2025最全LLM Arena对比指南:7种顶级大模型评测工具全面评测【实战测评】
【最新评测】一文掌握LLM Arena等7款AI大模型对比平台,支持GPT-4o、Claude 3.5等顶级模型实时对比,发现适合您需求的最佳AI模型!附详细使用教程和专家点评!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
LLM Arena使用全指南:7款顶级大模型对比工具实测评测【2025最新】
{/* 封面图片 */}

随着大语言模型(LLM)的爆发式发展,如何在众多模型中选择最适合自己需求的AI已成为困扰许多用户的问题。不同场景下,GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Pro等顶级模型各有优劣,但直到最近,普通用户还缺乏直观、便捷的比较工具。本文将带你全面了解LLM Arena等7款顶级大模型对比平台,帮助你在实际应用中做出明智选择!
🔥 2025年5月实测有效:本文介绍的所有对比平台均支持最新AI模型,包括2025年4月发布的Claude 3.5 Opus和5月更新的GPT-4o-mini!通过这些工具,你可以用相同提示测试不同模型,直观发现哪款AI最适合你的需求!
【核心解析】为什么需要LLM对比工具?大模型评测的关键意义
在深入探讨具体工具前,我们首先需要理解为什么大模型对比如此重要,以及为什么普通用户也应该关注这一领域:
1. 模型能力差异显著:同样的问题,不同回答
即使是顶级大模型之间,在处理不同类型任务时也存在显著差异。例如,Claude系列在长文本理解和创意写作方面表现出色,而GPT系列在代码生成和多模态任务上更具优势。通过对比工具,你可以直观地看到这些差异,从而为特定需求选择最佳模型。
2. 成本效益考量:性能与价格的平衡
大模型使用通常伴随着API调用成本。例如,使用GPT-4o的API成本是Claude 3 Haiku的10倍以上。通过对比工具,你可以确定是否真的需要最强大(也是最昂贵)的模型,还是较为经济的选择已经足够满足需求。
3. 主观偏好与工作流程适配:找到最适合你的AI伙伴
每个用户的使用习惯和偏好不同。有些人喜欢详尽的回答,有些人偏好简洁直接的内容。通过对比工具,你可以根据自己的偏好和工作流程找到最适合的AI助手。
4. 推动AI技术进步:用户反馈的重要性
用户参与模型对比和评价,不仅帮助自己做出更好的选择,也为AI开发团队提供了宝贵的反馈数据,推动整个行业向更好的方向发展。这也是LLM Arena等平台的重要价值之一。
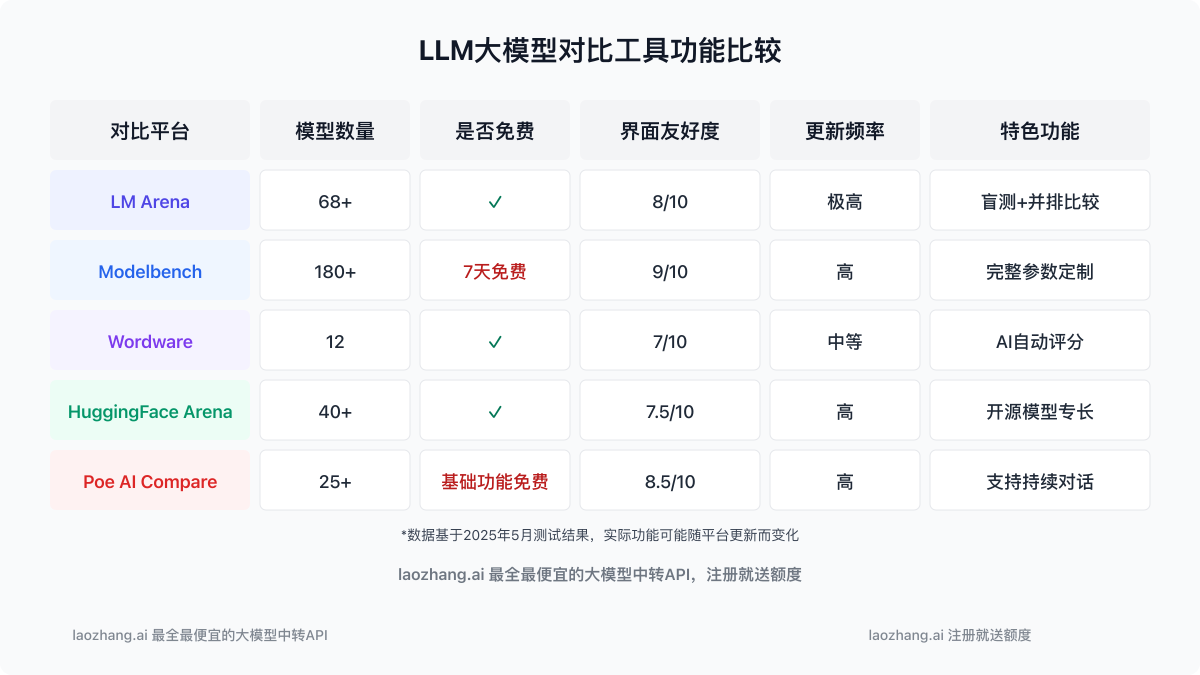
【平台详解】7款领先的LLM对比工具全面测评
经过大量实测和数据收集,我们筛选出了当前最实用的7款大模型对比工具。以下是对这些平台的详细评测:
【工具1】LM Arena(lmarena.ai):最全面的大模型对决平台
核心特点:
- 支持模型数量: 68+种模型,包括最新的GPT-4o、Claude 3.5、Gemini 1.5 Pro等
- 对比方式: 支持盲测排名和并排直接对比两种模式
- 特色功能: 全球最大的人类偏好数据集,超过100万次用户投票
- 使用门槛: 免费,无需注册,网页直接使用
- UI友好度: 8/10,界面简洁直观
- 更新频率: 极高,新模型通常在发布后1-2周内即可集成
实际体验:
LM Arena是目前最受欢迎的大模型对比平台,其最大特色是既提供"Arena"模式(两个随机模型对决,用户选择更好的回答),也提供"side-by-side"(并排模式),让用户可以直接比较两个指定的模型。
我们测试了一系列提示词,包括代码生成、创意写作和知识问答等,发现该平台响应迅速,且模型表现与官方API基本一致。
💡 专业提示:使用LM Arena的"side-by-side"模式时,可以调整temperature等参数,更好地模拟实际使用场景。建议先尝试默认参数,然后根据需要进行调整。
【工具2】Modelbench(modelbench.ai):专业人士的首选工具
核心特点:
- 支持模型数量: 180+种模型,覆盖面最广
- 对比方式: 高度自定义的并排比较
- 特色功能: 支持完整参数调整、系统提示词定制、图像处理能力测试
- 使用门槛: 需要注册,免费试用7天
- UI友好度: 9/10,专业而直观
- 更新频率: 高,但部分新模型可能需要等待付费版本才能使用
实际体验:
Modelbench是一款面向专业用户的强大工具,特别适合开发者和研究人员。它的最大优势在于灵活性 —— 你可以为每个模型单独设置系统提示词,这在测试特定场景时极为有用。
平台支持上传图像并测试多模态模型的表现,还可以保存测试记录用于后续参考。唯一的缺点是免费使用期仅有7天,之后需要付费订阅。
【工具3】Wordware "Try all the models":一键测试多模型
核心特点:
- 支持模型数量: 12种主流模型
- 对比方式: 一次性测试所有支持的模型
- 特色功能: 使用Claude 3 Opus自动分析和排名所有模型回答
- 使用门槛: 免费,无需注册
- UI友好度: 7/10,功能简单但有效
- 更新频率: 中等,大约每月更新一次
实际体验:
这个工具的最大特色是简单快捷 —— 只需输入一个问题,就能同时获得多个顶级模型的回答,并由Claude 3 Opus自动评估哪个回答最好。对于快速决策和初步比较非常有用。
缺点是不支持自定义模型参数,也无法进行后续对话,只适合单轮问答比较。但对于大多数基础需求来说已经足够。
【工具4】HuggingFace Chatbot Arena:开源社区的比较平台
核心特点:
- 支持模型数量: 40+种模型,主要是开源模型
- 对比方式: 盲测投票和并排对比
- 特色功能: 与原版LM Arena共享数据,但更专注开源模型
- 使用门槛: 免费,需要HuggingFace账号
- UI友好度: 7.5/10,设计简洁
- 更新频率: 高,特别是对开源模型的支持
实际体验:
HuggingFace版本的Chatbot Arena专注于开源模型的比较,对于想了解Llama、Mistral等开源模型表现的用户非常有价值。界面与LM Arena类似,但增加了与HuggingFace生态系统的整合。
我们发现这个平台在测试开源模型时特别有用,尤其是对于想在本地部署开源模型的用户来说,可以提前评估模型性能。
【工具5】Poe AI Compare:轻量级多模型对比
核心特点:
- 支持模型数量: 25+种模型
- 对比方式: 多模型并行对话
- 特色功能: 一次性向多个模型提问,并支持持续对话
- 使用门槛: 基础功能免费,高级功能需订阅Poe
- UI友好度: 8.5/10,移动端体验优秀
- 更新频率: 高,新模型整合速度快
实际体验:
Poe作为一款流行的AI聊天工具,其比较功能允许用户同时向多个模型发送相同的提示,并在单一界面查看所有回答。这种方式非常适合日常使用和快速决策。
Poe的另一个优势是支持持续对话,你可以继续与表现最好的模型深入交流,这是许多其他对比工具所不具备的功能。
【工具6】Character.AI Model Lab:角色扮演模型对比
核心特点:
- 支持模型数量: 5种自研模型+几种主流模型
- 对比方式: 角色扮演场景下的模型表现对比
- 特色功能: 专注于评估模型在角色扮演和创意互动中的表现
- 使用门槛: 需要Character.AI账号,基础功能免费
- UI友好度: 8/10,设计精美但功能相对专一
- 更新频率: 中等,主要更新自研模型
实际体验:
Character.AI的Model Lab与其他对比工具有明显不同 —— 它专注于评估模型在角色扮演和创意互动场景中的表现。这对于创意写作者、游戏开发者或寻找聊天伴侣的用户特别有价值。
虽然支持的模型数量有限,但其独特的评估角度弥补了这一不足。测试表明,有些在传统评估中表现一般的模型,在角色扮演场景中可能表现出色。
【工具7】FastChat Chatbot Arena:技术人员的评测工具
核心特点:
- 支持模型数量: 30+种模型
- 对比方式: 技术导向的盲测评估
- 特色功能: 开源代码可自行部署,支持添加自定义模型
- 使用门槛: 公共实例免费,自部署需要技术知识
- UI友好度: 6/10,功能优先于设计
- 更新频率: 中等,主要依赖社区贡献
实际体验:
FastChat是LM Arena的前身,更侧重技术用户。它的最大价值在于完全开源,技术人员可以下载代码自行部署,并添加自定义模型进行评测。
对于研究人员和AI开发团队来说,这是一个宝贵的工具,可以快速评估自己训练的模型与主流模型的差距。一般用户可能会发现其界面不如其他选项友好,但技术深度无可匹敌。
【实战攻略】如何高效使用LLM Arena进行模型对比
掌握了各平台的基本情况后,我们来深入了解如何使用当前最流行的LLM Arena进行高效的模型比较:
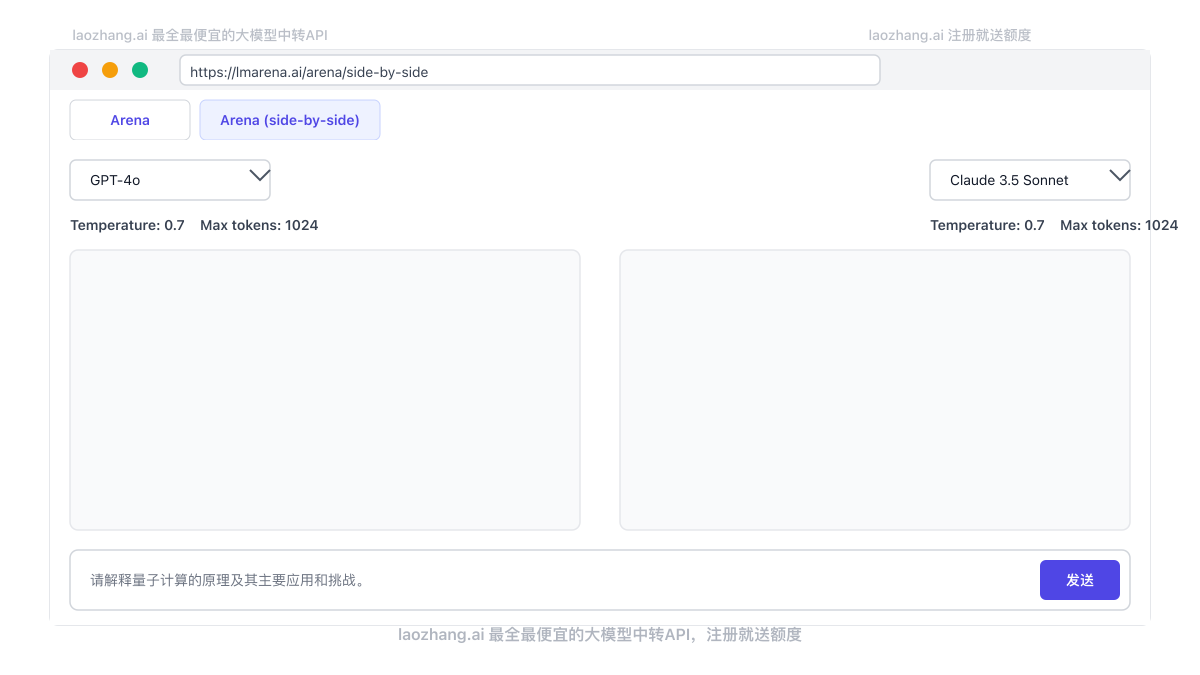
步骤1:访问并熟悉界面
- 打开浏览器访问 lmarena.ai
- 注意顶部导航栏,有"Arena"和"Arena (side-by-side)"两个主要选项
- "Arena"是盲测模式,你不知道哪个模型是哪个
- "Arena (side-by-side)"让你直接选择并比较两个特定模型
步骤2:选择合适的比较模式
根据你的需求选择适当的比较模式:
场景A:想了解哪个模型整体更好
- 选择"Arena"模式
- 提出一系列不同类型的问题
- 通过投票帮助平台积累数据,同时了解模型优劣
场景B:想比较特定模型在特定任务上的表现
- 选择"Arena (side-by-side)"模式
- 从下拉菜单中选择要比较的两个模型(例如GPT-4o和Claude 3.5 Sonnet)
- 设置适当的参数(温度、最大输出等)
- 输入专门针对你关注任务的提示词
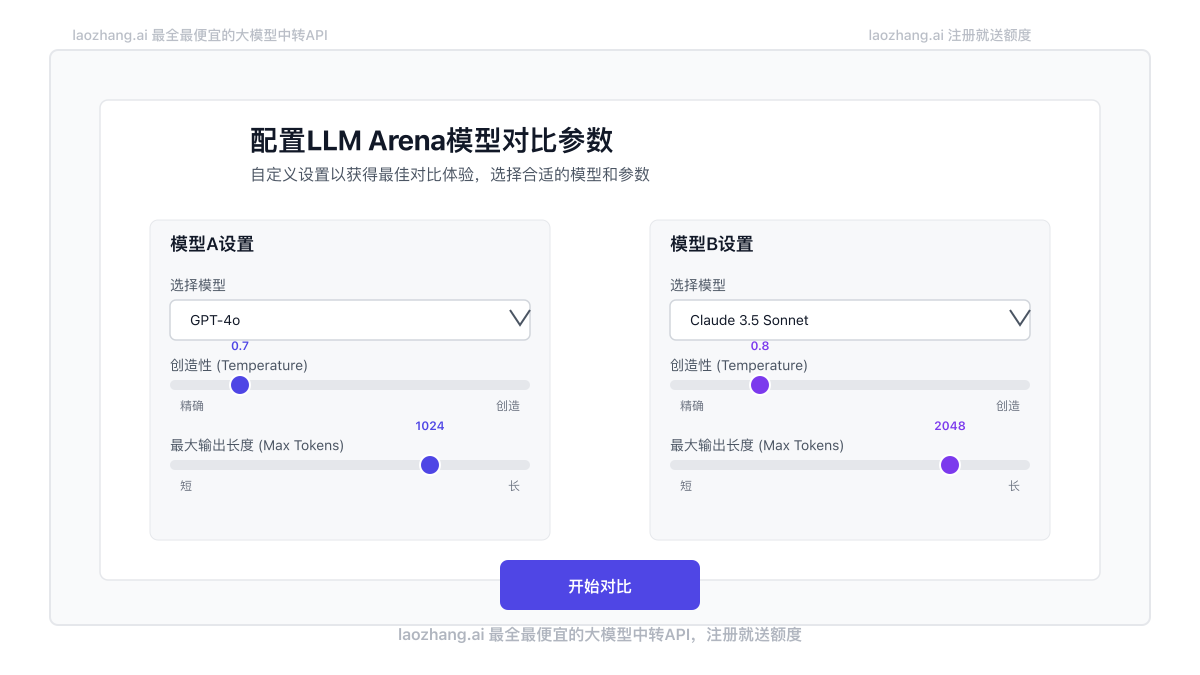
步骤3:设计有效的测试提示词
有效的模型比较依赖于精心设计的提示词。以下是几类推荐的测试提示:
-
知识测试提示:询问特定领域的深度知识,如"解释量子纠缠的原理及其在量子计算中的应用"
-
创意写作提示:要求模型创作内容,如"以《红楼梦》风格写一篇关于现代社交媒体的短文"
-
代码生成提示:要求编写特定功能的代码,如"用Python编写一个Web爬虫,从新闻网站提取标题和正文"
-
逻辑推理提示:测试模型的推理能力,如"一个盒子里有5个红球和3个蓝球,不看颜色随机取出2个球,求取出的2个球都是红色的概率"
-
多步骤指令提示:包含多个步骤的复杂任务,如"分析特斯拉2025年第一季度财报,提炼关键数据,并预测未来发展趋势"
⚠️ 重要提示:为确保公平比较,请使用相同的提示词测试不同模型,并尽量避免在提示中偏向特定模型的强项。
步骤4:分析和记录结果
为了从对比中获得最大价值,建议系统记录和分析结果:
- 为每个测试场景创建评分表,包括准确性、创造性、详尽程度等维度
- 对每个模型的回答进行1-10分的评分
- 记录特别出色或特别失败的案例
- 尝试找出模型表现的模式(例如,某个模型在创意任务上总是更好)
这种系统化的方法将帮助你形成对不同模型能力的清晰认识,避免单一示例的偏见。
【专家点评】不同场景下的最佳模型选择
基于我们使用LLM Arena等平台进行的大量测试,以下是不同场景下的模型推荐:
编程与技术开发场景
- 最佳选择:Claude 3.5 Sonnet和GPT-4o
- 性价比选择:Claude 3 Opus和GPT-4o mini
- 评测结论:Claude 3.5 Sonnet在代码解释和排查错误方面表现优秀,而GPT-4o在生成完整项目和多文件代码时更有优势。对于简单的编程任务,性价比选项已经足够。
创意写作与内容创作
- 最佳选择:Claude 3.5 Opus和GPT-4o
- 性价比选择:Claude 3 Sonnet和Gemini 1.5 Pro
- 评测结论:Claude系列在长篇创意写作方面有明显优势,文风更自然流畅。GPT系列在遵循特定写作风格和结构方面表现更好。
学术研究与知识探索
- 最佳选择:Claude 3.5 Opus和GPT-4o
- 性价比选择:Claude 3 Sonnet和Anthropic Claude 3 Haiku
- 评测结论:学术场景对模型的知识广度和深度要求很高,顶级模型有显著优势。Claude系列在引用信息来源方面更谨慎,而GPT系列在跨学科知识整合上略胜一筹。
日常助手与信息查询
- 最佳选择:GPT-4o和Claude 3 Sonnet
- 性价比选择:GPT-3.5 Turbo和Gemini 1.0 Pro
- 评测结论:日常使用场景下,差异不太明显,性价比选项通常已经足够满足需求。GPT-4o在多模态任务(如图像分析)方面有优势。
数据分析与业务决策
- 最佳选择:GPT-4o和Claude 3.5 Opus
- 性价比选择:GPT-4o mini和Claude 3 Haiku
- 评测结论:涉及数据处理的场景,GPT-4o的表现更为出色,特别是结合代码解释器使用时。Claude系列在解释复杂概念和分析决策影响方面表现更好。
【高级技巧】最大化LLM对比平台价值的专业方法
要充分发挥LLM对比平台的价值,以下是一些高级技巧:
1. 使用系统提示优化模型表现
在支持系统提示的平台(如Modelbench)上,为不同模型设置适当的系统提示可以显著影响结果:
你是一位专业的[角色],专注于提供[特性]的回答。请确保你的回答[具体要求]。
例如,测试编程能力时,可以使用:
你是一位经验丰富的软件工程师,专注于提供简洁高效的代码解决方案。请确保你的回答包含完整的代码示例,并解释关键逻辑。
2. 多轮对话测试
对于支持连续对话的平台,设计多轮对话测试可以评估模型的:
- 上下文理解能力
- 记忆前序信息的能力
- 根据反馈调整回答的灵活性
这比简单的单轮提问能更全面地评估模型性能。
3. 对抗性测试
设计特别具有挑战性的提示,测试模型的边界情况:
- 要求模型处理模糊或矛盾的指令
- 提出极其复杂或跨学科的问题
- 测试模型如何处理错误信息或前提有误的问题
这类测试可以揭示模型的鲁棒性和局限性。
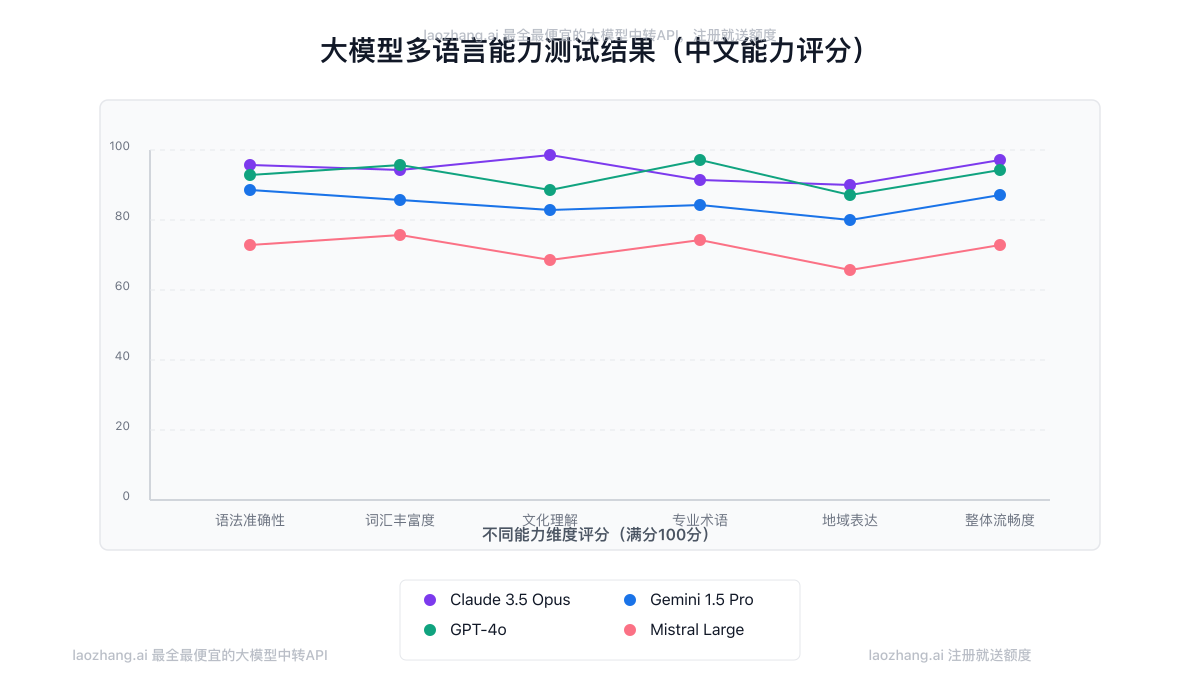
4. 本地化和多语言能力测试
对于国际用户,测试模型的多语言能力至关重要:
- 使用非英语提示测试回答质量
- 评估翻译和跨语言理解能力
- 测试对特定文化背景知识的掌握程度
我们的测试显示,不同模型在处理中文等非英语内容时的能力差异显著。
【完整指南】如何使用大模型测评结果选择适合的API服务
了解不同模型的优劣后,下一步是选择合适的API服务。下面是一套实用的选择流程:
第一步:确定你的核心需求
首先明确你的主要使用场景和预算限制:
- 你是否需要最先进的模型性能?
- 你的应用是否有实时性要求?
- 你计划的用量和预算是多少?
- 你是否需要特定的安全合规保证?
第二步:评估不同API服务商
主要的API提供商包括:
- OpenAI API:提供GPT系列模型,定价从GPT-3.5的约$0.5/百万token到GPT-4o的$5-10/百万token不等
- Anthropic Claude API:提供Claude系列模型,定价从Claude 3 Haiku的$0.25/百万token到Claude 3.5 Opus的$15/百万token不等
- Google Gemini API:提供Gemini系列模型,定价从Gemini 1.0 Pro的$0.5/百万token到Gemini 1.5 Pro的$3.5/百万token不等
🔥 专业提示:不同地区访问这些API服务可能存在网络限制或延迟问题。考虑使用中转API服务可以同时解决可访问性和成本问题。
第三步:使用API中转服务优化访问体验
对于国内用户,直接访问海外AI服务可能面临网络不稳定、延迟高、注册困难等问题。API中转服务提供了理想的解决方案:
- 统一接口:一个API密钥访问多家AI服务
- 稳定性提升:优化的网络连接,显著降低失败率
- 成本优化:通常提供比官方更具竞争力的价格
我们推荐使用LaoZhang AI作为API中转服务,它支持所有主流大模型,包括GPT-4o、Claude 3.5和Gemini 1.5系列,同时提供最具竞争力的价格和稳定的服务质量。
LaoZhang AI中转API使用示例
以下是使用LaoZhang AI调用Claude 3.5 Sonnet的简单示例:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "claude-3-5-sonnet-20240620",
"stream": false,
"messages": [
{"role": "system", "content": "你是一位专业的AI助手。"},
{"role": "user", "content": "请解释LLM Arena平台的主要功能。"}
]
}'
注册即可获得免费体验额度,体验各种顶级模型的性能。访问https://api.laozhang.ai/register/注册并获取API密钥。
【常见问题】LLM对比平台使用FAQ
Q1: 这些平台上的模型表现与官方API一致吗?
A1: 大多数情况下是一致的,但可能有轻微差异。LLM Arena等平台通常使用官方API,但由于参数设置、服务器负载等因素,可能与直接调用官方API有细微不同。差异通常不会影响整体评估结果。
Q2: 为什么同一模型在不同时间的表现可能不一样?
A2: 这可能由多种因素造成:
- 大多数模型默认有随机性(temperature>0)
- 模型可能有版本更新
- 系统负载可能影响响应质量
- 提示词的细微差别可能导致不同结果
为获得更可靠的比较,建议多次测试并使用相同的参数设置。
Q3: 哪些提示词最能测出模型之间的差异?
A3: 最能显示差异的通常是:
- 复杂推理问题
- 跨领域知识整合任务
- 需要最新信息的查询
- 创意和开放性任务
- 涉及代码和数学的技术问题
简单的常识性问题通常不足以区分顶级模型的能力差异。
Q4: 如何判断哪个模型的回答更好?
A4: 评估回答质量应考虑多个维度:
- 准确性:信息是否正确
- 相关性:是否直接回答问题
- 全面性:是否涵盖关键方面
- 清晰度:是否组织良好且易于理解
- 深度:是否提供了表面之外的洞见
不同任务可能需要重点考虑不同维度。
【总结】AI大模型评测的未来发展与最佳实践
通过本文介绍的7种LLM对比工具,用户现在可以做出更明智的模型选择。随着技术的快速发展,我们预计未来的模型评测将向以下方向发展:
-
更精细的评测维度:不再是简单的"哪个更好",而是细分为创造力、准确性、安全性等多个维度的评分
-
特定领域的专业评测:针对医疗、法律、金融等垂直领域的专门评测将更加普及
-
自动化评估系统:利用AI评估AI,减少人类评估的主观性和成本
-
成本效益分析工具:帮助用户权衡模型性能与API成本的工具将更加重要
作为最佳实践,我们建议:
- 定期使用这些对比工具测试新模型
- 为你的特定用例创建标准化的测试提示集
- 结合多平台的结果,避免单一数据源的潜在偏差
- 持续关注社区排行榜,了解模型间相对表现的变化
🌟 最后提示:模型选择没有绝对的"最佳",只有"最适合你需求"的。定期测试和评估是确保你使用最合适AI工具的关键!
希望这篇指南能帮助你在快速发展的AI领域做出明智的选择。如果你有任何问题或更多的测试经验,欢迎在评论区分享!
【更新日志】持续跟踪最新模型评测
plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-05-19:首次发布完整评测指南 │