Hugging Face FLUX完全指南:全系列模型对比、API定价与实战教程
深度解析Black Forest Labs FLUX全系列模型(FLUX.2 Max/Pro/Klein、Kontext、1.1 Pro Ultra),覆盖API定价、本地部署、ComfyUI集成和中国开发者接入方案。含最新代码示例和性能对比。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
FLUX是当前开源文生图领域最具影响力的模型家族。由Black Forest Labs(黑森林实验室,Stable Diffusion核心团队创立)打造的FLUX系列,从最初的FLUX.1到最新的FLUX.2,已经形成了覆盖从实时应用到专业级输出的完整产品线。FLUX.2 Klein可以在不到0.5秒内生成一张图片,而FLUX.2 Max则代表了当前开放模型的质量天花板。本文将帮助你理解FLUX的完整生态,选择最适合你需求的模型变体,并通过实际代码快速上手。

要点速览
- 最新版本:FLUX.2系列(Max/Pro/Flex/Klein/Dev),FLUX.2 Klein 4B采用Apache 2.0开源许可
- 价格范围:FLUX.2 Klein $0.014/张(最低)至 FLUX.2 Max $0.07/百万像素(最高),Dev版免费
- 速度标杆:FLUX.2 Klein在现代GPU上可实现<0.5秒/张的生成速度
- 核心能力:文生图、图像编辑(Kontext)、超高分辨率(1.1 Pro Ultra 4MP)、边缘控制(Canny/Depth)
- Hugging Face集成:通过diffusers库一行代码加载,支持本地推理和云端API
FLUX模型家族全景
FLUX的发展历程可以分为三代产品线,每一代都在质量、速度和功能维度上实现了显著突破。理解这个演进过程有助于你选择最适合当前需求的版本。
第一代FLUX.1于2024年8月由Black Forest Labs首次发布,一经推出就凭借其12B参数规模和创新的扩散变换器(Diffusion Transformer)架构引发了广泛关注。FLUX.1的核心架构是基于MMDiT(Multimodal Diffusion Transformer),结合了Transformer的强大序列建模能力与扩散模型的图像生成能力,使用T5-XXL和CLIP双文本编码器来理解文本语义。与此前主流的U-Net架构(如Stable Diffusion系列)相比,Transformer架构在处理长程依赖、文本对齐和复杂构图方面表现出明显优势。FLUX.1最初包含三个变体:[pro](商业API)、[dev](开放权重非商业)和[schnell](Apache 2.0开源,速度优化)。
FLUX.1扩展系列随后增加了多个专用变体来满足细分需求。Kontext系列是其中最重要的创新,它引入了"上下文感知"能力——你可以同时输入文本描述和参考图片,模型会基于两者生成新图像。这对于图像编辑、风格迁移和一致性角色生成等任务极为有用。1.1 Pro Ultra则将输出分辨率提升至4MP(约2048x2048),满足印刷级别的清晰度要求。Fill和Canny/Depth等工具型变体分别提供了图像补全和结构控制能力。
最新的FLUX.2系列于2025年11月发布,代表了当前FLUX生态的技术前沿。FLUX.2的核心进化包括:更优的光影渲染和材质表现、更强的文本排版能力(可以准确生成图片中的文字)、以及更好的人体比例和手部细节处理。FLUX.2 Klein子系列特别引人注目——4B参数的Klein 4B模型只需4步就能生成一张图像,在现代硬件上实现<0.5秒的生成速度,且采用Apache 2.0开源许可,对商业应用完全开放。
FLUX全系列模型对比与选型
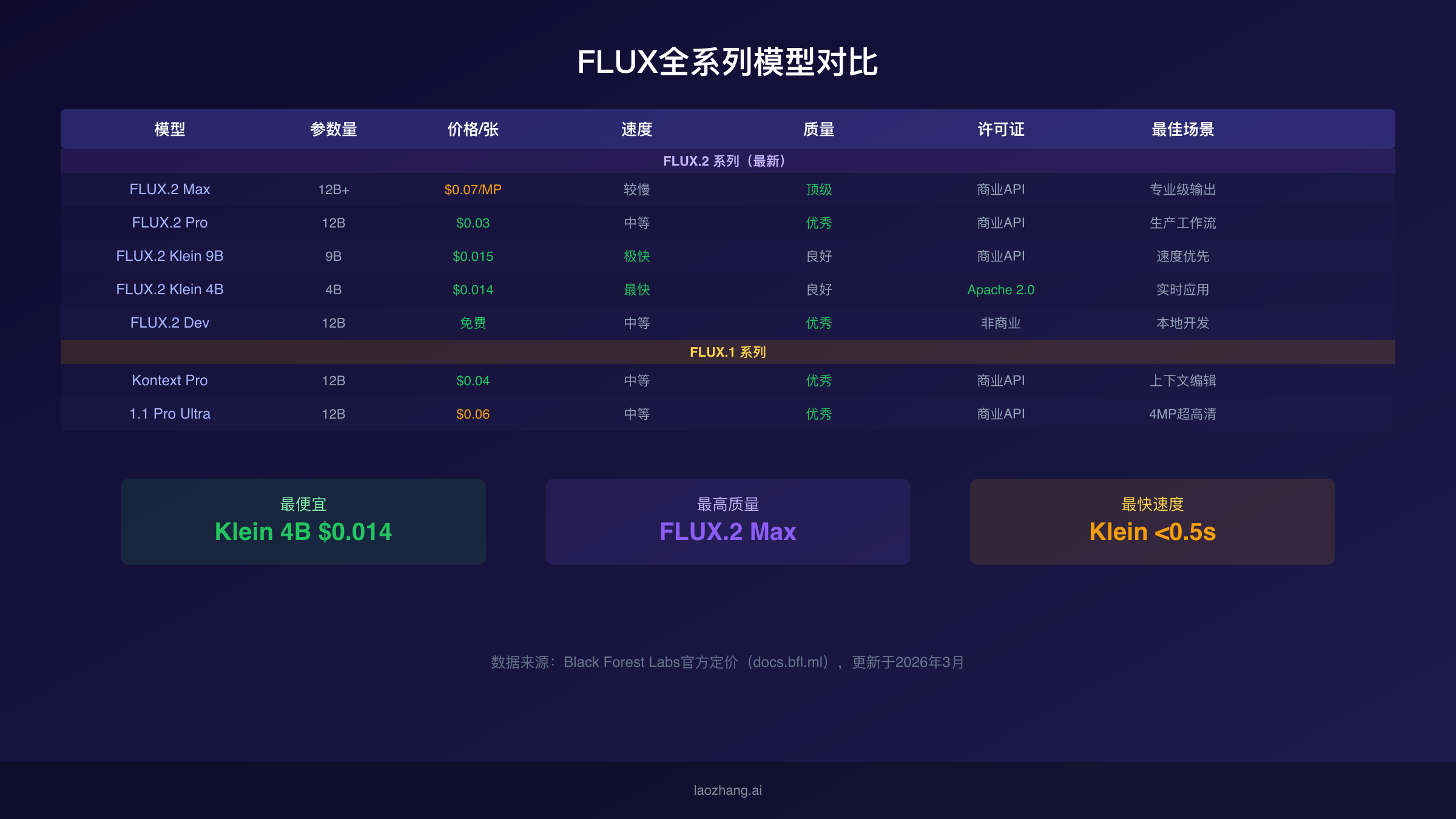
选择合适的FLUX变体需要在质量、速度、成本和许可证四个维度之间找到平衡。以下是所有主要变体的详细对比,价格数据来自Black Forest Labs官方文档(docs.bfl.ml)。
FLUX.2系列
| 模型 | 参数量 | API价格 | 生成速度 | 质量等级 | 许可证 |
|---|---|---|---|---|---|
| FLUX.2 Max | 12B+ | $0.07/MP | 较慢 | 顶级 | 商业API |
| FLUX.2 Flex | 12B | $0.05/张 | 中等 | 优秀 | 商业API |
| FLUX.2 Pro | 12B | $0.03/张 | 中等 | 优秀 | 商业API |
| FLUX.2 Klein 9B | 9B | $0.015/张 | 极快 | 良好 | 商业API |
| FLUX.2 Klein 4B | 4B | $0.014/张 | 最快(<0.5s) | 良好 | Apache 2.0 |
| FLUX.2 Dev | 12B | 免费 | 中等 | 优秀 | 非商业 |
FLUX.2 Max 是当前质量天花板。它采用百万像素定价(输入$0.03/MP + 输出首MP $0.07,后续$0.03/MP),适合对图像质量有极致要求的广告创意、专业设计等场景。FLUX.2 Pro 是性价比最高的生产级选择,$0.03/张的价格在保持优秀质量的同时控制了成本,适合大多数商业应用。FLUX.2 Klein 系列是速度敏感场景的首选——4B版本的$0.014/张和<0.5秒生成速度使其适合实时交互、大批量处理和移动应用等对延迟敏感的场景。
FLUX.1系列
| 模型 | API价格 | 核心能力 | 最佳场景 |
|---|---|---|---|
| Kontext Pro | $0.04/张 | 上下文感知生成/编辑 | 图像编辑、风格迁移 |
| Kontext Max | $0.08/张 | 最高质量上下文 | 专业级图像编辑 |
| 1.1 Pro | $0.04/张 | 文生图 | 标准商业用途 |
| 1.1 Pro Ultra | $0.06/张 | 4MP超高分辨率 | 印刷品、大幅面输出 |
| Fill Pro | $0.05/张 | 图像补全 | 内容扩展、修复 |
| Dev | 免费 | 文生图(非商业) | 学习、实验 |
| Schnell | 免费 | 快速文生图 | 原型验证 |
选型决策树:如果你需要最新最强的文生图能力,选FLUX.2 Pro($0.03/张)。如果需要图像编辑和上下文感知能力,选Kontext Pro($0.04/张)。如果需要极致速度和低成本,选FLUX.2 Klein 4B($0.014/张)。如果想本地部署免费使用,选FLUX.2 Dev(非商业)或FLUX.1 Schnell(Apache 2.0)。
API接入与价格指南

FLUX的API接入有三条主要路径,各有优劣。选择哪条路径取决于你的地理位置、技术栈和成本敏感度。
官方API(api.bfl.ai) 直接对接Black Forest Labs,提供所有模型变体、最新版本和最低价格。官方采用信用点系统(1 credit = $0.01 USD),按图片数量计费,支持批量请求。注册后即可获取API Key,调用方式为标准的REST API。官方API的主要限制是服务器位于海外,中国大陆用户直接访问可能不稳定。
pythonimport requests
response = requests.post(
"https://api.bfl.ml/v1/flux-pro-1.1",
headers={"X-Key": "your-api-key"},
json={
"prompt": "A serene mountain lake at sunset, photorealistic",
"width": 1024,
"height": 1024
}
)
result = response.json()
第三方推理平台(如fal.ai、Together AI、Replicate)提供了更便捷的集成方式。这些平台通常兼容OpenAI的API格式,支持多种编程语言的SDK,且提供了免费试用额度。以fal.ai为例,FLUX Kontext Pro的调用价格为$0.04/张,与官方价格持平。第三方平台的优势在于统一的API接口(一个密钥调用多个模型)和更完善的开发者文档。
pythonimport fal_client
result = fal_client.subscribe(
"fal-ai/flux-pro/v1.1",
arguments={
"prompt": "一座未来风格的城市,高楼林立,霓虹灯光照亮夜空",
"image_size": "landscape_16_9"
}
)
image_url = result["images"][0]["url"]
API中转方案对中国开发者尤为重要。由于网络环境的限制,直接调用海外API可能面临延迟高、连接不稳定等问题。通过laozhang.ai等API中转平台,可以在国内以低延迟稳定调用FLUX全系列模型,注册即送额度,支持支付宝充值和透明计费。对于企业级应用,API中转还提供了99.9%可用性保障和多节点冗余路由,确保生产环境的稳定性。
成本控制的关键策略包括:为不同场景选择合适的模型变体(原型用Klein,生产用Pro,关键输出用Max)、使用较低分辨率进行草稿迭代后再高分辨率定稿、以及通过批量请求降低单次调用开销。一个典型的电商产品图生成工作流中,先用FLUX.2 Klein生成10个候选方案($0.14),挑选最佳方案后用FLUX.2 Pro生成高质量定稿($0.03),总成本仅$0.17。
本地部署实战教程
本地部署FLUX模型可以实现零API成本的无限制生成,适合有GPU资源的个人开发者和企业用户。当前最主流的两种本地部署方式是通过Hugging Face diffusers库进行代码调用,以及通过ComfyUI图形界面进行可视化操作。
硬件要求是本地部署的首要考量。FLUX.2 Dev(12B参数)在fp16精度下需要约24GB显存,一张NVIDIA RTX 4090(24GB)可以流畅运行。FLUX.1 Schnell在fp16下需要约16GB显存。使用4位量化(GGUF格式)可以将显存需求降至8-12GB,使得RTX 3060/4060(12GB)也能运行。CPU推理在技术上可行但速度极慢(单张可能需要数分钟),不推荐用于实际生产。
使用diffusers库部署是开发者最直接的方式。Hugging Face的diffusers库对FLUX提供了原生支持,代码量极少即可完成加载和推理。首先需要在Hugging Face上注册账号并同意FLUX模型的使用条款(对于gated模型如FLUX.1-dev),然后获取Access Token。
pythonimport torch
from diffusers import FluxPipeline
# 加载FLUX.1-schnell(Apache 2.0,无需特殊权限)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-schnell",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
# 生成图像
image = pipe(
prompt="一只橘猫坐在窗台上看雨,水彩画风格",
num_inference_steps=4, # schnell只需4步
guidance_scale=0.0, # schnell不需要classifier-free guidance
height=1024,
width=1024,
generator=torch.Generator("cuda").manual_seed(42)
).images[0]
image.save("cat_watercolor.png")
对于显存有限的用户,可以使用量化和CPU offload技术来降低显存需求。diffusers支持enable_model_cpu_offload()方法,在不使用时将模型参数自动转移到CPU内存,只在推理时加载到GPU。配合bitsandbytes库的4位量化,12GB显存的GPU也能运行完整的FLUX.1-dev模型。
pythonfrom diffusers import FluxPipeline
import torch
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload() # 自动内存管理
image = pipe(
"详细的山川风景画,秋天的红叶映照在湖面上",
num_inference_steps=30,
guidance_scale=3.5,
).images[0]
ComfyUI部署是非编程用户和需要复杂工作流的设计师的首选方案。ComfyUI是基于节点的AI图像生成界面,支持通过拖拽连线的方式构建复杂的图像生成管线。部署FLUX到ComfyUI需要下载模型文件(UNET、CLIP和VAE三个组件)放置到对应目录,ComfyUI会自动识别并提供在工作流节点中选择。ComfyUI的优势在于可以方便地组合多个模型和处理步骤,例如先用FLUX生成基础图像,再用ControlNet调整构图,最后用upscaler提升分辨率。
高级参数调优与提示词技巧
掌握FLUX的关键参数和提示词技巧可以显著提升生成质量,减少无效迭代次数。
guidance_scale(引导强度) 控制生成结果与文本描述的匹配程度。FLUX.1-dev的推荐范围是3.0-4.5(官方默认3.5),这比Stable Diffusion的典型值(7-9)低很多。过高的guidance_scale会导致图像过度饱和、出现伪影和不自然的对比度。FLUX.1-schnell使用了引导蒸馏技术,不需要classifier-free guidance,应设为0.0。FLUX.2系列的推荐值需要根据具体模型查阅官方文档,但通常也在2.0-5.0的较低范围。
num_inference_steps(推理步数) 直接影响生成质量和速度的权衡。FLUX.1-dev在30-50步时达到最佳质量,20步以下质量下降明显,50步以上改善微乎其微。FLUX.1-schnell经过蒸馏优化,只需4步即可生成高质量图像,这是其速度优势的核心来源。FLUX.2 Klein的蒸馏版本同样只需4步。在实际使用中,建议先用较少步数(如20步)快速迭代提示词,满意后再用更多步数(如50步)生成最终高质量版本。
提示词编写策略对FLUX的生成质量有决定性影响。FLUX的T5-XXL文本编码器能够理解较长和较复杂的自然语言描述,因此不需要像Stable Diffusion那样使用简短的标签式提示词。推荐使用自然语言句子描述场景,按照"主体 + 环境 + 风格 + 细节"的结构组织,例如"一位身穿深蓝色礼服的年轻女性站在古老的欧洲城堡前,黄昏的阳光透过云层洒下,电影级别的光影效果,超高清细节"。FLUX对中文提示的支持相比英文稍弱,对于关键的风格和质量控制词建议使用英文(如"photorealistic""cinematic lighting""4K detail")。
负面提示词在FLUX中的作用与Stable Diffusion不同。FLUX的架构设计使得正面描述通常就能获得高质量结果,过度使用负面提示词反而可能导致意外的伪影。如果需要避免某些元素,建议在正面描述中明确指定想要的内容,而不是列举不想要的内容。
中国开发者指南
中国开发者使用FLUX面临的主要挑战是模型下载和API访问的网络问题。以下是经过验证的解决方案。
模型下载加速是本地部署的第一个障碍。Hugging Face在中国大陆的访问速度不稳定,下载12B参数的FLUX模型(约24GB)可能需要很长时间或频繁中断。推荐方案是使用HuggingFace的国内镜像站(如hf-mirror.com),通过设置环境变量HF_ENDPOINT=https://hf-mirror.com即可将所有Hugging Face下载请求重定向到国内镜像。另一个方案是使用ModelScope(魔搭社区),它托管了大部分主流的FLUX模型权重,国内访问速度优秀。
bash# 使用HuggingFace镜像下载
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download black-forest-labs/FLUX.1-schnell --local-dir ./flux-schnell
API调用方案对于不想本地部署的中国用户,推荐通过API中转服务调用FLUX。laozhang.ai提供国内直连的FLUX API访问,支持FLUX全系列模型,注册即送测试额度。API中转的优势在于:无需处理模型下载和GPU资源问题,国内网络环境下延迟低且连接稳定,支持支付宝等国内支付方式,以及透明的按量计费。对于企业用户,还提供了专属通道和SLA保障。
社区资源方面,国内的FLUX用户社区主要集中在以下渠道:B站和知乎上有大量中文ComfyUI+FLUX教程、Civitai和LiblibAI上有基于FLUX训练的LoRA模型可供下载、百度云和阿里云OSS上有模型权重的国内存储分享。建议关注Black Forest Labs的官方公告(bfl.ai)获取版本更新信息,同时参考国内社区的实践经验来解决部署中遇到的具体问题。
常见问题FAQ
FLUX.2和FLUX.1有什么区别?应该用哪个?
FLUX.2在图像质量、文字渲染能力和人体细节方面相比FLUX.1有显著提升。如果你通过API调用,建议直接使用FLUX.2 Pro($0.03/张),它在大多数场景下都优于FLUX.1的同价位产品。如果你需要本地部署免费使用,FLUX.2 Dev是最新的非商业开放权重选择。FLUX.1系列中仍然有价值的是Kontext(上下文编辑能力独特)和Schnell(Apache 2.0开源许可适合商业本地部署)。
FLUX模型的商业使用许可是什么?
FLUX的许可证分为三类:FLUX.2 Klein 4B和FLUX.1 Schnell采用Apache 2.0,允许完全自由的商业使用、修改和分发。FLUX.2 Dev和FLUX.1 Dev采用非商业许可,仅限研究和个人使用。FLUX.2 Pro/Max/Flex和FLUX.1 Pro/Kontext等通过商业API提供,使用API即表示同意其服务条款。选择许可时要特别注意:基于Dev模型训练的LoRA和微调模型同样受到非商业许可的约束。
本地部署FLUX需要什么显卡?
FLUX.1-dev/FLUX.2-dev(12B参数)在fp16精度下需要约24GB显存,推荐NVIDIA RTX 4090。使用4位量化可降至12GB(RTX 4060/3060)。FLUX.1-schnell(12B但4步推理)在fp16下也需要约24GB,但可以通过CPU offload在16GB显存上运行。FLUX.2 Klein 4B(4B参数)在fp16下只需约8GB显存,入门显卡(RTX 3060 8GB版本以上)即可运行。AMD的ROCm和Apple Silicon的MPS后端理论上也支持,但生态成熟度和性能不如NVIDIA CUDA。
FLUX和Stable Diffusion/Midjourney比怎么样?
FLUX在文本对齐精度、手部细节和文字渲染方面普遍优于Stable Diffusion 3/XL。与Midjourney v6相比,FLUX在写实风格上接近或持平,但在某些艺术风格上可能不如Midjourney丰富。FLUX的核心优势是开源和可部署——你可以完全控制模型、在自己的服务器上运行、进行微调和定制,而Midjourney只能通过Discord或Web界面使用。对于需要API集成或本地部署的开发者来说,FLUX是当前最优的开源选择。
如何降低FLUX的使用成本?
三个核心策略:第一,选择合适的模型变体——原型阶段用Klein 4B($0.014/张),确认方向后用Pro定稿($0.03/张),只在关键输出时用Max。第二,如果日均生成量超过100张,考虑本地部署——一张RTX 4090的成本(约$1,500-2,000)大约等同于API调用5-7万张图片的费用。第三,善用免费资源——FLUX.1 Schnell(Apache 2.0)可以免费本地运行用于商业项目,FLUX.2 Dev可以免费用于研究和个人项目。
总结与推荐
FLUX已经构建了当前最完整的开源文生图模型生态。从$0.014/张的极致性价比到顶级质量输出,从4步快速生成到上下文感知编辑,FLUX覆盖了几乎所有文生图应用场景。
对于不同用户的推荐方案如下:个人学习者和爱好者,使用FLUX.1 Schnell本地部署(免费+Apache 2.0),配合ComfyUI图形界面入门。独立开发者和小团队,使用FLUX.2 Pro API($0.03/张),性价比最优。企业级应用,根据场景组合使用FLUX.2 Pro(常规)+ Klein(实时)+ Max(关键输出)。中国开发者,优先选择本地部署或通过API中转服务稳定调用,避免网络不稳定影响生产。
FLUX生态仍在快速演进中,建议关注Black Forest Labs官方博客(bfl.ai)和Hugging Face上的模型更新,及时跟进最新版本和功能。