o3 API完全指南:推理模型定价、Rate Limit与成本优化实战
深度解析OpenAI o3 API最新定价($2/$8 per 1M tokens)、RPM/TPM分层限制体系、Batch API 50%折扣策略。覆盖o3/o4-mini/o3-pro全系列选型指南,附中国开发者接入方案。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
OpenAI的o3系列是当前最强大的推理模型家族,在数学证明、复杂逻辑和多步科研推理方面达到了PhD级别的表现。很多开发者对o3 API的使用限制存在误解——API并非像ChatGPT那样有"每周50条"的固定消息上限,而是采用RPM(每分钟请求数)和TPM(每分钟token数)的分层限制体系。理解这套体系的运作方式,是高效、低成本使用o3 API的前提。

要点速览
- o3 API定价:输入$2.00/输出$8.00 per 1M tokens,Batch API可享50%折扣至$1.00/$4.00
- o4-mini取代o3-mini:o3-mini已退役,o4-mini($1.10/$4.40)成为轻量推理首选
- API无固定消息限制:采用RPM/TPM分层制,Tier 5可达10,000 RPM和30M TPM
- 成本优化关键:Batch API(50%折扣)+ Cached Input(75%折扣)+ 合理选型可节省55%以上
- 中国开发者方案:通过API中转服务可实现国内直连,无需国际网络环境
o3推理模型家族全景
OpenAI的推理模型(o-series)与通用模型(GPT系列)有本质区别:推理模型在生成答案前会进行内部"思考"(thinking),通过链式推理逐步解决问题。这种机制使其在需要深度逻辑分析的任务上远超通用模型,但也带来了额外的thinking tokens成本——这些内部推理过程消耗的token你需要付费,却不会直接出现在输出中。
当前o-series推理模型家族包含三个主力成员,分别面向不同的性能需求和预算范围:
| 模型 | 输入价格 | 输出价格 | Context | 定位 | 典型场景 |
|---|---|---|---|---|---|
| o3 | $2.00/1M | $8.00/1M | 200K | 深度推理旗舰 | 科研、数学证明、复杂架构设计 |
| o4-mini | $1.10/1M | $4.40/1M | 200K | 高效推理 | 代码审查、数据分析、逻辑推理 |
| o3-pro | $20.00/1M | $80.00/1M | - | 极致推理 | 顶级数学竞赛、前沿科研 |
o3是推理模型的旗舰产品,在SWE-bench软件工程测试和AIME数学竞赛中展现了顶尖水平。它的推理深度远超o4-mini,但响应时间也更长(典型场景5-30秒),且thinking tokens的消耗量更大。对于真正需要PhD级别推理能力的任务,o3的投入是值得的。
o4-mini是o3-mini的继任者(o3-mini已正式退役),在保持出色推理能力的同时实现了更好的性价比。它的响应速度明显快于o3,thinking tokens消耗也更少,单位成本约为o3的55%。对于大多数开发者来说,o4-mini应该是推理任务的默认选择——只有当o4-mini的推理深度明确不够时,才需要升级到o3。
o3-pro面向最极端的推理场景,其定价是o3的10倍。它在CodeForces编程竞赛、国际数学奥林匹克等顶级基准测试中展现了接近人类专家的水平。除非你的应用场景确实需要这种极致推理能力(如前沿科研、竞赛级数学),否则不建议在生产环境中使用o3-pro。
API限制体系深度解析:RPM/TPM分层制
很多关于o3 API"不限量"的讨论源于一个常见误解:API的限制体系与ChatGPT完全不同。ChatGPT使用"每周100条"这样的消息数限制,而API使用RPM(Requests Per Minute)和TPM(Tokens Per Minute)的分层限制。这意味着API本身就没有"每周多少条"的固定上限——你的限制取决于你所在的Tier层级。
OpenAI的API Rate Limit分为5个层级,层级由你的累计消费金额决定(据OpenAI官方Rate Limits文档):
| 层级 | 累计消费 | RPM(请求/分钟) | TPM(Token/分钟) | 适合场景 |
|---|---|---|---|---|
| Free | $0 | 3 | 40,000 | 学习测试 |
| Tier 1 | $5 | 500 | 200,000 | 个人项目 |
| Tier 2 | $50 | 5,000 | 2,000,000 | 小型应用 |
| Tier 3 | $100 | 5,000 | 4,000,000 | 中型应用 |
| Tier 4 | $250 | 10,000 | 10,000,000 | 大型应用 |
| Tier 5 | $1,000 | 10,000 | 30,000,000 | 企业级 |
以Tier 2为例:5,000 RPM意味着每分钟可以发送5,000个请求,换算成每天就是720万次——这已经远远超过绝大多数应用的需求。即使是Tier 1的500 RPM,每天也能处理72万次请求。所以对于绝大多数开发者来说,o3 API实际上已经是"不限量"的,真正限制你的不是配额,而是成本。
推理模型有一个重要特性需要注意:thinking tokens会占用你的TPM配额。一个看似简单的o3请求,其内部推理过程可能消耗5-10倍于可见输出的tokens。例如,一个2000 token输出的回答,实际可能消耗了10,000-20,000 tokens的thinking过程。这在TPM接近上限时尤其需要关注。
如果你的应用确实需要更高的配额,OpenAI支持企业用户申请自定义Rate Limit。通过OpenAI Support提交申请,说明你的使用场景和预期调用量,通常在1-2周内可以获得回复。关于ChatGPT网页版的消息限制(如o3每周100条),可以参考我们的ChatGPT Plus使用限制完全指南。
o3 API定价与成本优化策略
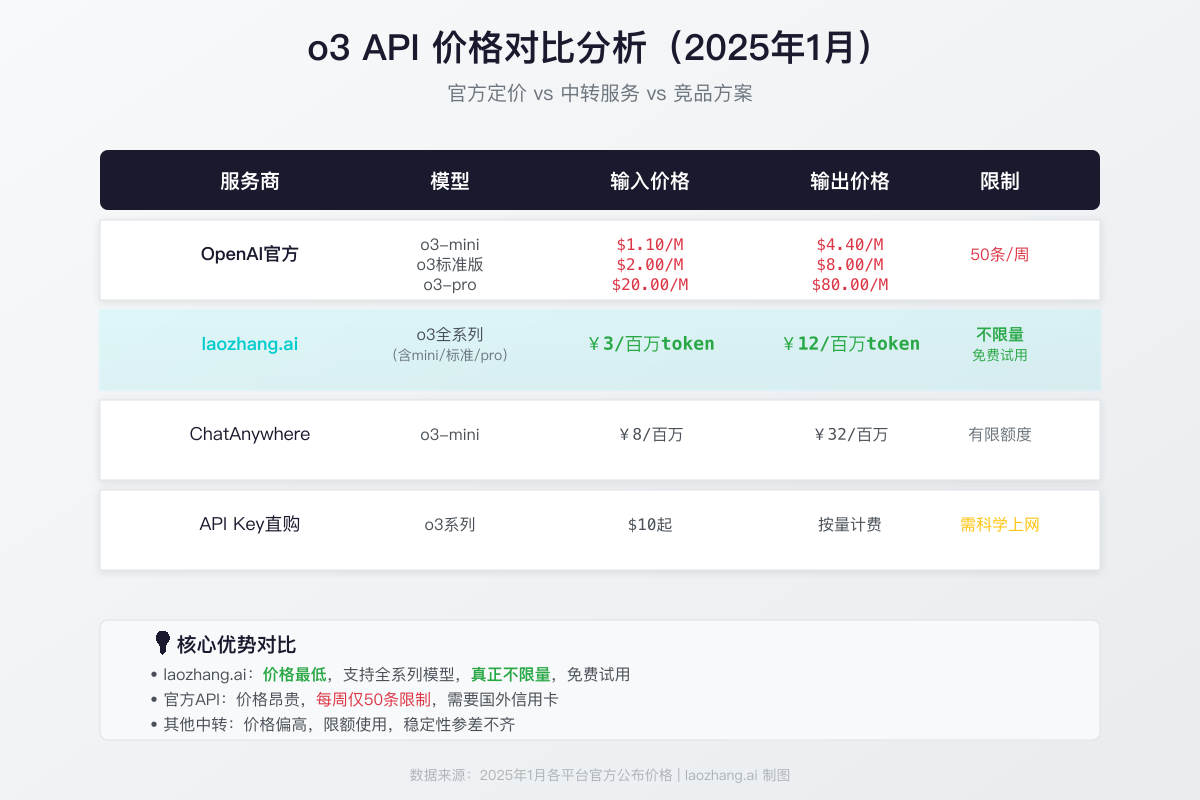
理解o3 API的成本结构是控制开支的关键。与通用模型不同,推理模型的实际成本通常远高于"输入+输出"的简单计算,因为thinking tokens是隐藏的成本大头。
标准定价下,o3的成本结构为:输入$2.00/1M tokens + 输出$8.00/1M tokens。但实际费用中还需要加上thinking tokens的消耗。根据实际使用经验,o3处理一个中等复杂度的推理任务(约1000 token输入、2000 token输出),内部thinking可能消耗8000-15000 tokens,使实际成本达到理论值的3-5倍。
OpenAI提供了两个强大的成本优化工具。Batch API是最直接的节省方式,它为所有模型提供50%的折扣——o3的Batch价格为输入$1.00/输出$4.00 per 1M tokens。代价是异步处理,结果通常在24小时内返回,适合不需要实时响应的批量任务(如数据分析、批量代码审查、研究报告生成)。Cached Input则对重复使用相同system prompt的场景提供75%的输入折扣——o3的缓存输入价格仅$0.50/1M tokens。如果你的应用有固定的系统提示词,这个优化几乎是免费的。
综合运用这两个工具,以一个典型场景为例:每天1000次o3调用,每次约1000 token输入(含固定的500 token system prompt)和2000 token输出。标准模式下月费约$300;使用Batch API后降至$150;如果同时启用Cached Input(system prompt部分),可进一步降至约$135。综合节省55%。
对于成本更敏感的场景,可以采用分级调用策略:简单推理任务用o4-mini(成本仅为o3的55%),只有在o4-mini给出低置信度答案时才升级到o3。这种"先筛后精"的策略可以在几乎不损失质量的前提下再节省30-40%的费用。
o3 vs o4-mini选型指南

选择o3还是o4-mini是开发者最常面临的决策。两者都是推理模型,核心区别在于推理深度和成本。
选择o3的场景:当任务确实需要深度链式推理时,o3的表现明显优于o4-mini。典型场景包括多步数学证明(需要5步以上的逻辑链)、复杂系统架构设计(需要同时考虑10+个约束条件)、高难度编程竞赛问题(涉及高级算法和数据结构优化)。在这些场景中,o3的额外成本换来的是实质性的质量提升。
选择o4-mini的场景:对于大多数日常推理任务,o4-mini已经足够出色。代码审查和bug定位、数据分析和趋势推理、逻辑论证和事实核查、标准编程任务(非竞赛级难度)——这些场景中o4-mini的表现与o3差距不大,但成本仅为其55%,响应速度也更快。
实践中推荐的渐进式选型策略是:默认使用o4-mini处理所有推理任务,在响应中加入置信度评估。当o4-mini的置信度低于阈值(如0.7)时,自动将同一任务重新提交给o3。这种方式既确保了复杂任务的质量,又避免了在简单任务上的过度支出。如果想了解更多AI模型的对比和选择建议,可以参考AI大模型全面对比指南。
快速接入实战教程
接入o3 API的流程与使用其他OpenAI模型完全一致。以下是使用最新版OpenAI Python SDK的标准接入方式:
pythonfrom openai import OpenAI
client = OpenAI(api_key="sk-your-api-key")
response = client.chat.completions.create(
model="o3",
messages=[
{"role": "system", "content": "你是一位数学分析专家,请用严谨的逻辑推理解答问题。"},
{"role": "user", "content": "证明:对任意正整数n,n^3 - n 总是被6整除。"}
]
)
print(response.choices[0].message.content)
如果你需要通过API中转服务访问(适合中国开发者或需要更灵活计费的场景),只需修改base_url参数。laozhang.ai提供了兼容OpenAI格式的中转服务,支持o3全系列模型,注册即送免费额度:
pythonfrom openai import OpenAI
client = OpenAI(
api_key="your-laozhang-api-key",
base_url="https://api.laozhang.ai/v1"
)
response = client.chat.completions.create(
model="o3",
messages=[
{"role": "user", "content": "分析这段代码的时间复杂度并提出优化方案"}
]
)
使用Batch API的方式(节省50%):
pythonimport json
batch_requests = []
for i, task in enumerate(tasks):
batch_requests.append({
"custom_id": f"task-{i}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "o3",
"messages": [{"role": "user", "content": task}]
}
})
with open("batch_input.jsonl", "w") as f:
for req in batch_requests:
f.write(json.dumps(req) + "\n")
batch_file = client.files.create(file=open("batch_input.jsonl", "rb"), purpose="batch")
batch_job = client.batches.create(input_file_id=batch_file.id, endpoint="/v1/chat/completions", completion_window="24h")
生产环境最佳实践包括三个关键要素。首先是错误处理和重试:推理模型由于计算量大,超时概率高于通用模型,建议设置30-60秒的超时时间和3次指数退避重试。其次是成本监控:由于thinking tokens的存在,实际成本可能远超预期,建议在应用层设置每日/每月的预算上限。第三是模型降级策略:当o3不可用或延迟过高时,自动降级到o4-mini保证服务连续性。
中国开发者专属方案
中国开发者使用o3 API面临两个核心挑战:网络访问和支付方式。直接访问OpenAI API需要国际网络环境,且注册和充值需要国际信用卡。
API中转方案是最直接的解决路径。通过laozhang.ai等中转服务,开发者可以在国内网络环境下直接调用o3 API,延迟低至20ms级别,远优于通过国际网络的访问体验。中转服务支持支付宝和微信支付,消除了支付障碍。接入方式极其简单——只需将API请求地址从api.openai.com改为中转服务地址,其余代码完全不变。
Azure OpenAI方案适合已有Azure账户的企业用户。微软Azure在中国有合作运营商,部分区域可以直接访问Azure OpenAI服务。但Azure的模型更新通常比OpenAI官方滞后数周到数月,且计费方式和配额体系与官方不同。
对于预算有限的开发者,建议的策略是:开发和测试阶段使用中转服务(成本低、接入快),正式生产环境根据实际需求选择中转服务或Azure。中国开发者的AI应用开发不应被网络和支付问题阻碍——当前的生态已经提供了充分的解决方案。了解更多ChatGPT相关的订阅和定价信息,可以参考ChatGPT收费标准指南。
常见问题FAQ
o3-mini还能用吗?和o4-mini有什么区别?
o3-mini已正式退役,被o4-mini取代。o4-mini在推理能力上与o3-mini相当甚至更强,价格保持在$1.10/$4.40 per 1M tokens的水平,Context窗口为200K tokens。如果你的代码中还在使用model="o3-mini",需要改为model="o4-mini"。在laozhang.ai等中转服务中,o3-mini请求可能会自动路由到o4-mini。
o3 API真的没有消息数量限制吗?
严格来说,o3 API没有像ChatGPT那样的"每周100条"消息限制。API使用RPM/TPM分层制——你的请求量受限于每分钟的请求数和token数,而不是每周的消息总数。即使是最低的Tier 1(累计消费$5即可达到),也有500 RPM的配额,换算成每天约72万次请求。真正的"限制"是成本,而非配额。
thinking tokens是什么?为什么实际费用比预期高很多?
推理模型在生成最终回答前会进行内部"思考"过程,这些思考步骤消耗的tokens称为thinking tokens。你需要为它们付费,但它们不会出现在API返回的output中。一个典型的o3请求,thinking tokens可能是可见output tokens的3-8倍。这就是为什么很多开发者发现实际费用远超"输入+输出"的简单计算。建议通过OpenAI Dashboard监控实际token消耗,建立准确的成本模型。
Batch API有什么限制?适合什么场景?
Batch API提供50%的价格折扣,但代价是异步处理——结果通常在24小时内返回,而不是实时。它适合不需要即时响应的场景:批量数据分析、代码库审查、研究报告生成、测试数据生产等。不适合的场景包括:实时对话、用户等待响应的交互场景、需要秒级延迟的生产系统。Batch API的请求格式使用JSONL文件,通过Files API上传后提交批次任务。
如何估算o3 API的月度费用?
估算公式为:月费 = 日均调用次数 x 每次平均tokens(输入+输出+thinking) x 30 x 对应单价。一个实际参考:每天100次中等复杂度的o3调用(每次约1000输入+2000输出+8000 thinking tokens),标准价格约$30/月;使用Batch API约$15/月。建议先用小批量测试获取你具体场景的平均token消耗数据,再据此估算月度预算。
总结与推荐方案
o3 API的限制体系在理解后并不可怕。与ChatGPT的消息数限制不同,API采用的RPM/TPM分层制对绝大多数应用来说已经接近"无限制"。真正需要关注的是成本优化和模型选型。
轻量推理需求(大部分场景):使用o4-mini,$1.10/$4.40的价格配合Batch API可低至$0.55/$2.20。适合代码审查、数据分析、逻辑推理等日常任务。
深度推理需求:使用o3标准版,$2.00/$8.00的价格通过Batch API可降至$1.00/$4.00。适合科研、复杂架构设计、高难度编程。
中国开发者:通过laozhang.ai等中转服务接入,国内直连、支付宝支付、免费试用额度,5分钟即可开始使用。
极致推理需求:o3-pro的$20/$80定价面向最极端的场景,绝大多数开发者不需要考虑。
核心建议是:从o4-mini开始,根据实际效果决定是否升级到o3。同时善用Batch API和Cached Input两个官方优化工具,可以在不损失质量的前提下节省55%以上的费用。