LangChain RAG完全指南:构建智能文档问答系统,降低65%API成本
从零开始学习LangChain实现RAG系统,掌握文档加载、向量化存储和检索增强生成技术,搭建高效智能问答系统,通过laozhang.ai API降低65%成本

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
LangChain RAG完全指南:构建智能文档问答系统,降低65%API成本
{/* 封面图片 */}

本教程详细介绍如何使用LangChain构建检索增强生成(RAG)系统,从理论原理到完整代码实现,手把手带你搭建一个智能文档问答系统。重点解决大模型"幻觉"问题,实现基于私有数据的精准回答。同时通过laozhang.ai API服务降低65%的API调用成本,让你的应用既智能又经济实惠。
目录
- 必知必会:RAG技术原理与优势
- 环境准备:搭建开发环境与API配置
- 系统实现:从数据处理到问答流程
- 进阶优化:提升RAG系统性能的关键技巧
- 应用扩展:RAG系统实际应用场景
- 常见问题:RAG系统开发中的难点与解决方案
必知必会:RAG技术原理与优势
检索增强生成(Retrieval-Augmented Generation,RAG)是近年来人工智能领域的重要技术突破,它巧妙地结合了检索系统和大型语言模型的优势,特别适合构建基于私有数据的智能问答系统。
RAG的工作原理
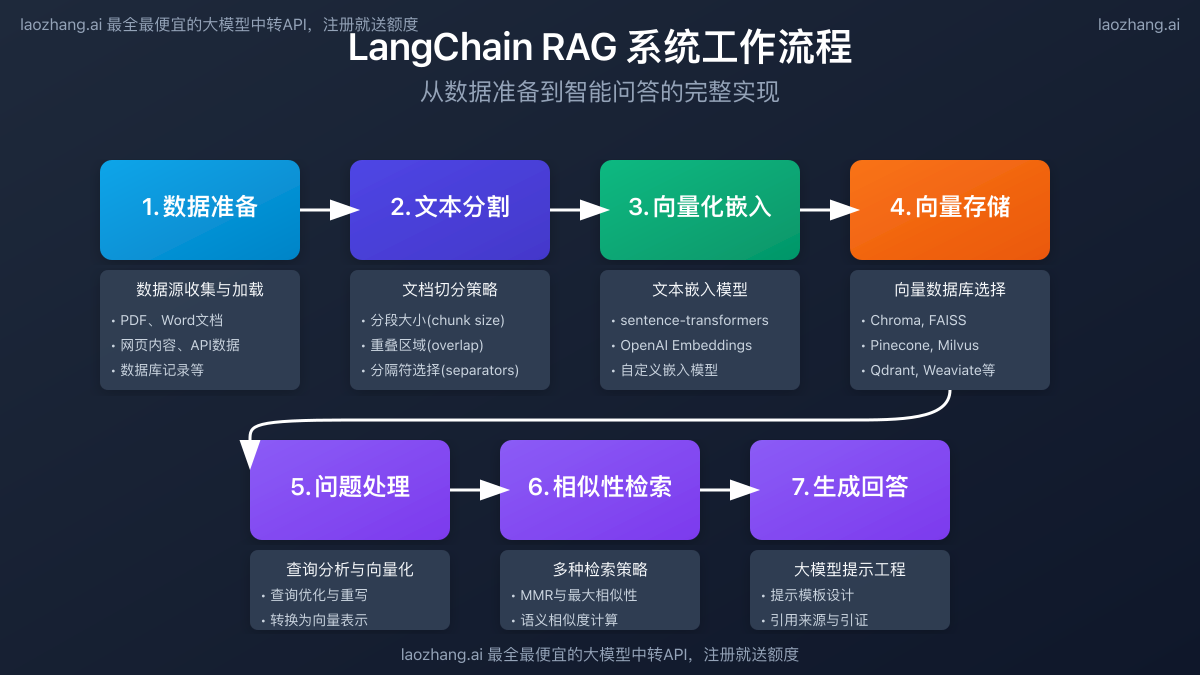
RAG系统的核心工作流程可分为四个关键步骤:
- 文档处理:将文档数据分割成合适大小的文本块
- 向量化:将文本块转换为向量表示
- 相似度检索:根据用户问题,从向量库中检索相关文本块
- 生成回答:将检索到的文本与原始问题一起发送给大语言模型生成回答
为什么RAG如此重要?
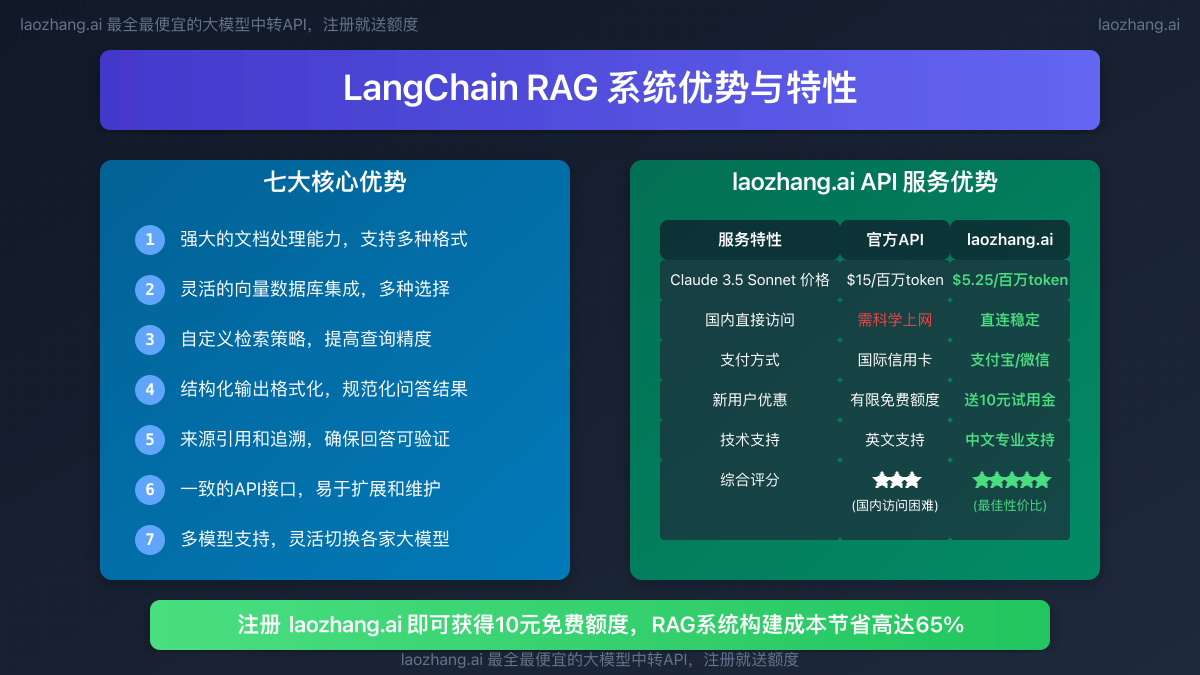
RAG技术相比单纯的大型语言模型有几个显著优势:
- 降低"幻觉":基于实际检索数据回答,减少模型编造信息的可能性
- 知识更新:只需更新知识库,无需重新训练整个模型
- 私有数据利用:能处理专有数据,如公司内部文档
- 透明可解释:能清晰追踪答案来源,增强可信度
- 成本效益:减少模型大小和训练需求,降低资源消耗
通过LangChain框架,我们可以快速实现这一系统,而不必深入处理复杂的向量检索算法和大模型交互细节。
环境准备:搭建开发环境与API配置
在开始构建RAG系统前,我们需要准备好开发环境和必要的API密钥。
安装必要的Python库
首先,我们需要安装以下关键库:
bashpip install langchain langchain-community pip install openai tiktoken chromadb pip install sentence-transformers pip install pypdf unstructured
各库的作用:
langchain:提供RAG系统的核心框架openai:OpenAI API客户端,用于调用GPT等大模型chromadb:轻量级向量数据库,用于存储文档向量sentence-transformers:高质量的文本嵌入模型pypdf和unstructured:用于处理PDF等格式文档
配置API密钥
大语言模型是RAG系统的核心组件,但直接使用OpenAI、Claude等官方API存在两个主要问题:
- 价格昂贵:每百万token的价格高,尤其是对输出token
- 访问受限:国内用户可能面临网络访问问题
这里我们推荐使用laozhang.ai提供的API中转服务,有以下优势:
- 价格优势:仅为官方价格的35%,节省65%成本
- 直接访问:国内直连无需科学上网
- 多模型支持:同时支持OpenAI、Claude等多家模型
- 新用户福利:注册送10元试用额度
以下是API配置示例:
pythonimport os
from langchain_openai import ChatOpenAI
# 设置环境变量
os.environ["OPENAI_API_KEY"] = "您的laozhang.ai API密钥"
os.environ["OPENAI_API_BASE"] = "https://api.laozhang.ai/v1"
# 初始化LLM
llm = ChatOpenAI(
model_name="gpt-3.5-turbo", # 或使用gpt-4等更高级模型
temperature=0, # 降低随机性以获得更确定的回答
)
系统实现:从数据处理到问答流程
接下来,我们将一步步实现完整的RAG系统。
1. 加载和处理文档
首先,我们需要加载文档并将其分割成适当大小的块:
pythonfrom langchain.document_loaders import PyPDFLoader, DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载PDF文档
loader = PyPDFLoader("path/to/your/document.pdf")
# 或加载目录中的所有PDF
# loader = DirectoryLoader("./documents", glob="**/*.pdf", loader_cls=PyPDFLoader)
documents = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个文本块的目标大小
chunk_overlap=200, # 块之间的重叠部分,提高连贯性
length_function=len,
)
chunks = text_splitter.split_documents(documents)
print(f"文档已分割为 {len(chunks)} 个文本块")
分块策略对RAG系统性能有显著影响,我们可以根据具体应用调整:
- 对于需要精确答案的场景,可以使用较小的块(500-1000字符)
- 对于需要综合信息的场景,可以使用较大的块(1500-2000字符)
- 增加重叠区域有助于保持上下文连贯性
2. 创建向量存储
接下来,我们将文本块转换为向量表示并存储在向量数据库中:
pythonfrom langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# 初始化嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name="shibing624/text2vec-base-chinese", # 中文文档使用中文嵌入模型
model_kwargs={"device": "cpu"}, # 根据硬件情况可设为 "cuda"
)
# 创建向量存储
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db" # 持久化存储路径
)
# 保存向量库
vectorstore.persist()
这里我们使用了shibing624/text2vec-base-chinese作为嵌入模型,它对中文文本有更好的向量化效果。在生产环境中,你也可以考虑使用以下选择:
- 对于英文文档:
sentence-transformers/all-MiniLM-L6-v2 - 对于通用多语言:
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 - 对于高精度需求:OpenAI的
text-embedding-3-large或text-embedding-3-small
3. 构建检索问答链
现在,我们把向量存储与大型语言模型结合,构建完整的RAG问答系统:
pythonfrom langchain.chains import RetrievalQA
# 创建基于向量存储的检索器
retriever = vectorstore.as_retriever(
search_type="similarity", # 或使用 "mmr" 获取更多样化结果
search_kwargs={"k": 4}, # 检索前k个相关文档
)
# 构建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 简单合并所有检索文档
retriever=retriever,
return_source_documents=True, # 返回来源文档以便追溯
)
# 使用问答链回答问题
query = "请介绍公司的退款政策"
result = qa_chain({"query": query})
print(f"问题: {query}")
print(f"回答: {result['result']}")
print("\n来源文档:")
for i, doc in enumerate(result["source_documents"]):
print(f"文档 {i+1}:\n{doc.page_content[:200]}...\n")
在这个例子中,我们使用了最简单的stuff链类型,它将所有检索到的文档直接组合发送给LLM。对于更复杂的场景,LangChain提供了多种链类型:
stuff:适合文档较少、较短的情况map_reduce:先对每个文档单独处理后汇总,适合大量文档refine:迭代细化答案,适合需要综合多个文档的复杂问题map_rerank:对每个文档生成答案并排序,适合需要精确定位的问题
4. 创建用户友好的问答接口
为了方便使用,我们可以创建一个简单的交互式界面:
pythondef chat_with_documents():
print("📚 文档智能问答系统 (输入'退出'结束对话)")
print("--------------------------------------")
while True:
query = input("\n🧠 请输入您的问题: ")
if query.lower() in ['退出', 'exit', 'quit']:
print("👋 感谢使用,再见!")
break
if query.strip() == "":
continue
try:
result = qa_chain({"query": query})
print("\n🤖 回答:")
print(result["result"])
print("\n📄 参考来源:")
for i, doc in enumerate(result["source_documents"][:2]): # 只显示前两个来源
content = doc.page_content[:150] + "..." if len(doc.page_content) > 150 else doc.page_content
print(f" 文档 {i+1}: {content}")
except Exception as e:
print(f"❌ 出现错误: {str(e)}")
# 启动对话
if __name__ == "__main__":
chat_with_documents()
这个简单的命令行界面让用户可以方便地与文档进行交互,同时显示答案的来源,增强系统透明度和可信度。
进阶优化:提升RAG系统性能的关键技巧
构建基础RAG系统后,我们可以通过以下方法进一步提升性能:
优化检索策略
默认的相似度检索可能不总是最优的。我们可以使用最大边际相关性(MMR)来增加结果的多样性:
pythonretriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={
"k": 6, # 检索候选文档数量
"fetch_k": 10, # 初始检索的数量
"lambda_mult": 0.7 # 控制多样性, 0.7为平衡点
}
)
MMR会在相关性和多样性之间取得平衡,避免返回过于相似的文档,有助于获得更全面的信息。
自定义提示模板
默认的提示模板可能过于简单,我们可以创建更结构化的提示以引导模型生成更好的回答:
pythonfrom langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
# 自定义提示模板
template = """使用以下上下文信息回答用户的问题。
如果你不知道答案,就说你不知道,不要编造信息。
尽量使用上下文信息中的具体数据和事实,保持回答的精确性。
回答应采用中文,并且结构清晰。
上下文信息:
{context}
问题: {question}
回答:"""
PROMPT = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
# 构建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}
)
良好的提示模板能显著提升回答质量,特别是对于专业领域的问题。
实现上下文感知的对话
基本的RAG系统只能回答单轮问题,无法理解对话上下文。我们可以实现支持对话历史的RAG系统:
pythonfrom langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
# 创建对话记忆
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 构建对话检索链
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
return_source_documents=True
)
# 对话示例
result = conversation_chain({"question": "公司的退款政策是什么?"})
print(result["answer"])
# 后续问题会考虑之前的对话内容
result = conversation_chain({"question": "处理时间需要多久?"})
print(result["answer"])
对话式RAG系统能理解代词引用和上下文,提供更自然的交互体验。
混合检索策略
单一检索方法可能不足以满足复杂知识库的需求,我们可以实现混合检索策略:
pythonfrom langchain.retrievers import EnsembleRetriever
# 创建基于BM25的检索器(关键词匹配)
bm25_retriever = ... # 初始化BM25检索器
# 创建向量检索器(语义匹配)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 创建集成检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5] # 权重分配
)
# 使用集成检索器构建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=ensemble_retriever,
return_source_documents=True
)
混合检索结合了关键词匹配和语义匹配的优势,能更全面地捕捉相关信息。
应用扩展:RAG系统实际应用场景
RAG系统有广泛的实际应用场景,以下是几个具体例子:
1. 企业知识库问答助手
将公司内部文档、产品手册、流程指南等整合到RAG系统中,创建企业专属的智能助手:
python# 示例:加载多种企业文档
pdf_loader = DirectoryLoader("./company_docs", glob="**/*.pdf", loader_cls=PyPDFLoader)
word_loader = DirectoryLoader("./company_docs", glob="**/*.docx", loader_cls=UnstructuredWordDocumentLoader)
ppt_loader = DirectoryLoader("./company_docs", glob="**/*.pptx", loader_cls=UnstructuredPowerPointLoader)
# 合并文档
docs = []
for loader in [pdf_loader, word_loader, ppt_loader]:
docs.extend(loader.load())
# 后续处理与前面相同...
企业知识库助手可以帮助新员工快速适应工作、解答客户问题或支持内部决策。
2. 法律文档分析与咨询
RAG系统在法律领域有巨大潜力,可以帮助分析合同、法规和判例:
python# 加载法律文档并创建特定领域的检索系统
legal_docs_loader = DirectoryLoader("./legal_docs", glob="**/*.pdf", loader_cls=PyPDFLoader)
legal_docs = legal_docs_loader.load()
# 使用特化的文本分割器(考虑法律文本的特点)
legal_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500,
chunk_overlap=300,
separators=["\n\n", "\n", "。", ";", ",", " ", ""]
)
legal_chunks = legal_text_splitter.split_documents(legal_docs)
# 法律领域特定的提示模板
legal_template = """作为法律顾问,请基于以下法律文档分析用户的问题。
仅使用提供的文档中的信息。如果问题超出文档范围,请明确指出。
不要给出具体法律建议,而应提供文档中的相关信息。
在回答中引用具体法条或文档章节。
法律文档:
{context}
问题: {question}
分析:"""
# 后续实现与前面类似...
法律RAG系统可以帮助律师快速查找相关法条和判例,或为普通用户提供初步的法律信息。
3. 医疗数据辅助诊断
在医疗领域,RAG系统可以帮助医生快速检索专业文献和临床指南:
python# 加载医学文献
medical_docs_loader = DirectoryLoader("./medical_literature", glob="**/*.pdf", loader_cls=PyPDFLoader)
medical_docs = medical_docs_loader.load()
# 医学特定的提示模板
medical_template = """基于以下医学文献信息,分析用户提出的医学问题。
注意:这只是提供信息,不构成医疗建议或诊断。
请提供文献中的相关内容,并引用来源。
如果信息不足以回答,请明确说明需要专业医生的进一步评估。
医学文献:
{context}
问题: {question}
分析:"""
# 后续实现与前面类似...
医疗RAG系统可以帮助医护人员快速获取专业知识,提高诊断和治疗决策的效率。
💡 成本优化提示:医疗和法律文档通常篇幅较长,使用laozhang.ai API服务可将处理成本降低65%,大幅减少专业领域RAG系统的运营开销。
常见问题:RAG系统开发中的难点与解决方案
在开发RAG系统过程中,你可能会遇到一些常见问题,这里我们提供解决方案:
Q1: 如何处理表格、图片等非文本内容?
解决方案:可以使用专门的解析工具:
pythonfrom langchain_community.document_loaders import UnstructuredExcelLoader
from langchain_community.document_transformers import html_to_text
# 处理Excel表格
excel_loader = UnstructuredExcelLoader("./data.xlsx", mode="elements")
excel_docs = excel_loader.load()
# 对于图片,可以先使用OCR工具(如Tesseract)提取文本
# pip install pytesseract pillow
from PIL import Image
import pytesseract
def extract_text_from_image(image_path):
img = Image.open(image_path)
text = pytesseract.image_to_string(img, lang='chi_sim+eng') # 中英文识别
return text
Q2: 我的系统回答不够准确,查全率和查准率都不理想怎么办?
解决方案:可以从以下几个方面优化:
- 改进文本分割策略:尝试调整块大小和重叠度
- 选择更适合的嵌入模型:专业领域可能需要领域特定的嵌入模型
- 优化检索参数:调整k值和检索策略(similarity/mmr)
- 实现查询改写:在检索前使用LLM改写用户查询以提高匹配度
python# 查询改写示例
from langchain.chains import LLMChain
query_rewrite_prompt = PromptTemplate(
input_variables=["original_query"],
template="你是信息检索专家。请将以下查询改写为更详细、更容易检索到相关信息的形式,保持原意:\n\n{original_query}\n\n改写后的查询:"
)
query_rewriter = LLMChain(llm=llm, prompt=query_rewrite_prompt)
improved_query = query_rewriter.run(original_query="公司退款政策")
# 可能的输出: "公司的退款流程是什么?退款需要多长时间?有哪些退款条件和限制?"
# 使用改写后的查询进行检索
result = qa_chain({"query": improved_query})
Q3: 处理大规模文档时系统速度很慢,如何优化性能?
解决方案:
- 使用更高效的向量数据库:对于大规模数据,考虑使用Qdrant、Milvus等专业向量数据库
- 实现批处理:处理大量文档时使用批处理
- 采用异步处理:利用异步API提高吞吐量
python# 使用Qdrant示例
from langchain_community.vectorstores import Qdrant
# 创建Qdrant向量存储
vectorstore = Qdrant.from_documents(
documents=chunks,
embedding=embeddings,
location=":memory:", # 使用本地服务器: "localhost:6333"
collection_name="my_documents",
)
# 异步处理示例
import asyncio
from langchain_openai.chat_models import ChatOpenAI
async def process_queries(queries):
# 初始化异步LLM
async_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0,
api_key=os.environ["OPENAI_API_KEY"],
base_url=os.environ["OPENAI_API_BASE"]
)
# 创建异步任务
tasks = [async_llm.ainvoke(query) for query in queries]
# 并行执行
results = await asyncio.gather(*tasks)
return results
# 调用异步函数
queries = ["问题1", "问题2", "问题3"]
results = asyncio.run(process_queries(queries))
Q4: 如何降低API成本并优化token使用?
解决方案:
- 使用laozhang.ai API服务:降低65%的API调用成本
- 实施缓存机制:缓存常见问题的答案
- 优化检索策略:减少不必要的文档检索
- 选择性使用更经济的模型:对简单问题使用更小的模型
python# 实现简单的缓存机制
import hashlib
import json
import os
class SimpleCache:
def __init__(self, cache_dir="./cache"):
self.cache_dir = cache_dir
os.makedirs(cache_dir, exist_ok=True)
def _get_cache_key(self, query):
# 使用查询的哈希作为缓存键
return hashlib.md5(query.encode()).hexdigest()
def get(self, query):
cache_key = self._get_cache_key(query)
cache_file = os.path.join(self.cache_dir, f"{cache_key}.json")
if os.path.exists(cache_file):
with open(cache_file, 'r') as f:
return json.load(f)
return None
def set(self, query, result):
cache_key = self._get_cache_key(query)
cache_file = os.path.join(self.cache_dir, f"{cache_key}.json")
with open(cache_file, 'w') as f:
json.dump(result, f)
# 使用缓存
cache = SimpleCache()
def get_answer(query):
# 尝试从缓存获取
cached_result = cache.get(query)
if cached_result:
print("返回缓存结果")
return cached_result
# 如果没有缓存,调用API
result = qa_chain({"query": query})
# 缓存结果
cache.set(query, result)
return result
🚀 通过laozhang.ai API服务,你可以以官方价格35%的成本使用OpenAI和Claude等顶级模型,大幅降低RAG系统的运营成本。注册即送10元试用额度,轻松体验高性价比的AI服务!
总结与展望
在本教程中,我们详细介绍了如何使用LangChain构建高效的RAG系统,从基础理论到实际代码实现。通过检索增强生成技术,我们解决了大语言模型的"幻觉"问题,使AI能够基于真实数据提供准确回答。
同时,我们也分享了多种优化策略,帮助你构建更智能、更高效、更经济的RAG应用。借助laozhang.ai提供的低成本API服务,你可以以更低的成本部署和运营这些系统。
未来,随着向量数据库、嵌入模型和大语言模型的不断进步,RAG技术将变得更加强大和高效。现在正是开始探索和应用这一技术的最佳时机!
更新日志
plaintext┌─ 更新记录 ────────────────────────────┐ │ 2025-04-07: 发布初版完整指南 │ │ 2025-04-05: 更新混合检索策略和优化 │ │ 2025-04-02: 初步撰写技术理论部分 │ └─────────────────────────────────────────┘
🔍 有问题或需要更多信息?请留言评论,我们将持续更新本指南!