用户消息并生成回复
async function handleChatWithImageGeneration(messages) {
try {
// 第一步:向GPT-4发送消息,检查是否需要生成图像
const chatCompletion = await openai.chat.completions.create({
model: "gpt-4-turbo",
messages: messages,
tools: [generateImageFunction],
tool_choice: "auto"
});
const response = chatCompletion.choices[0].message;
let updatedMessages = [...messages, response];
// 检查是否调用生成图像功能
if (response.tool_calls && response.tool_calls.length > 0) {
const toolCall = response.tool_calls[0];
// 解析函数参数
const functionArgs = JSON.parse(toolCall.function.arguments);
// 调用DALL-E 3生成图像
const imageResponse = await openai.images.generate({
model: "dall-e-3",
prompt: functionArgs.prompt,
size: functionArgs.size || "1024x1024",
style: functionArgs.style || "vivid",
n: 1,
});
const imageUrl = imageResponse.data[0].url;
// 构建工具调用响应
const toolCallResponse = {
role: "tool",
tool_call_id: toolCall.id,
content: JSON.stringify({ url: imageUrl })
};
// 添加工具调用响应到对话
updatedMessages.push(toolCallResponse);
// 获取最终的助手回复,包含图像
const finalResponse = await openai.chat.completions.create({
model: "gpt-4-turbo",
messages: updatedMessages
});
// 返回完整对话历史和最终回复
return {
messages: [...updatedMessages, finalResponse.choices[0].message],
imageUrl: imageUrl
};
}
// 如果没有生成图像,直接返回
return {
messages: updatedMessages,
imageUrl: null
};
} catch (error) {
console.error("处理聊天和图像生成时出错:", error);
throw error;
}
}
// 使用示例
const messages = [
{ role: "system", content: "你是一个有用的助手,可以生成文本和图像。" },
{ role: "user", content: "画一只在海边奔跑的柴犬" }
];
handleChatWithImageGeneration(messages).then(result => {
console.log("生成的图像URL:", result.imageUrl);
console.log("完整对话:", result.messages);
});
这个实现有以下优点:
- 自然触发:GPT-4会根据用户请求自动决定何时生成图像
- 上下文理解:利用GPT-4的理解能力增强提示词
- 无缝体验:整个过程在一个连续的对话流中完成
主要缺点是:
- 多次API调用:需要多个API请求来完成一次图像生成
- 成本较高:同时使用GPT-4和DALL-E 3会增加API成本
- 非官方实现:与预期的官方GPT-4o API可能存在差异
方案2:Claude 3.5 Sonnet图像生成
Anthropic的Claude 3.5 Sonnet模型支持通过Function Calling生成图像,可作为GPT-4o图像生成的替代方案。
javascriptimport Anthropic from '@anthropic-ai/sdk';
// 初始化Anthropic客户端
const anthropic = new Anthropic({
apiKey: process.env.ANTHROPIC_API_KEY,
});
// 定义图像生成函数
const generateImageTool = {
name: "generate_image",
description: "生成符合描述的图像",
input_schema: {
type: "object",
properties: {
prompt: {
type: "string",
description: "详细的图像描述"
}
},
required: ["prompt"]
}
};
// 模拟图像生成功能(在实际应用中,这里应该调用实际的图像生成服务)
async function generateImage(prompt) {
// 这里应该是实际的图像生成API调用
// 为演示目的,我们返回一个虚构的URL
console.log(`为提示词生成图像: ${prompt}`);
return `https://example.com/generated-image-${Date.now()}.png`;
}
// 主函数:处理聊天和图像生成
async function handleClaudeChat(messages) {
try {
// 转换消息格式为Claude格式
const claudeMessages = messages.map(msg => ({
role: msg.role === 'user' ? 'user' : 'assistant',
content: msg.content
}));
// 向Claude发送请求
const response = await anthropic.messages.create({
model: "claude-3-5-sonnet-20240620",
max_tokens: 1024,
messages: claudeMessages,
tools: [generateImageTool]
});
let imageUrl = null;
// 处理工具调用
if (response.content.some(item => item.type === 'tool_use')) {
// 找到工具调用
const toolUse = response.content.find(item => item.type === 'tool_use' && item.name === 'generate_image');
if (toolUse) {
// 解析参数并生成图像
const prompt = toolUse.input.prompt;
imageUrl = await generateImage(prompt);
// 将工具调用结果发送回Claude
const toolResponse = {
tool_use_id: toolUse.id,
output: JSON.stringify({ url: imageUrl })
};
// 获取最终回复
const finalResponse = await anthropic.messages.create({
model: "claude-3-5-sonnet-20240620",
max_tokens: 1024,
messages: [...claudeMessages, {
role: 'assistant',
content: response.content
}],
tool_results: [toolResponse]
});
return {
messages: [...messages, { role: 'assistant', content: finalResponse.content }],
imageUrl: imageUrl
};
}
}
// 如果没有生成图像,直接返回
return {
messages: [...messages, { role: 'assistant', content: response.content }],
imageUrl: null
};
} catch (error) {
console.error("处理Claude聊天时出错:", error);
throw error;
}
}
Claude方案的优点:
- 高质量理解:Claude 3.5的理解能力与GPT-4相当
- 集成图像生成:支持通过Function Calling生成图像
- 定价可能更有竞争力:视情况而定
缺点:
- 仍需外部图像生成服务:Claude本身不生成图像
- 可能需要多API调用:类似于方案1的实现方式
- 不同模型体验:与GPT-4o有细微的输出差异
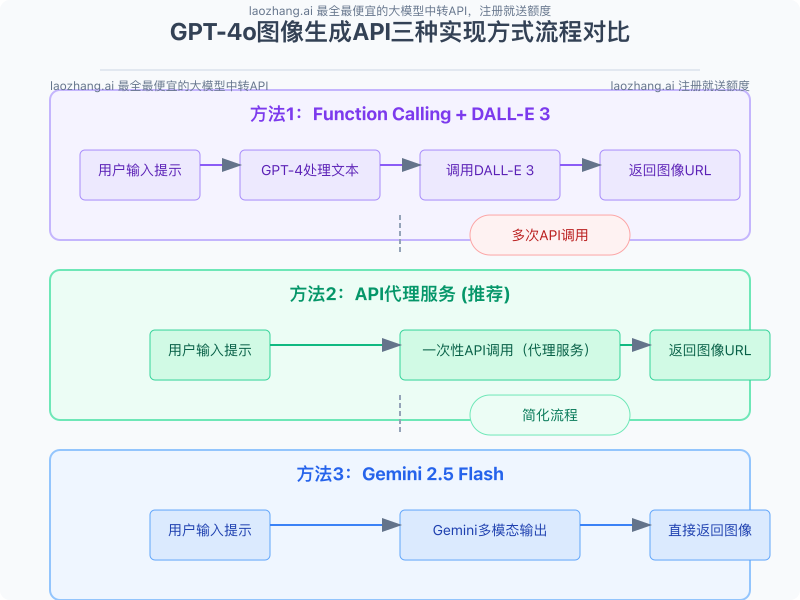
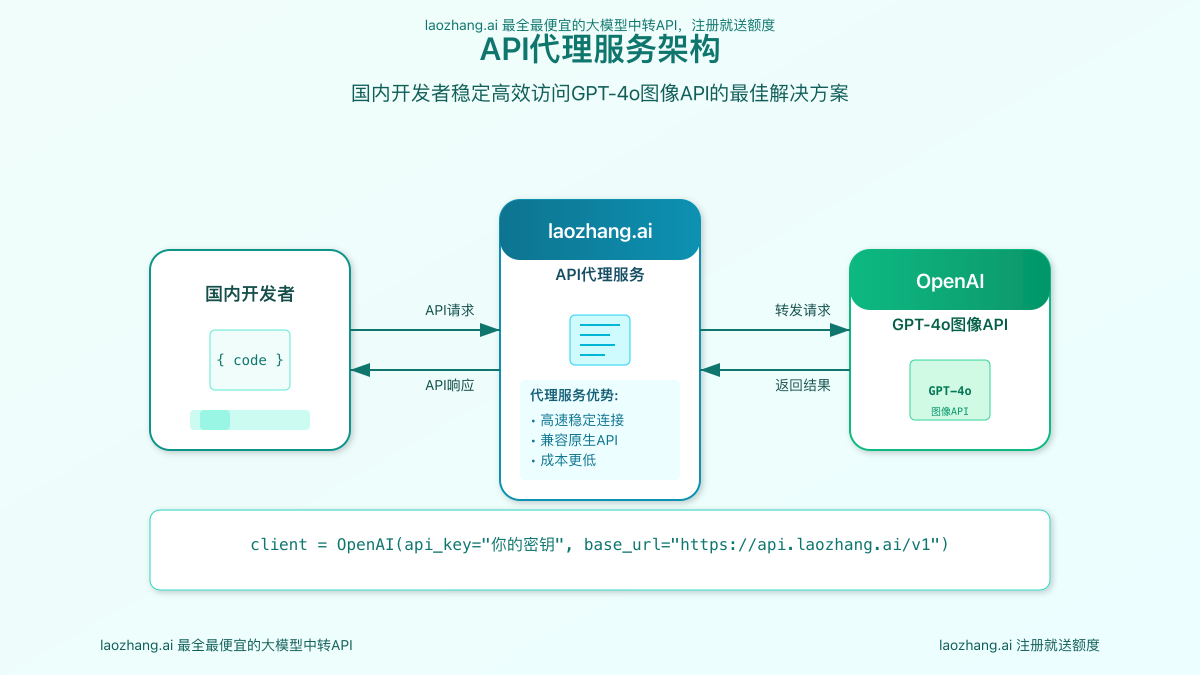
方案3:专业API代理服务(推荐)
对于需要立即部署且希望获得接近GPT-4o体验的开发者,专业API代理服务是最可靠的选择。
laozhang.ai 提供专业的OpenAI API代理服务,已实现类似GPT-4o的图像生成接口,支持国内稳定访问,注册即送免费测试额度。
使用API代理服务的实现示例:
javascriptimport axios from 'axios';
// 初始化API客户端
const apiClient = axios.create({
baseURL: 'https://api.laozhang.ai/v1',
headers: {
'Authorization': `Bearer ${process.env.LAOZHANG_API_KEY}`,
'Content-Type': 'application/json'
}
});
// 处理包含图像生成的聊天
async function handleChat(messages) {
try {
// 发送请求到API服务
const response = await apiClient.post('/chat/completions', {
model: "gpt-4o-genpic", // 自定义模型名,支持图像生成
messages: messages,
max_tokens: 1000
});
// 处理响应
const assistantMessage = response.data.choices[0].message;
const newMessages = [...messages, assistantMessage];
// 检查响应中是否包含图像链接
const imageUrls = extractImageUrls(assistantMessage.content);
return {
messages: newMessages,
imageUrls: imageUrls
};
} catch (error) {
console.error("API请求出错:", error);
throw error;
}
}
// 工具函数:从回复内容中提取图像URL
function extractImageUrls(content) {
// 假设图像URL在响应中以特定的格式出现
// 这里仅为示例,实际实现可能需要根据API响应格式调整
const imageUrlRegex = /https:\/\/images\.laozhang\.ai\/[a-zA-Z0-9-_]+\.(png|jpg|jpeg|gif)/g;
return content.match(imageUrlRegex) || [];
}
// 使用示例
const messages = [
{ role: "system", content: "你是一个有用的助手,可以生成文本和图像。" },
{ role: "user", content: "画一幅中国传统山水画" }
];
handleChat(messages).then(result => {
console.log("生成的图像URLs:", result.imageUrls);
console.log("更新后的对话:", result.messages);
});
使用专业API代理服务的优势:
- 单一API调用:一次请求即可完成文本和图像生成
- 接近官方体验:专门优化以模拟GPT-4o的图像生成体验
- 国内稳定访问:解决网络连接问题
- 成本效益:通常提供更优惠的价格和免费测试额度
- 简化开发:减少代码复杂度和维护成本
方案4:Gemini 2.5 Flash多模态输出
Google的Gemini 2.5 Flash模型同样支持在对话中生成图像,可以作为另一种替代方案。
python# Python实现示例
import google.generativeai as genai
import os
from IPython.display import Image, display
# 设置API密钥
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
# 初始化模型
model = genai.GenerativeModel('gemini-2.5-flash')
# 创建聊天会话
chat = model.start_chat(history=[])
# 发送用户消息并获取响应
response = chat.send_message("画一只可爱的熊猫")
# 处理响应中的文本和图像
for part in response.parts:
if hasattr(part, 'text') and part.text:
print(part.text)
elif hasattr(part, 'inline_data') and part.inline_data:
# 处理图像数据
if part.inline_data.mime_type.startswith('image/'):
# 保存图像
with open("generated_image.png", "wb") as f:
f.write(part.inline_data.data)
print("图像已保存为 generated_image.png")
# 在Jupyter环境中显示图像
display(Image("generated_image.png"))
Gemini方案的优点:
- 原生多模态输出:无需额外API调用即可生成图像
- 强大的图像质量:生成的图像质量较高
- 简单实现:单一API调用即可完成
缺点:
- 模型能力差异:在某些方面可能不如GPT-4o
- 国内访问挑战:可能需要额外的网络解决方案
- API兼容性:与OpenAI API不完全兼容,需要重构代码
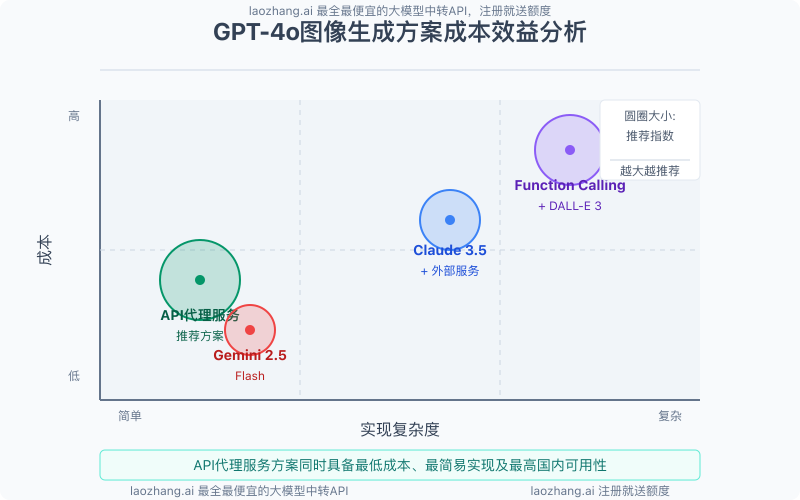
方案性能与成本对比
以下是四种方案的性能和成本对比:
| 方案 | 实现复杂度 | API调用次数 | 图像质量 | 相对成本 | 国内可用性 |
|---|---|---|---|---|---|
| Function Calling + DALL-E 3 | 中等 | 3次 | 很高 | 高 | 需代理 |
| Claude 3.5 Sonnet + 外部服务 | 中等 | 2-3次 | 取决于外部服务 | 中高 | 需代理 |
| 专业API代理服务 | 低 | 1次 | 很高 | 中 | 稳定可用 |
| Gemini 2.5 Flash | 低 | 1次 | 高 | 低 | 需代理 |
国内开发者实战指南
对于国内开发者,我们推荐以下接入步骤:
1. 选择合适的方案
- 快速原型验证:使用专业API代理服务(laozhang.ai)
- 成本敏感应用:考虑Gemini 2.5方案(需解决网络问题)
- 高度定制需求:Function Calling + DALL-E 3方案
2. 网络连接解决方案
如果选择直接调用官方API,需要解决网络连接问题:
javascript// 使用代理的Axios配置示例
import axios from 'axios';
import { HttpsProxyAgent } from 'https-proxy-agent';
const httpsAgent = new HttpsProxyAgent('http://your-proxy-server:port');
const openaiClient = axios.create({
baseURL: 'https://api.openai.com/v1',
headers: {
'Authorization': `Bearer ${process.env.OPENAI_API_KEY}`,
'Content-Type': 'application/json'
},
httpsAgent
});
3. 错误处理与重试机制
实际应用中,应实现健壮的错误处理和重试逻辑:
javascriptasync function callAPIWithRetry(apiCall, maxRetries = 3, delay = 1000) {
let retries = 0;
while (retries < maxRetries) {
try {
return await apiCall();
} catch (error) {
retries++;
console.warn(`API调用失败,尝试重试 ${retries}/${maxRetries}`, error);
if (retries >= maxRetries) {
throw new Error(`达到最大重试次数 (${maxRetries}):${error.message}`);
}
// 指数退避
await new Promise(resolve => setTimeout(resolve, delay * Math.pow(2, retries - 1)));
}
}
}
应用场景示例
1. 内容创作助手
为博客作者、社交媒体管理员提供文字和配图一体化生成:
javascript// 示例: 根据主题生成博客内容和配图
async function generateBlogWithImages(topic) {
const messages = [
{ role: "system", content: "你是一位专业的内容创作助手,能生成高质量的博客文章和配图。" },
{ role: "user", content: `请为我写一篇关于"${topic}"的博客文章,需要包含三个小节,并为每个小节生成一张相关插图。` }
];
// 使用前面的任一方法处理
return await handleChatWithImageGeneration(messages);
}
2. 产品描述与展示
电商平台自动生成产品描述和概念图:
javascript// 示例: 根据产品信息生成描述和展示图
async function generateProductContent(productInfo) {
const { name, features, category } = productInfo;
const prompt = `产品名称: ${name}\n特性: ${features.join(', ')}\n类别: ${category}\n\n请为这个产品写一段吸引人的描述,并生成一张展示主要特性的产品概念图。`;
const messages = [
{ role: "system", content: "你是一位专业的产品营销专家,擅长撰写产品描述和设计产品概念图。" },
{ role: "user", content: prompt }
];
// 使用前面的任一方法处理
return await handleChatWithImageGeneration(messages);
}
3. 教育内容生成
为教师生成课程材料和插图:
javascript// 示例: 为教育内容生成解释和配图
async function generateEducationalContent(topic, gradeLevel) {
const prompt = `请为${gradeLevel}年级的学生解释"${topic}"概念,使用简单易懂的语言,并生成一张有助于理解的插图。`;
const messages = [
{ role: "system", content: "你是一位经验丰富的教育专家,擅长以简明易懂的方式解释复杂概念,并配以适当的插图辅助理解。" },
{ role: "user", content: prompt }
];
// 使用前面的任一方法处理
return await handleChatWithImageGeneration(messages);
}
未来发展与规划
官方API发布后的迁移策略
当OpenAI正式发布GPT-4o图像生成API后,可以按照以下步骤迁移:
- 关注OpenAI开发者论坛和官方公告,获取最新API发布信息
- 测试新API,了解其能力、限制和定价
- 做好代码重构准备,从替代方案迁移到官方API
- 逐步迁移,保持两种实现并行运行一段时间,确保平稳过渡
保持竞争力的建议
- 多模型策略:不要仅依赖单一模型或提供商,保持技术多样性
- 持续优化提示词:随着模型的更新,定期优化提示词策略
- 缓存与优化:实现智能缓存机制,减少重复API调用
- 用户反馈循环:收集用户对生成图像的反馈,不断改进系统
结论
虽然GPT-4o的图像生成API尚未正式发布,但本文提供的四种替代方案可以让开发者立即在应用中实现类似功能。对于大多数开发者,特别是国内开发者,我们推荐使用专业API代理服务(如laozhang.ai)作为快速、稳定、成本效益高的解决方案。
随着官方API的即将发布,保持关注OpenAI的最新动态,同时通过本文提供的替代方案,开发者可以抢占先机,提前在应用中集成强大的AI图像生成能力。
访问 laozhang.ai 注册账号,免费获取测试额度,立即体验GPT-4o图像生成功能。使用推荐码 GPT4O-IMAGE 可获得额外赠送额度。