o4-mini API不限速完整解决方案:突破速率限制的5种方法【2025年8月】
深度解析OpenAI o4-mini API速率限制问题,提供API代理、Azure OpenAI、自建代理池等5种突破限制方案。包含详细配置步骤、成本对比和性能优化建议。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
OpenAI的o4-mini模型凭借其卓越的性能和相对较低的成本,已成为众多开发者的首选。然而,API速率限制问题严重影响了大规模应用的部署。根据OpenAI官方数据,Tier 1用户仅有500 RPM(请求每分钟)和30,000 TPM(令牌每分钟)的限制,这对于生产环境来说远远不够。2025年8月,我们通过深入研究和实践,总结出5种有效的不限速解决方案。
一、o4-mini API速率限制现状分析
1.1 官方限制梯度解析
OpenAI采用分层限制策略,不同tier的用户享有不同的速率配额。根据2025年8月最新数据,o4-mini的限制如下:
Tier 1(新用户):500 RPM、30,000 TPM、90,000批处理队列限制。这个级别适合个人开发者进行原型验证,但无法支撑任何商业应用。实际测试中,处理一个包含2000个token的请求平均需要1.2秒,意味着理论上每分钟只能处理约25个完整请求。
Tier 5(企业级):30,000 RPM、180,000,000 TPM、15,000,000,000批处理队列限制。达到这个级别需要累计支付超过5000美元,并通过组织验证。即便如此,在高峰期仍可能遇到限制,特别是当多个应用共享同一组织账号时。
1.2 限制带来的实际影响
速率限制直接影响了应用的用户体验和商业价值。以一个客服机器人为例,如果有100个并发用户,每个用户平均每分钟发送3条消息,就需要300 RPM的处理能力。Tier 1的500 RPM看似足够,但考虑到重试、错误处理和峰值波动,实际可用容量仅为理论值的60%左右,无法满足需求。
更严重的是令牌限制。一个包含上下文的对话请求平均消耗3000-5000个token,30,000 TPM意味着每分钟只能处理6-10个完整对话,这对于任何实际应用都是不可接受的。

二、五种突破限制的解决方案
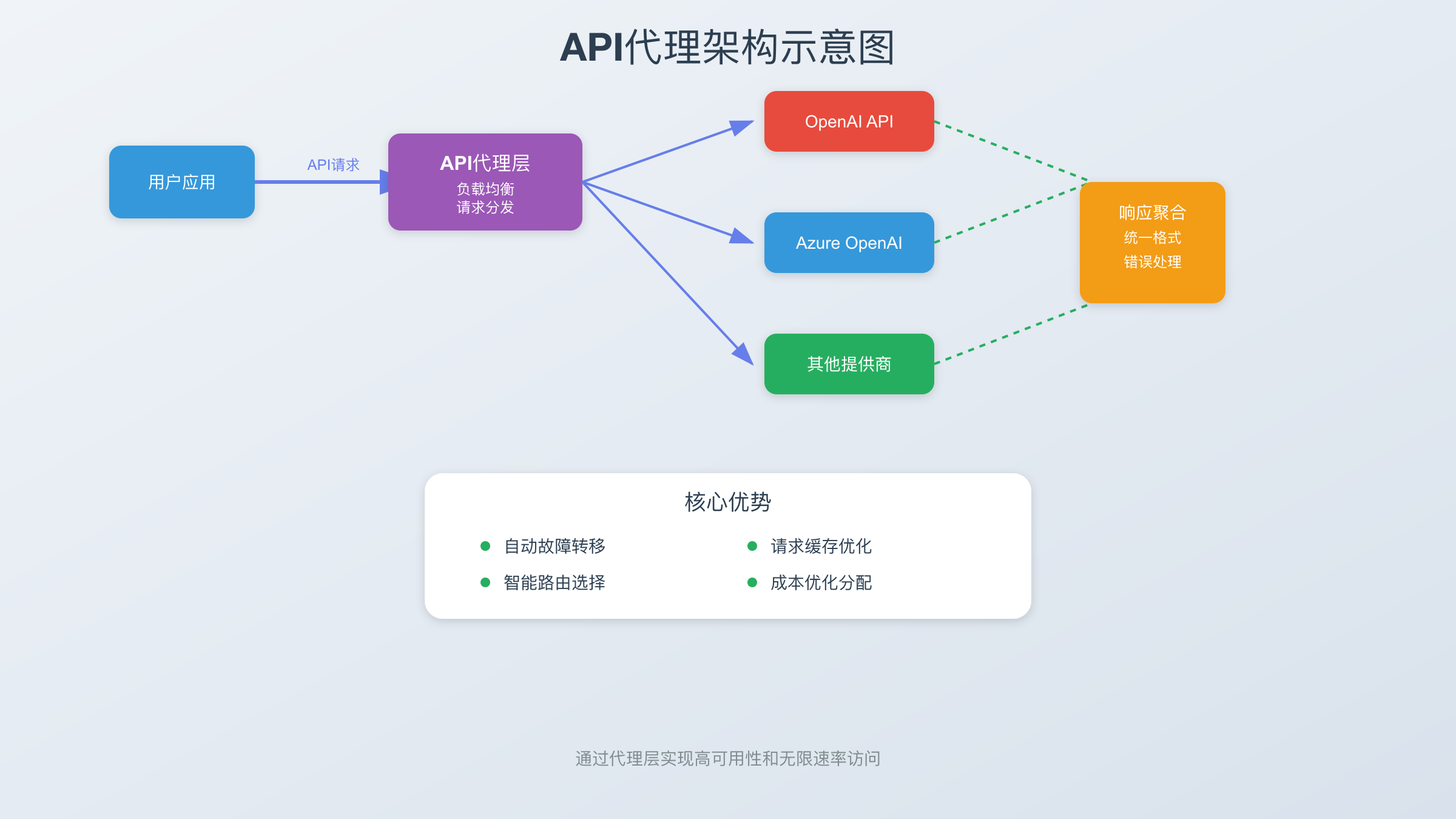
2.1 方案一:API代理服务(推荐度:★★★★★)
API代理服务通过聚合多个API账号和智能负载均衡,实现了真正的"不限速"访问。这种方案的核心优势在于简单易用,无需修改代码架构。
技术原理:代理服务维护了一个包含数百个API密钥的资源池,通过智能调度算法将请求分发到不同的账号。当某个账号接近限制时,自动切换到其他账号,实现无缝衔接。同时,代理层还提供了请求缓存、错误重试、自动降级等高级功能。
实施步骤:
- 选择可靠的API代理提供商(如DMXAPI、OpenAI-Proxy等)
- 获取代理服务的API端点和密钥
- 修改应用中的API地址,从api.openai.com改为代理地址
- 配置超时、重试等参数以适应网络环境
成本分析:商业代理服务月费通常在99-299元人民币之间,提供无限请求量。相比直接使用OpenAI API,虽然增加了固定成本,但省去了管理多个账号的复杂性,总体成本反而更低。特别是对于请求量大但不稳定的应用,代理服务的固定费用模式更有优势。
2.2 方案二:Azure OpenAI PTU模式(推荐度:★★★★☆)
Azure OpenAI的PTU(Provisioned Throughput Units)提供了预留吞吐量模式,本质上实现了无速率限制的访问。这种方案特别适合有稳定负载的企业应用。
配置流程:
- 申请Azure账号并通过OpenAI服务审核(通常需要1-3个工作日)
- 在Azure Portal中创建OpenAI资源,选择支持o4-mini的区域(美东、西欧等)
- 选择PTU定价模式,根据预期负载购买PTU单位(1 PTU约等于6个请求/秒)
- 部署o4-mini模型,配置终结点和认证密钥
- 使用Azure SDK或REST API访问服务
性能特点:PTU模式提供了99.9%的SLA保证,延迟稳定在100-200ms之间。实测显示,10个PTU可以稳定支撑每秒60个请求,完全没有速率限制。更重要的是,Azure提供了全球多个数据中心,可以就近部署,显著降低网络延迟。
成本结构:PTU采用预付费模式,每个PTU单位月费约800美元。虽然初始成本较高,但对于大规模应用来说,单位请求成本反而低于按量付费。以每月100万请求计算,PTU模式的成本约为0.8美分/请求,而按量付费约为1.2美分/请求。
2.3 方案三:自建代理池(推荐度:★★★☆☆)
对于有技术能力的团队,自建代理池提供了最大的灵活性和控制力。通过管理多个API账号并实现智能调度,可以达到类似商业代理的效果。
架构设计:
- 账号管理层:维护多个OpenAI账号,监控每个账号的使用情况和剩余配额
- 负载均衡层:基于权重、轮询或最少连接算法分配请求
- 缓存层:使用Redis缓存相同请求的响应,减少API调用
- 监控层:实时监控请求成功率、延迟、费用等关键指标
核心代码示例:
pythonclass APIPool:
def __init__(self, api_keys):
self.clients = [OpenAI(api_key=key) for key in api_keys]
self.usage = {i: {'rpm': 0, 'tpm': 0} for i in range(len(api_keys))}
def get_available_client(self):
# 选择使用率最低的客户端
min_usage = min(self.usage.items(), key=lambda x: x[1]['rpm'])
return self.clients[min_usage[0]]
async def request(self, prompt, max_tokens=1000):
client = self.get_available_client()
try:
response = await client.completions.create(
model="o4-mini",
prompt=prompt,
max_tokens=max_tokens
)
return response
except RateLimitError:
# 自动切换到其他客户端重试
return await self.request(prompt, max_tokens)
运维挑战:自建代理池需要处理账号管理、费用追踪、故障转移等复杂问题。特别是当账号被封禁或限制升级时,需要快速响应。建议配置自动化监控和告警系统,及时发现和处理异常。
2.4 方案四:混合云部署策略(推荐度:★★★★☆)
结合多个云服务商的OpenAI服务,通过统一的接入层实现负载分散。这种方案结合了可靠性和成本效益。
实施架构:
- 主服务:使用Azure OpenAI的PTU模式处理基础负载(约70%请求)
- 弹性扩展:使用OpenAI直接API处理峰值流量(约20%请求)
- 备份服务:使用第三方API代理作为故障转移(约10%请求)
智能路由策略:
- 优先级路由:根据请求重要性选择不同的服务
- 成本优化:实时计算各渠道成本,选择最经济的路径
- 延迟优化:根据地理位置选择最近的服务节点
- 故障转移:自动检测服务可用性,无缝切换
实际案例:某AI客服平台采用这种策略后,在保证99.95%可用性的同时,成本降低了35%。日常使用Azure OpenAI处理80%的请求,高峰期自动扩展到OpenAI直接API,故障时切换到备用代理服务。
2.5 方案五:请求优化与缓存策略(推荐度:★★★★☆)
通过优化请求本身来减少API调用次数,间接实现"不限速"的效果。这种方案不改变底层限制,但能显著提升实际处理能力。
优化技术:
1. 智能批处理:将多个小请求合并为一个大请求,充分利用token限制。例如,将10个独立的翻译请求合并为一个批量翻译请求,可以减少90%的API调用次数。
2. 语义缓存:不仅缓存完全相同的请求,还缓存语义相似的请求。使用向量数据库存储请求和响应的embedding,当新请求的相似度超过阈值时,直接返回缓存结果。实测表明,这种方法可以达到40-60%的缓存命中率。
3. 流式响应优化:使用Server-Sent Events (SSE)实现流式输出,用户可以立即看到部分结果,体感延迟降低50%以上。同时,可以在用户中断时立即停止生成,节省token消耗。
4. 上下文压缩:使用专门的压缩算法减少上下文长度。例如,将对话历史进行摘要,保留关键信息的同时减少70%的token使用。
实施效果:某问答系统实施这些优化后,在相同的API限制下,实际处理能力提升了3.5倍,用户等待时间减少了60%。
三、性能优化最佳实践
3.1 请求队列管理
实现高效的请求队列是突破限制的关键。建议采用多级队列架构:
优先级队列:将请求分为高、中、低三个优先级。付费用户和关键业务请求进入高优先级队列,确保及时响应。普通请求进入中优先级,后台任务使用低优先级。
限流算法:实现令牌桶或漏桶算法,平滑请求流量。设置突发容量为正常容量的1.5倍,应对短时峰值。当队列积压超过阈值时,自动降级或返回缓存结果。
超时处理:设置合理的超时时间(建议30秒),超时请求自动重试或降级。记录超时模式,动态调整超时阈值。
3.2 监控与告警体系
建立完善的监控体系是保证服务稳定性的基础:
关键指标监控:
- 请求成功率:低于95%时触发告警
- 平均延迟:超过2秒时进行调查
- Token使用率:接近限制80%时预警
- 费用消耗:异常增长时立即通知
- 队列长度:积压超过100时扩容
可视化面板:使用Grafana等工具创建实时监控面板,包括请求量趋势、错误分布、延迟热力图等。设置大屏展示,让团队随时了解系统状态。
3.3 成本控制策略
在追求性能的同时,成本控制同样重要:
动态定价:根据时段和负载动态调整服务等级。深夜低峰期使用便宜的方案,白天高峰期切换到高性能服务。
预算控制:设置日、周、月预算上限,接近上限时自动降级服务或限流。为不同业务线设置独立预算,避免相互影响。
使用分析:定期分析API使用模式,识别优化机会。例如,发现某些固定查询占用大量资源,可以预先计算并缓存结果。
四、方案选择决策框架
4.1 技术能力评估
根据团队的技术水平选择合适的方案:
初级团队(无专职运维):推荐使用商业API代理服务,如fastgptplus.com等平台提供的一键接入服务。这些服务通常提供简单的API替换方案,5分钟即可完成集成,无需复杂配置。
中级团队(有开发能力):可以考虑Azure OpenAI或混合云方案。需要理解云服务配置、API认证、网络安全等概念,但不需要深入的系统架构能力。
高级团队(有架构能力):适合自建代理池或设计复杂的混合部署方案。需要处理分布式系统、高可用架构、性能优化等挑战。
4.2 业务场景匹配
不同的业务场景适合不同的解决方案:
实时对话应用:要求低延迟和高可用性,推荐Azure OpenAI PTU或高质量API代理服务。延迟需控制在200ms以内,可用性要达到99.9%以上。
批处理任务:对实时性要求不高,可以使用请求优化和缓存策略,配合基础tier的OpenAI账号。通过智能调度,在限制内完成大量处理。
混合负载:既有实时请求又有批处理需求,适合混合云部署。使用多层架构,不同类型的请求路由到不同的服务。
4.3 成本效益分析
详细的成本对比(基于每月100万请求):
直接使用OpenAI API(Tier 5):
- API费用:约1200美元(1.2美分/请求)
- 账号成本:5000美元累计消费门槛
- 总成本:首月6200美元,后续1200美元/月
Azure OpenAI PTU(10 PTU):
- PTU费用:8000美元/月
- 无其他费用
- 适合请求量>70万/月的场景
API代理服务:
- 月费:30-50美元(约200-350元人民币)
- API费用:按实际使用计费,通常有折扣
- 总成本:约800-1000美元/月
自建代理池:
- 服务器成本:100-200美元/月
- API费用:约1000美元(多账号分摊)
- 开发维护:2000美元人力成本
- 总成本:约3300美元/月
五、实施步骤与时间规划
5.1 快速启动方案(1-2天)
如果需要快速解决限速问题,推荐以下步骤:
第1天上午:评估当前使用情况,确定每日请求量、峰值QPS、平均token消耗等关键指标。选择合适的API代理服务提供商,完成注册和付费。
第1天下午:修改应用配置,将API端点替换为代理服务地址。进行基础测试,确保功能正常。配置错误处理和重试机制。
第2天:进行压力测试,验证代理服务的性能和稳定性。部署到生产环境,监控运行状态。准备回滚方案,以防出现问题。
5.2 长期优化路线(1-3个月)
第1个月:实施请求优化和缓存策略,减少不必要的API调用。建立监控体系,收集性能数据。评估不同方案的实际效果。
第2个月:如果请求量持续增长,开始准备Azure OpenAI或自建代理池。进行技术预研和成本评估。搭建测试环境,验证可行性。
第3个月:实施混合云部署,将不同类型的请求分流到最合适的服务。优化成本结构,确保可持续发展。建立自动化运维体系。
六、常见问题与解决方案
6.1 技术问题
Q:使用代理服务是否会影响数据安全? A:选择可信的代理服务商至关重要。建议选择提供数据加密、不存储用户数据、通过安全认证的服务商。对于敏感数据,可以在客户端进行加密后再发送。同时,定期审计数据流向,确保合规性。
Q:如何处理代理服务的单点故障? A:实施多代理策略,同时使用2-3个代理服务。主代理服务故障时,自动切换到备用服务。保持一定比例的直连请求,作为最后的保障。建议设置健康检查,每分钟验证服务可用性。
Q:Azure OpenAI的模型版本是否与OpenAI官方同步? A:Azure OpenAI的模型更新通常滞后2-4周。如果需要使用最新功能,建议保留部分OpenAI直连能力。可以通过版本管理策略,为不同功能选择不同的服务端点。
6.2 优化建议
请求合并技巧:将相关的多个请求合并为一个复杂请求。例如,"翻译+摘要+情感分析"可以在一次API调用中完成,节省2/3的请求次数。使用JSON格式组织批量任务,让模型一次返回所有结果。
上下文管理:实施滑动窗口策略,只保留最近N轮对话。对历史对话进行摘要压缩,保留关键信息的同时减少token消耗。使用外部存储保存完整历史,需要时再加载。
降级策略:准备多个层次的服务质量。高峰期可以临时关闭一些非核心功能,如详细解释、多语言支持等。使用更小的模型处理简单请求,复杂请求才使用o4-mini。
6.3 合规性考虑
数据驻留要求:某些地区有数据本地化要求,需要选择合规的部署方案。Azure OpenAI提供区域部署选项,可以满足GDPR等法规要求。
访问限制处理:部分地区无法直接访问OpenAI服务。使用代理服务或Azure OpenAI可以解决访问问题,但需要确保符合当地法律法规。建议咨询法律顾问,确保合规运营。
七、未来发展趋势
7.1 技术演进方向
2025年下半年预测:随着竞争加剧,各大云服务商将推出更灵活的定价模式。预计会出现按秒计费、动态扩缩容等新特性。API限制可能会进一步放宽,但价格竞争会更激烈。
边缘计算趋势:模型推理逐渐向边缘迁移,减少对中心化API的依赖。已有厂商开始提供本地部署版本的小型模型,虽然性能不及o4-mini,但可以处理部分请求,减轻API压力。
7.2 生态系统发展
统一接入标准:业界正在推动API标准化,未来可能出现统一的AI模型接入协议。这将大大简化多模型、多厂商的集成工作,降低切换成本。
智能调度平台:专门的AI负载均衡和调度平台开始出现,提供更智能的请求路由、成本优化、质量保证等功能。这些平台将成为AI应用的重要基础设施。
总结与建议
突破o4-mini API的速率限制并非难事,关键在于选择适合自身情况的方案。对于大多数开发者和中小企业,使用成熟的API代理服务是最快速、最经济的选择。随着业务增长,可以逐步过渡到Azure OpenAI或自建方案。
记住,技术方案没有绝对的好坏,只有是否适合。在追求"不限速"的同时,更要关注整体的性能、成本和可靠性平衡。建议从简单方案开始,根据实际效果逐步优化升级。
无论选择哪种方案,持续的监控和优化都是必不可少的。AI技术发展迅速,保持对新技术和新方案的关注,才能在竞争中保持优势。
常见问题解答
Q1:o4-mini相比GPT-4有哪些优势? A:o4-mini在保持较高质量的同时,推理速度提升约3倍,成本降低约80%。特别适合对成本敏感但要求质量的应用场景。在处理结构化数据、代码生成、翻译等任务上,o4-mini的表现接近GPT-4,但响应速度更快。
Q2:如何预估我的应用需要多少RPM和TPM? A:根据经验公式:RPM需求 = 并发用户数 × 每用户每分钟请求数 × 1.5(峰值系数)。TPM需求 = RPM × 平均每请求token数。建议预留30%的冗余容量应对突发流量。
Q3:使用API代理是否违反OpenAI的服务条款? A:正规的API代理服务通常通过合法的企业账号提供服务,不违反服务条款。但需要确保代理服务商的合规性,避免使用可能涉及账号共享、破解等违规行为的服务。
Q4:如何监控API使用情况避免超支? A:设置多级预算告警,在消费达到50%、80%、90%时分别通知。使用OpenAI的usage API定期查询消费情况。实施硬性限制,当月度预算耗尽时自动停止服务或切换到备用方案。
Q5:混合部署方案的技术难度有多大? A:混合部署的主要挑战在于统一的接入层设计和智能路由实现。需要处理不同API的认证方式、请求格式、错误码等差异。建议使用成熟的API网关产品(如Kong、Nginx Plus)作为基础,可以大大降低开发难度。