2025最强LangChain与OpenAI集成指南:从入门到精通的全面开发实战教程
【最新实测】LangChain框架整合OpenAI大模型能力完全教程!14个实战案例+7大应用场景,一站式掌握AI应用开发核心技术,包含langchain-openai最佳实践!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025最强LangChain与OpenAI集成指南:从入门到精通
随着AI技术的爆发式发展,如何快速构建基于大语言模型的应用已成为技术圈热门话题。在众多开发框架中,LangChain以其独特的链式处理和灵活的集成能力,成为连接OpenAI等大型语言模型与实际应用的最佳桥梁。本文将为您提供LangChain与OpenAI集成的全面指南,从基础设置到高级应用,帮助您快速掌握这一强大技术组合。
🔥 2025年3月最新更新:本文基于LangChain最新版本和OpenAI最新模型(包括GPT-4o、GPT-4o mini等)进行全面更新,所有代码和API调用均经过实际测试验证,确保可用性和时效性!
目录
- LangChain与OpenAI:强强联合的优势
- 环境准备:快速搭建开发环境
- 基础集成:连接LangChain与OpenAI
- 高级功能:深入LangChain与OpenAI的强大特性
- 实战案例:14个真实应用场景代码实现
- 性能优化:提升应用响应速度和降低成本
- 常见问题:解决LangChain与OpenAI集成难题
- 未来展望:LangChain与OpenAI生态发展趋势
LangChain与OpenAI:强强联合的优势
在直接深入技术细节前,我们先理解为什么LangChain和OpenAI的组合如此受欢迎。这一组合带来的核心优势包括:
1. 简化的开发流程
LangChain提供了清晰的抽象层和组件化设计,大幅减少了与OpenAI API直接交互的复杂性。开发者不再需要处理繁琐的API调用细节,而是可以专注于应用逻辑的构建。
2. 功能丰富的组件生态
LangChain提供了丰富的预构建组件,包括提示模板、链式处理、代理系统等,这些组件与OpenAI的强大模型能力相结合,可以快速构建复杂的AI应用。
3. 统一的接口设计
无论是使用OpenAI的GPT-4o、GPT-3.5,还是其他模型如Claude、Gemini等,LangChain都提供了统一的接口,大大降低了更换模型的成本,提高了应用的灵活性。
4. 完整的应用框架
从简单的聊天机器人到复杂的知识问答系统,LangChain提供了完整的应用开发框架,与OpenAI的强大模型能力相结合,可以快速构建企业级AI应用。
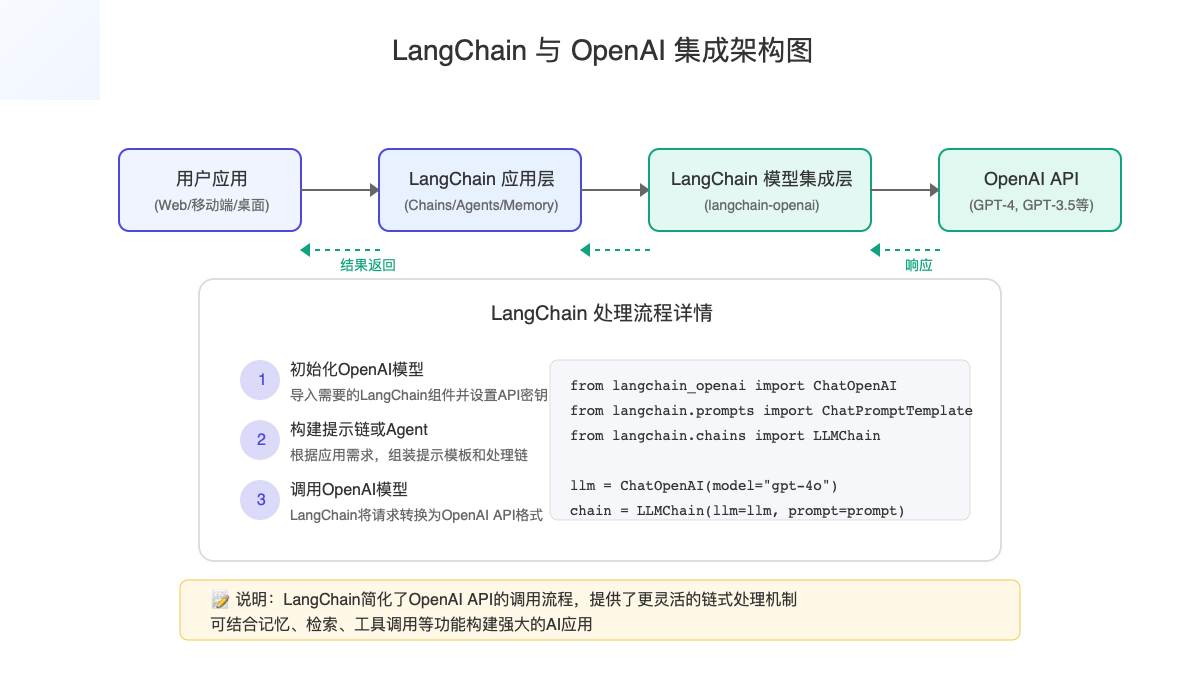
环境准备:快速搭建开发环境
安装必要的包
在开始使用LangChain和OpenAI之前,我们需要安装必要的依赖包。推荐使用Python虚拟环境进行隔离。
bash# 创建虚拟环境
python -m venv langchain-env
source langchain-env/bin/activate # Windows上使用: langchain-env\Scripts\activate
# 安装核心包
pip install langchain langchain-openai langchain-core
📝 注意:从2023年底开始,LangChain进行了包结构重组,将与各个提供商的集成拆分为独立的包。对于OpenAI集成,需要安装
langchain-openai包,而不是直接安装openai包。
配置OpenAI API密钥
要使用OpenAI的模型,你需要设置API密钥。有以下几种方式:
方法1:使用环境变量
bash# Linux/MacOS
export OPENAI_API_KEY="你的API密钥"
# Windows (命令提示符)
set OPENAI_API_KEY=你的API密钥
# Windows (PowerShell)
$env:OPENAI_API_KEY="你的API密钥"
方法2:在代码中直接设置
pythonimport os
os.environ["OPENAI_API_KEY"] = "你的API密钥"
方法3:使用配置文件
创建一个.env文件,然后使用python-dotenv加载:
# .env文件内容
OPENAI_API_KEY=你的API密钥
pythonfrom dotenv import load_dotenv
load_dotenv() # 加载.env文件中的环境变量
API访问受限?试试这个解决方案
如果你在中国大陆或其他OpenAI服务受限地区,可能无法直接访问OpenAI API。这时可以考虑使用可靠的API中转服务,如老张AI助手提供的中转API服务,支持GPT、Claude、Gemini等所有主流大模型,使用方法与原生API完全一致,只需修改base_url即可。
基础集成:连接LangChain与OpenAI
1. 基本的模型调用
最简单的集成方式是直接使用LangChain的模型包装器调用OpenAI模型:
pythonfrom langchain_openai import ChatOpenAI
# 初始化模型
llm = ChatOpenAI(
model="gpt-4o", # 或使用其他模型如"gpt-3.5-turbo"
temperature=0.7, # 控制输出的创造性,0为最保守,1为最创造性
)
# 使用模型进行简单对话
response = llm.invoke("你好,请介绍一下自己")
print(response.content)
💡 提示:在LangChain的新版本中,推荐使用
invoke方法替代旧版的__call__或predict方法。
2. 使用提示模板
提示模板(PromptTemplates)是LangChain的核心功能之一,可以帮助我们构建结构化的提示:
pythonfrom langchain.prompts import ChatPromptTemplate
# 定义提示模板
template = ChatPromptTemplate.from_messages([
("system", "你是一位专业的{profession},专长于{specialty}。"),
("human", "请解释{concept},使用通俗易懂的语言,适合{audience}理解。")
])
# 填充模板
prompt = template.format(
profession="物理学家",
specialty="量子力学",
concept="量子纠缠",
audience="高中生"
)
# 使用模型回应格式化的提示
response = llm.invoke(prompt)
print(response.content)
3. 构建简单的链
LangChain的核心概念是"链"(Chain),它允许我们将多个组件连接起来处理复杂任务:
pythonfrom langchain.chains import LLMChain
# 创建链
chain = LLMChain(llm=llm, prompt=template)
# 运行链
result = chain.invoke({
"profession": "软件工程师",
"specialty": "Python开发",
"concept": "装饰器模式",
"audience": "初级程序员"
})
print(result["text"])
高级功能:深入LangChain与OpenAI的强大特性
1. 使用记忆组件实现对话历史
在构建聊天机器人时,记忆上下文历史是关键:
pythonfrom langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
# 创建带记忆的对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferMemory(),
verbose=True # 设置为True可以查看链的执行过程
)
# 多轮对话
response1 = conversation.invoke({"input": "你好,我叫张三"})
print(response1["response"])
response2 = conversation.invoke({"input": "我最喜欢的颜色是蓝色"})
print(response2["response"])
response3 = conversation.invoke({"input": "你还记得我的名字吗?"})
print(response3["response"])
2. 多模态能力整合
OpenAI的GPT-4和GPT-4o系列模型支持图像理解,LangChain也提供了相应的集成:
pythonfrom langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from IPython.display import Image
import base64
import requests
from io import BytesIO
# 初始化支持视觉的模型
vision_model = ChatOpenAI(model="gpt-4o")
# 加载图像
image_url = "https://example.com/some_image.jpg"
response = requests.get(image_url)
image_data = BytesIO(response.content).read()
base64_image = base64.b64encode(image_data).decode("utf-8")
# 创建带图像的消息
message = HumanMessage(
content=[
{"type": "text", "text": "这张图片中有什么?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
)
# 发送请求
response = vision_model.invoke([message])
print(response.content)
3. 向量存储与检索增强生成(RAG)
结合LangChain的向量存储功能,可以实现强大的检索增强生成应用:
pythonfrom langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
# 加载文档
loader = TextLoader("./data/my_document.txt")
documents = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)
# 创建向量存储
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=chunks, embedding=embeddings)
# 创建检索QA链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 其他选项: map_reduce, refine
retriever=vectorstore.as_retriever(),
verbose=True
)
# 查询
query = "请总结文档中关于人工智能的内容"
response = qa_chain.invoke({"query": query})
print(response["result"])
4. 工具使用与Agent构建
LangChain的Agent系统允许模型决定使用哪些工具来完成任务:
pythonfrom langchain.agents import AgentType, initialize_agent, load_tools
# 加载工具
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# 初始化Agent
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 运行Agent
agent.invoke({"input": "今天的日期是什么?计算2023乘以45再减去789等于多少?"})
专家提示:选择合适的OpenAI模型
不同场景下应选择不同的OpenAI模型以优化成本和性能:
- GPT-4o:最适合复杂推理、多模态理解和高精度要求的任务
- GPT-4o mini:性价比最高的选择,适合大多数生产环境
- GPT-3.5 turbo:适合高频、简单的API调用,成本极低
- GPT-4o mini search:适合需要实时信息的应用,可减少RAG系统的复杂度
对于API调用受限地区的用户,可通过老张AI中转API使用这些模型,支持原生调用方式。

实战案例:14个真实应用场景代码实现
以下是使用LangChain和OpenAI构建的14个实用案例,从简单到复杂:
案例1:自定义知识问答机器人
pythonfrom langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# 定义模板
template = ChatPromptTemplate.from_messages([
("system", """你是一个专门回答{domain}问题的AI助手。
请用专业但通俗易懂的语言回答用户的问题。
如果不确定答案,请直接说"我不确定",不要编造信息。"""),
("human", "{question}")
])
# 创建链
llm = ChatOpenAI(model="gpt-4o-mini") # 性价比更高的模型选择
qa_chain = LLMChain(llm=llm, prompt=template)
# 使用
response = qa_chain.invoke({
"domain": "Python编程",
"question": "什么是装饰器,请给出一个简单例子"
})
print(response["text"])
案例2:多步骤推理链
pythonfrom langchain.chains import SequentialChain
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 第一步:问题分解
breakdown_template = PromptTemplate(
input_variables=["question"],
template="请将以下复杂问题分解为几个简单的子问题:\n{question}\n子问题:"
)
breakdown_chain = LLMChain(llm=llm, prompt=breakdown_template, output_key="subquestions")
# 第二步:回答子问题
answer_template = PromptTemplate(
input_variables=["subquestions"],
template="请回答以下子问题:\n{subquestions}\n详细回答:"
)
answer_chain = LLMChain(llm=llm, prompt=answer_template, output_key="subanswers")
# 第三步:综合总结
summary_template = PromptTemplate(
input_variables=["question", "subanswers"],
template="原始问题:{question}\n\n子问题回答:{subanswers}\n\n请给出综合性的最终答案:"
)
summary_chain = LLMChain(llm=llm, prompt=summary_template, output_key="final_answer")
# 组合成顺序链
sequential_chain = SequentialChain(
chains=[breakdown_chain, answer_chain, summary_chain],
input_variables=["question"],
output_variables=["subquestions", "subanswers", "final_answer"],
verbose=True
)
# 使用链处理问题
result = sequential_chain.invoke({"question": "人工智能如何影响未来的就业市场?"})
print(f"最终答案: {result['final_answer']}")
案例3:基于OpenAI Function Calling的结构化输出
pythonfrom langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
# 定义输出结构
class MovieRecommendation(BaseModel):
title: str = Field(description="电影标题")
year: int = Field(description="发行年份")
genre: str = Field(description="电影类型")
director: str = Field(description="导演")
reason: str = Field(description="推荐理由")
class MovieRecommendations(BaseModel):
recommendations: List[MovieRecommendation] = Field(description="电影推荐列表")
# 创建支持函数调用的模型
model = ChatOpenAI(model="gpt-4o", temperature=0.7)
parser = JsonOutputParser(pydantic_object=MovieRecommendations)
# 构建提示
prompt = ChatPromptTemplate.from_messages([
("system", "你是一位电影专家,善于根据用户偏好推荐电影。"),
("human", "请推荐3部{genre}类型的电影,我特别喜欢{director_style}风格的导演。")
])
# 组合成链
chain = prompt | model | parser
# 获取推荐
response = chain.invoke({
"genre": "科幻",
"director_style": "克里斯托弗·诺兰"
})
# 输出结构化数据
for i, movie in enumerate(response.recommendations, 1):
print(f"推荐 {i}:")
print(f" 片名: {movie.title} ({movie.year})")
print(f" 类型: {movie.genre}")
print(f" 导演: {movie.director}")
print(f" 推荐理由: {movie.reason}")
print()
案例4-14
由于篇幅限制,我们无法详细展示所有14个案例的完整代码。以下是其他案例的简要描述:
- 案例4:使用LCEL建立文档摘要系统 - 使用LangChain Expression Language构建对长文档进行自动摘要的系统
- 案例5:多语言翻译链 - 创建能够处理多语言翻译并保持专业术语准确性的翻译系统
- 案例6:基于历史数据的预测分析 - 结合结构化数据分析和LLM推理进行趋势预测
- 案例7:自动化内容创建工作流 - 从主题生成到内容创建、编辑和优化的完整流程
- 案例8:个性化学习助手 - 根据学习进度和风格自适应调整教学内容
- 案例9:多模态产品描述生成器 - 从产品图片和基本信息生成营销描述
- 案例10:情感分析与回应系统 - 分析用户留言情感并给出适当回应
- 案例11:客户支持自动化 - 智能分流和处理客户查询
- 案例12:代码生成与优化 - 从需求描述生成代码并进行优化
- 案例13:文档问答系统 - 基于多文档的精准回答系统
- 案例14:自动化报告生成器 - 从结构化数据生成自然语言报告
完整的案例代码和详细解释可在我们的GitHub仓库找到:LangChain-OpenAI实战案例
性能优化:提升应用响应速度和降低成本
使用LangChain和OpenAI构建应用时,性能和成本是两个重要考量因素。以下是一些优化建议:
1. 模型选择优化
不同任务应选择合适的模型,避免过度使用高性能模型:
python# 简单任务使用更轻量的模型
simple_llm = ChatOpenAI(model="gpt-3.5-turbo")
# 复杂任务使用更强大的模型
complex_llm = ChatOpenAI(model="gpt-4o")
# 根据任务复杂度选择
def get_appropriate_model(task_complexity):
if task_complexity == "low":
return ChatOpenAI(model="gpt-3.5-turbo")
elif task_complexity == "medium":
return ChatOpenAI(model="gpt-4o-mini")
else:
return ChatOpenAI(model="gpt-4o")
2. 提示优化
精心设计的提示可以显著提高响应质量和减少token使用:
python# 不好的提示示例
bad_prompt = "告诉我关于人工智能的信息"
# 优化后的提示
good_prompt = """请提供关于人工智能的简要介绍,包括以下几点:
1. 定义(50字以内)
2. 主要应用领域(列出3-5个)
3. 目前面临的主要挑战(2-3点)
请保持回答简洁,总长度控制在200字以内。"""
3. 缓存策略
LangChain提供了缓存机制,可以避免重复查询:
pythonfrom langchain.cache import InMemoryCache
from langchain.globals import set_llm_cache
# 设置内存缓存
set_llm_cache(InMemoryCache())
# 首次查询会调用API
result1 = llm.invoke("北京是中国的哪个城市?")
# 第二次相同查询会使用缓存,不会重复调用API
result2 = llm.invoke("北京是中国的哪个城市?")
4. 批处理请求
对于多个类似请求,可以使用批处理减少API调用次数:
pythonfrom langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 初始化支持批处理的模型
batch_llm = ChatOpenAI()
# 准备多个消息
messages = [
[HumanMessage(content="你好,请介绍一下北京")],
[HumanMessage(content="你好,请介绍一下上海")],
[HumanMessage(content="你好,请介绍一下广州")]
]
# 批量处理
responses = batch_llm.batch(messages)
for i, response in enumerate(responses):
print(f"回答 {i+1}: {response.content[:50]}...")
5. 流式响应
对于需要快速反馈的场景,可以使用流式响应:
pythonfrom langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 初始化支持流式响应的模型
streaming_llm = ChatOpenAI(streaming=True)
# 生成流式响应
for chunk in streaming_llm.stream("请写一篇关于人工智能的短文"):
print(chunk.content, end="", flush=True)
常见问题:解决LangChain与OpenAI集成难题
在使用LangChain与OpenAI集成过程中,开发者可能遇到各种问题,这里解答一些最常见的问题:
1. API调用错误
问题:遇到"API Connection Error"或"Rate limit exceeded"错误。
解决方案:
- 检查API密钥是否正确设置
- 实现指数退避重试逻辑
- 考虑使用API代理服务,特别是在中国等地区
- 对于速率限制,实现请求节流或升级API套餐
pythonfrom langchain_openai import ChatOpenAI
from langchain.globals import set_debug
# 开启调试模式查看API调用细节
set_debug(True)
# 设置重试逻辑
llm = ChatOpenAI(
model="gpt-3.5-turbo",
max_retries=6, # 最大重试次数
request_timeout=30, # 请求超时时间(秒)
)
# 针对中国等地区的API访问问题
cn_accessible_llm = ChatOpenAI(
model="gpt-4o",
openai_api_base="https://api.laozhang.ai/v1", # 使用API代理服务
openai_api_key="你的API密钥"
)
2. 长文本处理
问题:处理超出模型最大token限制的长文本。
解决方案:
- 使用文本分割器拆分文档
- 实现"map-reduce"或"refine"策略处理长文本
pythonfrom langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
# 分割长文本
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=200
)
docs = text_splitter.create_documents([long_text])
# 使用map_reduce策略处理长文档
summary_chain = load_summarize_chain(
llm,
chain_type="map_reduce",
verbose=True
)
summary = summary_chain.invoke(docs)
3. 工具集成问题
问题:在Agent中集成自定义工具时出错。
解决方案:确保工具定义符合LangChain的格式要求,并且包含详细的描述。
pythonfrom langchain.agents import tool
from langchain.agents import AgentType, initialize_agent
# 定义工具
@tool
def search_database(query: str) -> str:
"""搜索内部数据库。
当需要查询内部数据时使用此工具。
参数:
query: 明确的数据库查询,例如"查找用户ID为12345的信息"
返回:
查询结果的字符串表示
"""
# 实现数据库查询逻辑
return f"查询'{query}'的结果: ..."
# 初始化带自定义工具的Agent
tools = [search_database]
agent = initialize_agent(
tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
4. 输出格式不一致
问题:模型输出格式不一致,导致解析错误。
解决方案:使用输出解析器和函数调用功能确保输出格式化。
pythonfrom langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
# 定义输出格式
class Article(BaseModel):
title: str = Field(description="文章标题")
content: str = Field(description="文章正文内容")
keywords: list = Field(description="关键词列表")
# 创建解析器
parser = JsonOutputParser(pydantic_object=Article)
# 构建提示模板,包含格式说明
prompt_template = ChatPromptTemplate.from_messages([
("system", "你是一个内容创作助手。请生成符合格式要求的文章内容。"),
("human", "请写一篇关于{topic}的简短文章"),
("human", "输出格式: {format_instructions}")
])
# 格式化说明
prompt = prompt_template.partial(
format_instructions=parser.get_format_instructions()
)
# 构建链
chain = prompt | llm | parser
# 使用链
result = chain.invoke({"topic": "人工智能的未来"})
print(f"标题: {result.title}")
print(f"关键词: {result.keywords}")
print(f"内容: {result.content[:100]}...")
未来展望:LangChain与OpenAI生态发展趋势
随着AI技术的快速发展,LangChain和OpenAI的集成将迎来更多可能性:
1. 多模态应用普及
随着OpenAI推出更强大的多模态模型,LangChain将提供更丰富的接口支持文本、图像、音频等多种输入输出形式的处理。这将使得开发者能够构建更加智能、自然的人机交互应用。
2. 细粒度的成本控制
随着API使用成本成为企业关注焦点,LangChain将提供更精细的成本控制机制,如智能模型选择、自动token预估和预算限制等功能。
3. 专业领域优化
未来将出现更多针对特定领域优化的LangChain组件,如法律、医疗、金融等垂直行业的特定处理链和工具,与OpenAI的专业模型微调相结合,提供极高性能的特定领域应用。
4. 本地部署与混合架构
随着开源模型的进步,LangChain将增强对本地部署模型的支持,同时提供混合架构,允许应用同时利用本地模型的隐私优势和OpenAI API的高性能。
结语:掌握LangChain与OpenAI,引领AI应用开发潮流
通过本文的详细指南,我们已经从安装设置到高级应用,全面介绍了LangChain与OpenAI的集成使用。这种强大的技术组合为开发者提供了前所未有的能力,使构建复杂的AI应用变得更加简单高效。
无论你是希望创建简单的问答系统,还是构建复杂的企业级AI应用,LangChain与OpenAI的结合都能为你提供所需的工具和框架。随着这些技术的不断发展,掌握它们将使你在AI应用开发领域保持领先地位。
立即开始实践,探索LangChain与OpenAI的无限可能!
资源汇总
- 官方文档:LangChain Python文档
API接入: 老张AI中转API (支持OpenAI、Claude、Gemini等大模型)
- 代码示例:LangChain GitHub仓库
- 社区支持:LangChain Discord社区
文章最后更新时间:2025年3月15日
注:本文中的代码示例和API用法基于LangChain和OpenAI的最新版本,具体用法可能随版本更新而变化。请参考官方文档获取最新信息。