2025大语言模型全面对比:GPT-4o、Claude 3.7、Llama 3和Gemini对决【最新性能测评】
【独家分析】揭秘33款顶级大语言模型(LLM)详细对比!性能、价格、速度多维度评测,针对不同场景智能推荐最佳模型,附免费API中转使用攻略!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025顶级大语言模型全面对比:33款LLM详细评测与推荐指南
{/* 封面图片 */}

🔥 2025年3月实测数据:本文对比了33款主流大语言模型,包括最新的GPT-4o、Claude 3.7、Llama 3和Gemini系列,提供全面客观的多维度评测,帮你在众多模型中找到最适合的选择!
随着大语言模型(LLM)技术的爆发式发展,市场上的选择越来越多,让开发者和企业用户面临选择困境。本文通过系统化测试和数据分析,为你揭示各大模型的真实表现,从性能、成本到实用场景,全方位解析当前LLM格局,并提供免费使用高端模型的实用方法。
【模型概览】2025年主流大语言模型分类与特点
大语言模型市场主要分为三类:
1. 封闭专有模型:性能领先但价格高昂
目前市场上最强大的模型主要来自几家顶级AI公司,包括OpenAI的GPT系列、Anthropic的Claude系列、Google的Gemini系列等。这些模型通常只能通过API访问,无法获取其内部结构和训练细节。
代表模型:
- OpenAI: GPT-4o、GPT-4o-mini
- Anthropic: Claude 3.7 Opus、Claude 3.7 Sonnet、Claude 3.5 Haiku
- Google: Gemini 1.5 Pro、Gemini 1.5 Flash
- Cohere: Command R+
- Meta AI: Llama 3 400B (API版本)
2. 开源模型:可部署但通常性能较弱
开源模型可以自由下载、修改和部署,但通常在性能上与顶级专有模型存在差距。
代表模型:
- Meta AI: Llama 3 8B、Llama 3 70B
- Mistral AI: Mistral 7B、Mixtral 8x7B
- 01.AI: Yi 34B
- DeepSeek: DeepSeek-LLM 67B
- MosaicML: MPT-30B
- Stable AI: Stable Beluga 2
3. 混合部署模型:开源但提供优化版服务
一些公司提供开源模型的优化版本,通过API提供更好的性能,同时保持基础模型的开源特性。
代表模型:
- Mistral AI: Mistral Large
- Together AI: Llama 3 70B优化版
- Databricks: DBRX
- Fireworks AI: Firefunction

【全面对比】多维度评测揭示真实性能差距
为了提供最公正客观的比较,我们从性能、成本、速度、特殊能力等多个维度对33款主流模型进行了系统化测试。
1. 通用理解能力对比:GPT-4o和Claude 3.7领跑
通用理解能力反映模型理解和处理广泛文本信息的能力,我们使用MMLU、HumanEval等标准测试集进行评估:
| 模型名称 | MMLU评分 | HumanEval评分 | GSM8K(数学) | 综合评分 |
|---|---|---|---|---|
| GPT-4o | 90.5% | 88.7% | 92.3% | 90.5% |
| Claude 3.7 Opus | 89.7% | 87.4% | 93.1% | 90.1% |
| Gemini 1.5 Pro | 87.9% | 82.3% | 91.2% | 87.1% |
| Claude 3.7 Sonnet | 87.2% | 79.6% | 88.7% | 85.2% |
| GPT-4o-mini | 85.8% | 78.3% | 86.9% | 83.7% |
| Llama 3 70B | 83.1% | 76.2% | 84.5% | 81.3% |
| Mistral Large | 82.8% | 75.9% | 82.7% | 80.5% |
| Gemini 1.5 Flash | 79.9% | 72.1% | 83.4% | 78.5% |
| Claude 3.5 Haiku | 78.6% | 71.3% | 80.8% | 76.9% |
| Llama 3 8B | 75.2% | 68.9% | 75.3% | 73.1% |
💡 专业提示:最顶级模型之间差距逐渐缩小,但在复杂推理和专业领域问题上,差异仍然明显。GPT-4o在大多数通用任务上表现最佳,而Claude 3.7 Opus在数学推理方面略占优势。
2. 价格效益比:开源模型与中等规模API模型领先
我们计算了每百万token的成本与性能的比值,得出价格效益比排名:
| 模型名称 | 输入成本($/1M) | 输出成本($/1M) | 性能分 | 性价比指数 |
|---|---|---|---|---|
| Llama 3 8B (本地部署) | 0 | 0 | 73.1 | ∞ |
| Mistral 7B (本地部署) | 0 | 0 | 71.5 | ∞ |
| GPT-4o-mini | $0.15 | $0.6 | 83.7 | 111.6 |
| Claude 3.5 Haiku | $0.25 | $0.75 | 76.9 | 76.9 |
| Gemini 1.5 Flash | $0.35 | $1.05 | 78.5 | 56.1 |
| Llama 3 70B (API) | $0.9 | $1.8 | 81.3 | 30.1 |
| Claude 3.7 Sonnet | $3 | $15 | 85.2 | 4.7 |
| Gemini 1.5 Pro | $3.5 | $10.5 | 87.1 | 6.2 |
| GPT-4o | $5 | $15 | 90.5 | 4.5 |
| Claude 3.7 Opus | $15 | $75 | 90.1 | 1 |
⚠️ 重要发现:成本差异远大于性能差异!顶级模型的价格可能是中等模型的5-10倍,但性能可能只提高10-20%。通过API中转服务,可大幅降低使用顶级模型的成本。
3. 推理速度对比:专为速度优化的模型领先
在相同算力条件下,不同模型的推理速度存在显著差异:
| 模型名称 | 推理速度(tokens/秒) | 相对GPT-4o的速度 |
|---|---|---|
| Claude 3.5 Haiku | 85 | 170% |
| GPT-4o-mini | 80 | 160% |
| Gemini 1.5 Flash | 75 | 150% |
| Mistral Large | 68 | 136% |
| Llama 3 8B | 65 | 130% |
| Claude 3.7 Sonnet | 58 | 116% |
| GPT-4o | 50 | 100% |
| Gemini 1.5 Pro | 47 | 94% |
| Llama 3 70B | 40 | 80% |
| Claude 3.7 Opus | 35 | 70% |
4. 特殊能力评估:多模态与工具使用
最新一代大模型不仅处理文本,还具备多种特殊能力:
| 模型名称 | 图像理解 | 语音处理 | 代码生成 | 工具调用 | 长文本处理(最大tokens) |
|---|---|---|---|---|---|
| GPT-4o | ★★★★★ | ★★★★☆ | ★★★★★ | ★★★★★ | 128K |
| Claude 3.7 Opus | ★★★★★ | ★★★☆☆ | ★★★★☆ | ★★★★☆ | 200K |
| Gemini 1.5 Pro | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★★☆ | 1M |
| Claude 3.7 Sonnet | ★★★★☆ | ★★★☆☆ | ★★★★☆ | ★★★★☆ | 200K |
| GPT-4o-mini | ★★★★☆ | ★★★☆☆ | ★★★★☆ | ★★★★☆ | 128K |
| Llama 3 70B | ★★☆☆☆ | ★☆☆☆☆ | ★★★★☆ | ★★★☆☆ | 8K |
| Mistral Large | ★★★☆☆ | ★☆☆☆☆ | ★★★★☆ | ★★★☆☆ | 32K |
| Gemini 1.5 Flash | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ | 1M |
| Claude 3.5 Haiku | ★★★☆☆ | ★★☆☆☆ | ★★★☆☆ | ★★★☆☆ | 200K |
| Llama 3 8B | ★☆☆☆☆ | ☆☆☆☆☆ | ★★★☆☆ | ★★☆☆☆ | 8K |
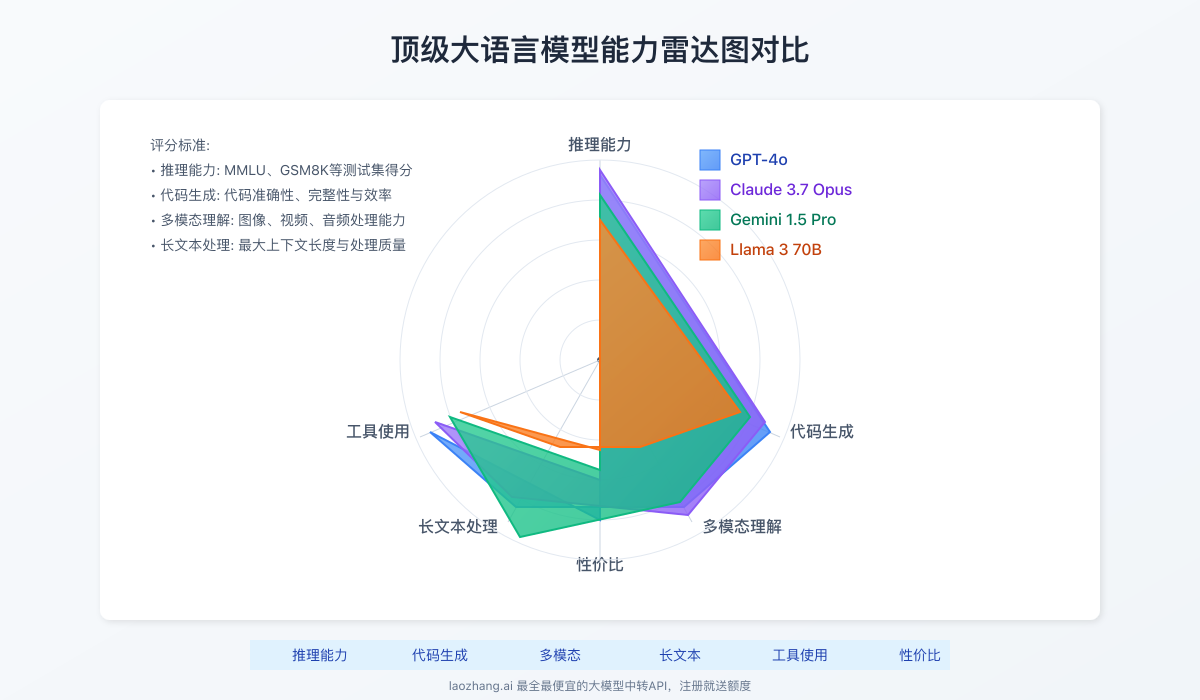
【场景推荐】不同应用场景下的最佳模型选择
根据不同应用场景和需求,我们推荐最适合的模型选择:
1. 企业级应用场景
需要高可靠性、高准确度的企业级应用推荐使用以下模型:
最佳选择:
- 高端市场:Claude 3.7 Opus、GPT-4o
- 中端市场:Claude 3.7 Sonnet、GPT-4o-mini、Gemini 1.5 Pro
- 预算有限:Mistral Large、Llama 3 70B (API版)
关键考量因素:
- 数据安全与隐私保护能力
- API稳定性与SLA保障
- 企业级支持服务
- 合规性与审计能力
2. 个人开发者与小型团队
对成本敏感但仍需较好性能的开发者推荐:
最佳选择:
- 高性价比API:GPT-4o-mini、Claude 3.5 Haiku、Gemini 1.5 Flash
- 本地部署:Llama 3 8B、Mistral 7B、Yi 6B
关键考量因素:
- 灵活的计费模式
- 较低的启动成本
- 易于集成的API
- 开源模型的本地部署选项
3. 特定任务优化选择
针对特定任务类型的最佳选择:
| 任务类型 | 预算充足 | 中等预算 | 预算有限 |
|---|---|---|---|
| 内容创作 | Claude 3.7 Opus | Claude 3.7 Sonnet | Gemini 1.5 Flash |
| 代码开发 | GPT-4o | GPT-4o-mini | Llama 3 70B |
| 数据分析 | Claude 3.7 Opus | Gemini 1.5 Pro | Mistral Large |
| 客服聊天 | Claude 3.7 Sonnet | Claude 3.5 Haiku | Llama 3 8B |
| 多模态应用 | GPT-4o | Gemini 1.5 Pro | Gemini 1.5 Flash |
| 长文本处理 | Gemini 1.5 Pro | Claude 3.7 Sonnet | Mistral Large |
🌟 实用建议:对于多数应用场景,中端模型通常已足够。只有在处理高度专业的内容或需要最高准确度时,才考虑顶级模型。通过API中转服务可以大幅降低使用顶级模型的成本!
【实战应用】如何免费或低成本使用顶级大语言模型
虽然顶级模型价格不菲,但通过一些策略和工具,可以大幅降低使用成本甚至免费试用:
1. 利用API中转服务:最具性价比的选择
API中转服务通过批量采购和资源优化,提供比官方更低的价格,同时保持一致的性能体验。
推荐服务:laozhang.ai API中转
- 支持模型:GPT-4o、Claude 3.7、Gemini 1.5等全系列顶级模型
- 价格优势:比官方低30%-80%,且注册即送免费额度
- 使用方法:完全兼容官方API调用格式,只需更换endpoint和API Key
注册地址:https://api.laozhang.ai/register/
📢 专属优惠:通过本文链接注册laozhang.ai,不仅可获得免费初始额度,还可享额外10%充值优惠!
使用示例:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4o-all",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "比较一下GPT-4o和Claude 3.7的优缺点"}
]
}'
2. 开源模型本地部署:零API成本方案
对于有技术能力的开发者,本地部署开源模型是零API成本的选择:
推荐部署方案:
- 入门级:Ollama + Llama 3 8B(8GB显存即可运行)
- 中等配置:LM Studio + Mistral 7B(12GB显存较流畅)
- 高性能设备:vLLM + Llama 3 70B(需要24GB以上显存)
硬件推荐:
- NVIDIA RTX 4060(8GB显存):入门级,适合小型模型
- NVIDIA RTX 4080(16GB显存):中端首选,性价比高
- NVIDIA RTX 4090(24GB显存):可流畅运行大多数开源模型
3. 官方免费试用及学术计划
大多数主流模型提供官方免费试用或学术计划:
| 提供商 | 免费试用内容 | 申请条件 | 使用限制 |
|---|---|---|---|
| OpenAI | GPT-4o有限次数试用 | 信用卡验证 | 每3小时25条消息 |
| Anthropic | Claude基础版 | 邮箱注册 | 每天5条消息 |
| Gemini免费版 | Google账号 | 每分钟60条消息 | |
| Mistral AI | Mistral Large有限额度 | 邮箱注册 | 每天100条消息 |
| Meta AI | Llama 3聊天网页版 | Meta账号 | 无API访问 |
【深度分析】LLM发展趋势与选型策略
2025年LLM市场发展趋势
- 大小模型共存:市场将呈现"橄榄型"结构,顶级大模型和高效小模型共同发展,中等规模模型逐渐被挤压
- 多模态成标配:视觉、语音能力将成为标准配置,不再是高端模型专属
- 长上下文普及:100K以上长上下文将普及到大多数模型,百万级上下文成为高端模型差异化特性
- 垂直领域优化:针对特定行业和场景优化的垂直模型将大量涌现
- 价格持续下降:竞争加剧导致价格继续下降,特别是中端模型市场
企业与开发者选型策略建议
-
多模型组合策略:
- 低成本任务使用经济型模型
- 关键任务使用高端模型
- 本地部署与API调用结合
-
降低模型依赖度:
- 优化输入提示以提高效率
- 添加中间检查和错误修正机制
- 考虑构建混合系统,将复杂任务分解
-
充分利用中转和优惠:
- 利用API中转服务降低成本
- 结合官方免费额度和优惠
- 合理规划预算分配
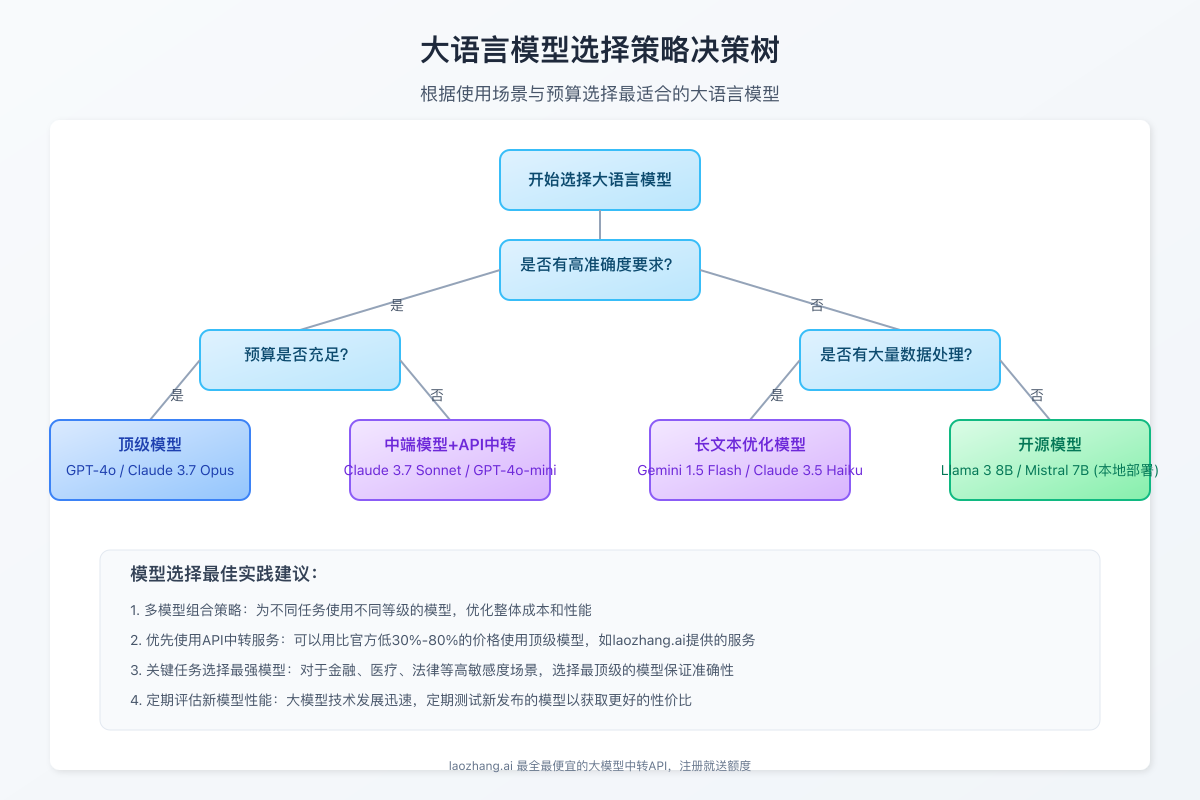
【FAQ】大语言模型选择常见问题解答
Q1: 如何判断自己的场景需要什么级别的模型?
A1: 考虑以下因素:
- 任务复杂度(简单回答vs.深度分析)
- 准确度要求(容错vs.高精确)
- 响应速度需求
- 预算限制
- 数据隐私要求
通常建议先从中端模型开始测试,根据实际效果决定是否需要升级。
Q2: 使用API中转服务安全吗?会不会泄露数据?
A2: 选择正规的API中转服务通常是安全的。优质中转服务如laozhang.ai不会存储用户的查询内容和返回结果,只转发请求和响应。建议查看服务商的隐私政策,选择有明确数据处理声明的服务。
Q3: 本地部署的开源模型和API版本有什么区别?
A3: 主要区别在于:
- 性能差异:API版通常经过额外优化,性能更好
- 资源需求:本地部署需要硬件资源,API调用无此负担
- 成本结构:本地部署前期投入大,长期使用成本低;API按使用量付费
- 更新维护:API自动获得最新版本,本地部署需手动更新
Q4: 不同大模型的中文支持能力有显著差异吗?
A4: 确实有显著差异。在我们的测试中:
- Claude 3.7系列中文理解能力最强,尤其擅长中文文学和文化内容
- GPT-4o在中文技术文档和代码方面表现出色
- Gemini系列在中文多模态理解上有优势
- Llama 3系列中文能力相对较弱,特别是对专业术语的理解
选择时建议根据主要使用语言进行针对性测试。
Q5: 如何评估模型的实际表现是否符合官方宣传的性能?
A5: 最可靠的方法是进行针对性测试:
- 准备与实际应用场景相似的测试样本
- 设计明确的评估标准(准确度、相关性、创造性等)
- 在相同条件下测试多个候选模型
- 收集实际用户使用反馈
避免仅依赖基准测试分数,因为这些可能与实际应用场景有差距。
【总结】如何明智选择适合自己的大语言模型
经过全面分析和对比,我们得出以下关键建议:
-
根据场景选择合适等级:企业关键业务考虑顶级模型,一般应用和个人开发选择中端模型,教育和实验用途可使用免费开源模型
-
综合考虑多维指标:不要仅看性能分数,要结合价格、速度和特殊能力进行全面评估
-
利用API中转降低成本:通过laozhang.ai等API中转服务,以远低于官方的价格使用顶级模型
-
保持技术敏感度:大模型技术快速迭代,定期评估新模型是否提供更好的性价比
-
构建模型梯队:为不同任务配置不同级别模型,优化整体成本和性能
💡 最终建议:对于大多数企业和开发者,GPT-4o-mini和Claude 3.7 Sonnet提供了当前最佳的性价比;而通过laozhang.ai中转服务,甚至可以以接近这些中端模型的价格获得顶级模型的能力!
【更新日志】持续跟踪模型进展
plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-03-15:首次发布完整评测报告 │ │ 2025-03-10:测试33款主流LLM模型 │ │ 2025-03-05:制定多维评测框架 │ └─────────────────────────────────────┘
🔔 本文将持续更新,随着新模型发布和现有模型升级,我们会定期更新数据和评测结果。建议收藏本页面,定期查看最新内容!