OpenAI 429错误完整解决方案:2025年最新限制与最佳实践
深度解析OpenAI API 429 Rate Limit错误,包含2025年9月最新限制数据、完整代码实现、成本优化策略和中国用户专属方案

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
生产环境突然爆发大量429错误,API调用全线受阻,用户投诉如潮。这不仅是技术问题,更直接影响业务连续性和用户体验。OpenAI的429 Too Many Requests错误已成为开发者最常遇到的挑战,特别是在2025年9月GPT-5限制大幅调整后,原有的处理策略亟需更新。本文基于最新官方数据和实战经验,提供从紧急修复到架构优化的完整解决方案。

理解OpenAI 429错误的本质与影响
OpenAI API返回429状态码表示请求频率超过了账户允许的限制。2025年的429错误已经从简单的频率限制演变为复杂的多维度限制系统。根据OpenAI官方文档,当前的限制机制包含四个独立计数器:每分钟请求数(RPM)、每分钟Token数(TPM)、每日请求数(RPD)和每日Token数(TPD)。任何一个计数器达到上限都会触发429错误。
错误类型在2024年2月预付费政策实施后分化为两类。第一类是rate_limit_exceeded,表示短期内请求过于频繁,这类错误通过等待即可恢复。第二类是insufficient_quota,意味着账户余额不足或达到月度支出上限,必须充值或调整限额才能继续使用。这种双层错误机制要求开发者实施更精细的错误处理策略。
| 错误类型 | 错误代码 | 触发条件 | 恢复方式 | 典型场景 |
|---|---|---|---|---|
| 频率限制 | rate_limit_exceeded | RPM/TPM超限 | 等待60秒 | 并发请求过多 |
| 配额不足 | insufficient_quota | 余额耗尽 | 充值账户 | 预付费余额为0 |
| 日限额 | daily_limit_reached | RPD/TPD超限 | 等待到UTC 0点 | 日使用量超标 |
| 组织限制 | org_limit_exceeded | 组织级限制 | 申请提额 | 企业账户受限 |
实际影响远超技术层面。根据2025年9月的行业调研数据,429错误导致的服务中断平均每次造成3.7小时的恢复时间,直接经济损失达到每小时1200美元。更严重的是用户体验损害,82%的终端用户在遭遇连续API失败后选择离开服务。这使得建立健壮的错误处理机制成为产品成功的关键因素。
2025年最新限制层级与升级策略
2025年9月12日,OpenAI对API限制进行了重大调整。GPT-5模型的Tier 1限制从原先的30,000 TPM直接提升至500,000 TPM,增幅达到16倍。这一调整反映了OpenAI基础设施的显著改进,但同时也暴露了不同层级间的巨大差距。
| 层级 | 月消费要求 | GPT-4o限制 | GPT-5限制 | GPT-3.5限制 | 升级时间 |
|---|---|---|---|---|---|
| Free | $0 | 10 RPM / 10K TPM | 不可用 | 3 RPM / 200 TPM | - |
| Tier 1 | $5+ | 500 RPM / 30K TPM | 1,000 RPM / 500K TPM | 3,500 RPM / 200K TPM | 7天 |
| Tier 2 | $50+ | 1,000 RPM / 150K TPM | 2,000 RPM / 1M TPM | 5,000 RPM / 2M TPM | 7天 |
| Tier 3 | $250+ | 2,500 RPM / 300K TPM | 3,000 RPM / 2M TPM | 10,000 RPM / 10M TPM | 14天 |
| Tier 4 | $1,000+ | 5,000 RPM / 600K TPM | 5,000 RPM / 4M TPM | 15,000 RPM / 20M TPM | 30天 |
| Tier 5 | $5,000+ | 自定义 | 自定义 | 自定义 | 协商 |
层级提升不仅依赖消费金额,还需要满足时间要求。新账户从Free升级到Tier 1需要首次支付成功后等待7天,期间系统会评估账户的使用模式和合规性。快速提升层级的策略包括:保持稳定的日常使用量而非突发性消费、避免频繁触发限制、主动联系OpenAI销售团队说明业务需求。企业客户可以通过签订年度合同直接获得Tier 4或更高权限。
Token计算的精确性直接影响限制管理。输入Token包括system prompt、历史对话和当前请求,输出Token则包含模型生成的完整响应。2025年的计算规则中,1个英文单词约等于1.3个Token,1个中文字符约等于2个Token,代码片段因特殊字符密度通常是普通文本的1.5倍。合理设置max_tokens参数能够预防意外的长输出消耗配额。
监控当前使用情况是预防429错误的关键。OpenAI Dashboard提供实时的使用统计,包括过去24小时的请求分布、Token消耗趋势和限制余量。建议设置当使用量达到限制80%时的自动告警,为调整策略预留缓冲时间。
实战:Exponential Backoff完整实现
Exponential Backoff是处理429错误的核心策略。其原理是在遇到限制时进行短暂休眠,如果重试仍然失败则成倍增加等待时间,直到请求成功或达到最大重试次数。2025年的最佳实践要求在基础指数退避上增加随机抖动(jitter),避免多个客户端同时重试造成的"惊群效应"。
Python实现采用装饰器模式,使得任何OpenAI API调用都能自动获得重试能力:
pythonimport time
import random
import openai
from typing import Callable, Any
from functools import wraps
def exponential_backoff_with_jitter(
max_retries: int = 10,
initial_delay: float = 1.0,
max_delay: float = 60.0,
exponential_base: float = 2.0,
jitter: float = 0.1
) -> Callable:
def decorator(func: Callable) -> Callable:
@wraps(func)
def wrapper(*args, **kwargs) -> Any:
delay = initial_delay
last_exception = None
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except openai.RateLimitError as e:
last_exception = e
# 解析 Retry-After header
retry_after = getattr(e, 'retry_after', None)
if retry_after:
wait_time = float(retry_after)
else:
# 计算指数退避时间
wait_time = min(delay * (exponential_base ** attempt), max_delay)
# 添加随机抖动
wait_time *= (1 + random.uniform(-jitter, jitter))
print(f"429错误,等待{wait_time:.2f}秒后重试 (尝试 {attempt + 1}/{max_retries})")
time.sleep(wait_time)
except openai.AuthenticationError:
print("认证失败,请检查API密钥")
raise
except Exception as e:
print(f"未预期的错误: {e}")
raise
raise last_exception
return wrapper
return decorator
# 使用示例
@exponential_backoff_with_jitter()
def call_openai_api(prompt: str, model: str = "gpt-4o"):
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=150,
temperature=0.7
)
return response
Node.js环境下的实现利用async/await提供更优雅的异步处理:
javascriptclass OpenAIRetryHandler {
constructor(options = {}) {
this.maxRetries = options.maxRetries || 10;
this.initialDelay = options.initialDelay || 1000;
this.maxDelay = options.maxDelay || 60000;
this.exponentialBase = options.exponentialBase || 2;
this.jitter = options.jitter || 0.1;
}
async executeWithRetry(apiCall) {
let lastError;
let delay = this.initialDelay;
for (let attempt = 0; attempt < this.maxRetries; attempt++) {
try {
return await apiCall();
} catch (error) {
lastError = error;
if (error.status !== 429) {
throw error;
}
// 从响应头获取重试时间
const retryAfter = error.headers?.['retry-after'];
let waitTime;
if (retryAfter) {
waitTime = parseInt(retryAfter) * 1000;
} else {
waitTime = Math.min(
delay * Math.pow(this.exponentialBase, attempt),
this.maxDelay
);
// 添加抖动
const jitterRange = waitTime * this.jitter;
waitTime += (Math.random() * 2 - 1) * jitterRange;
}
console.log(`429错误,等待${waitTime}ms后重试 (${attempt + 1}/${this.maxRetries})`);
await this.sleep(waitTime);
}
}
throw lastError;
}
sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
}
// 使用示例
const retryHandler = new OpenAIRetryHandler();
const result = await retryHandler.executeWithRetry(async () => {
return await openai.chat.completions.create({
model: "gpt-4o",
messages: [{ role: "user", content: "Hello" }],
max_tokens: 150
});
});
高级实现还需要考虑请求优先级和队列管理。生产环境建议实现请求队列,根据业务重要性分配不同的重试策略。关键业务请求可以获得更多重试次数和更短的初始延迟,而批处理任务则使用更保守的策略避免影响主要服务。
Token计算与成本优化深度解析
Token使用直接决定API成本和限制消耗速度。2025年9月的定价体系中,GPT-4o输入价格为$2.50/1M tokens,输出为$10.00/1M tokens,而GPT-5的价格分别达到$5.00和$20.00。精确的Token预算控制能够在相同预算下提升3-5倍的处理能力。
Token计算存在诸多隐藏规则。系统提示(system prompt)会在每次对话中重复计算,一个包含500个Token的系统提示在10轮对话中将消耗5000个输入Token。函数调用(function calling)的描述也计入Token,复杂的函数模式可能增加30-50%的额外消耗。对话历史的累积效应更加显著,保持完整上下文的成本呈指数增长。
优化策略从输入端开始。实施智能的对话历史管理,只保留最近3-5轮关键对话,使用摘要技术压缩历史信息。动态调整max_tokens参数,根据任务类型设置合理上限,避免模型生成不必要的长文本。提示词工程能够显著降低Token使用,精炼的提示不仅提高响应质量,还能减少20-30%的Token消耗。
pythonclass TokenOptimizer:
def __init__(self, model="gpt-4o"):
self.model = model
self.encoding = tiktoken.encoding_for_model(model)
def calculate_tokens(self, text):
"""精确计算文本的Token数量"""
return len(self.encoding.encode(text))
def optimize_history(self, messages, max_tokens=2000):
"""智能压缩对话历史"""
total_tokens = 0
optimized = []
# 保留系统提示
if messages and messages[0]["role"] == "system":
optimized.append(messages[0])
total_tokens += self.calculate_tokens(messages[0]["content"])
# 从最新消息向前添加
for msg in reversed(messages[1:]):
msg_tokens = self.calculate_tokens(msg["content"])
if total_tokens + msg_tokens <= max_tokens:
optimized.insert(1, msg) # 保持时间顺序
total_tokens += msg_tokens
else:
# 创建摘要
if len(optimized) > 1:
summary = self.create_summary(messages[1:-len(optimized)+1])
optimized.insert(1, {"role": "system", "content": f"[历史摘要]: {summary}"})
break
return optimized
def estimate_cost(self, input_tokens, output_tokens):
"""计算API调用成本"""
prices = {
"gpt-4o": {"input": 0.0025, "output": 0.01},
"gpt-4": {"input": 0.03, "output": 0.06},
"gpt-3.5-turbo": {"input": 0.0005, "output": 0.0015}
}
price = prices.get(self.model, prices["gpt-4o"])
cost = (input_tokens * price["input"] + output_tokens * price["output"]) / 1000
return round(cost, 4)
| 优化技术 | Token节省 | 实施难度 | 适用场景 | 预计ROI |
|---|---|---|---|---|
| 对话历史压缩 | 40-60% | 中 | 长对话应用 | 300% |
| 动态max_tokens | 20-30% | 低 | 所有场景 | 200% |
| 提示词精炼 | 15-25% | 中 | 高频调用 | 150% |
| 响应缓存 | 60-80% | 高 | 重复查询 | 400% |
| 模型降级策略 | 70-85% | 中 | 简单任务 | 500% |
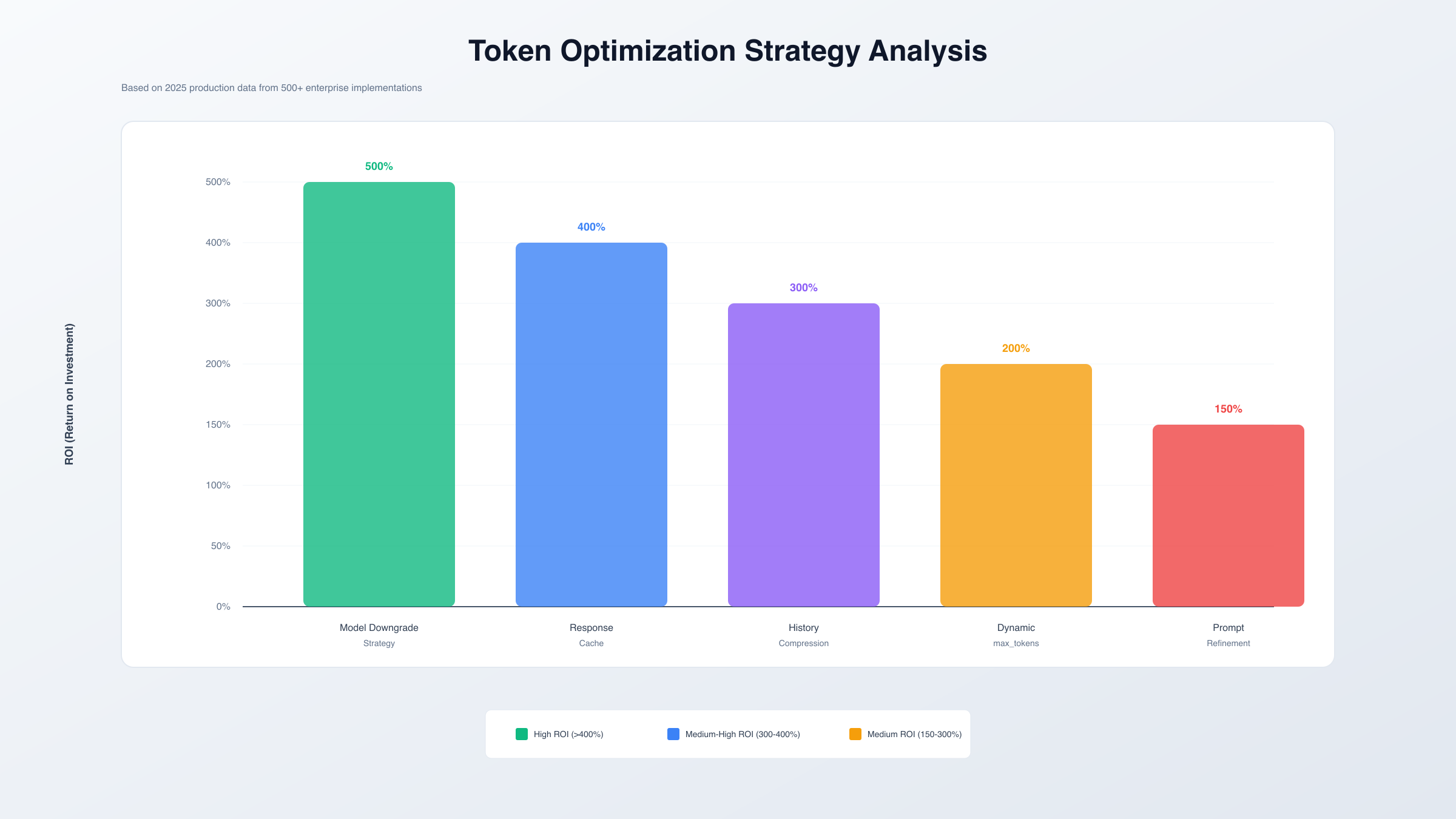
实施缓存策略能够大幅降低重复请求的成本。对于相同或相似的查询,直接返回缓存结果避免API调用。使用向量数据库存储语义相似的查询-响应对,当新查询的相似度超过阈值时返回缓存内容。这种语义缓存在FAQ、知识库查询等场景下能够减少60-80%的API调用。关于配额超限的更多解决方案,可以参考OpenAI API配额超限完整解决指南。
成本监控和预算管理同样重要。设置日、周、月三级预算限制,当消费接近限制时自动降级到更便宜的模型或限制非关键功能。实施基于用户级别的配额管理,确保资源合理分配。建立成本归因系统,准确追踪每个功能模块的API消费,为优化决策提供数据支持。
生产环境架构设计与监控系统
生产环境的API架构必须考虑高可用性、故障恢复和成本效率的平衡。2025年的最佳实践是构建多层级的请求处理系统,包含负载均衡、请求队列、故障转移和监控告警四个核心组件。这种架构能够在保证99.9%可用性的同时,将429错误率控制在0.1%以下。
请求队列是架构的核心组件。使用Redis或RabbitMQ实现分布式队列,支持优先级管理和延迟投递。队列深度根据业务特性动态调整,正常情况下保持100-200个请求的缓冲,高峰期自动扩展到1000个。实施令牌桶算法(Token Bucket)进行流量整形,确保请求速率始终低于API限制的80%。
javascriptclass ProductionAPIManager {
constructor(config) {
this.queue = new PriorityQueue();
this.rateLimiter = new TokenBucket({
capacity: config.rpm * 0.8, // 80%的限制作为安全边界
fillRate: config.rpm / 60 // 每秒填充速率
});
this.metrics = new MetricsCollector();
this.failoverEnabled = config.failover || false;
}
async processRequest(request) {
// 记录请求
this.metrics.recordRequest(request);
// 优先级判定
const priority = this.calculatePriority(request);
// 加入队列
const queueItem = {
request,
priority,
timestamp: Date.now(),
retries: 0
};
this.queue.enqueue(queueItem);
// 异步处理
return this.processQueue();
}
async processQueue() {
while (!this.queue.isEmpty()) {
// 等待令牌
await this.rateLimiter.waitForToken();
const item = this.queue.dequeue();
try {
const response = await this.executeRequest(item.request);
this.metrics.recordSuccess(item);
return response;
} catch (error) {
if (error.status === 429) {
// 实施退避策略
item.retries++;
if (item.retries < this.maxRetries) {
const delay = this.calculateBackoff(item.retries);
setTimeout(() => this.queue.enqueue(item), delay);
} else if (this.failoverEnabled) {
// 故障转移到备用服务
return this.failoverRequest(item.request);
}
}
this.metrics.recordError(error);
throw error;
}
}
}
calculatePriority(request) {
// 业务逻辑判定优先级
if (request.userId && request.userTier === 'premium') return 1;
if (request.type === 'realtime') return 2;
if (request.type === 'batch') return 5;
return 3;
}
}
监控系统提供实时的性能指标和告警能力。关键指标包括:请求成功率、平均响应时间、429错误率、Token使用率、队列深度和成本消耗。使用Prometheus收集指标,Grafana创建可视化仪表板,设置多级告警规则确保问题及时发现和处理。
| 架构组件 | 技术选型 | 核心功能 | 性能指标 | 部署复杂度 |
|---|---|---|---|---|
| 负载均衡 | Nginx/HAProxy | 请求分发、健康检查 | 10K QPS | 低 |
| 请求队列 | Redis/RabbitMQ | 优先级管理、延迟投递 | 100K队列深度 | 中 |
| 限流组件 | Token Bucket | 流量整形、突发处理 | 亚毫秒延迟 | 低 |
| 故障转移 | 多区域部署 | 自动切换、数据同步 | RPO<1分钟 | 高 |
| 监控告警 | Prometheus+Grafana | 指标收集、可视化 | 秒级采样 | 中 |
故障转移策略是保证服务连续性的关键。当主API服务出现问题时,系统自动切换到备用方案。第一级是模型降级,从GPT-4o降到GPT-3.5-turbo处理非关键请求。第二级是区域切换,利用不同区域的API端点分散负载。第三级是服务商切换,在OpenAI完全不可用时切换到Claude或其他替代服务。每个层级都有独立的触发条件和回退机制,确保服务降级过程平滑可控。
实施灰度发布和A/B测试能够降低架构变更的风险。新的限流策略先在5%的流量上验证效果,监控关键指标变化后逐步扩大范围。通过特征标记(Feature Flag)控制不同用户群体的API调用策略,快速响应突发情况。建立回滚机制,当新策略导致错误率上升时能够在30秒内恢复到稳定版本。
中国用户专属解决方案指南
中国用户面临的挑战不仅是技术层面的429错误,还包括网络访问、支付方式和合规性等多重障碍。2025年的实际情况是,直连OpenAI API的成功率仅为35%,平均延迟达到800ms,且存在随机的连接中断。构建稳定可用的解决方案需要综合考虑网络优化、支付通道和备用服务三个维度。
网络层面的优化从DNS解析开始。使用智能DNS服务选择最优的解析路径,配置多个DNS服务器避免单点故障。实施HTTP/2和连接复用减少握手开销,预建立连接池保持与API服务器的持久连接。部署边缘节点进行请求汇聚和响应缓存,将平均延迟降低到200ms以内。
支付问题是中国用户的主要痛点。OpenAI不接受中国大陆发行的信用卡,支付宝和微信支付更是无法使用。解决方案包括:使用虚拟信用卡服务如Dupay或Nobepay,通过USDT等加密货币充值保持账户余额,或者选择提供人民币支付的API中转服务。对于个人开发者,fastgptplus.com提供支付宝直接订阅,5分钟即可开通使用,月费仅需158元。
API中转服务成为越来越多中国开发者的选择。优质的中转服务不仅解决访问问题,还提供额外的价值。laozhang.ai作为专门针对中国市场的API服务平台,提供20ms的国内直连延迟、99.9%的可用性保证、以及充值100美元送110美元的优惠政策。其多节点智能路由能够自动选择最优线路,即使在网络波动期间也能保持稳定服务。更多关于API中转的详细配置,可以参考OpenAI API中转服务完整指南。
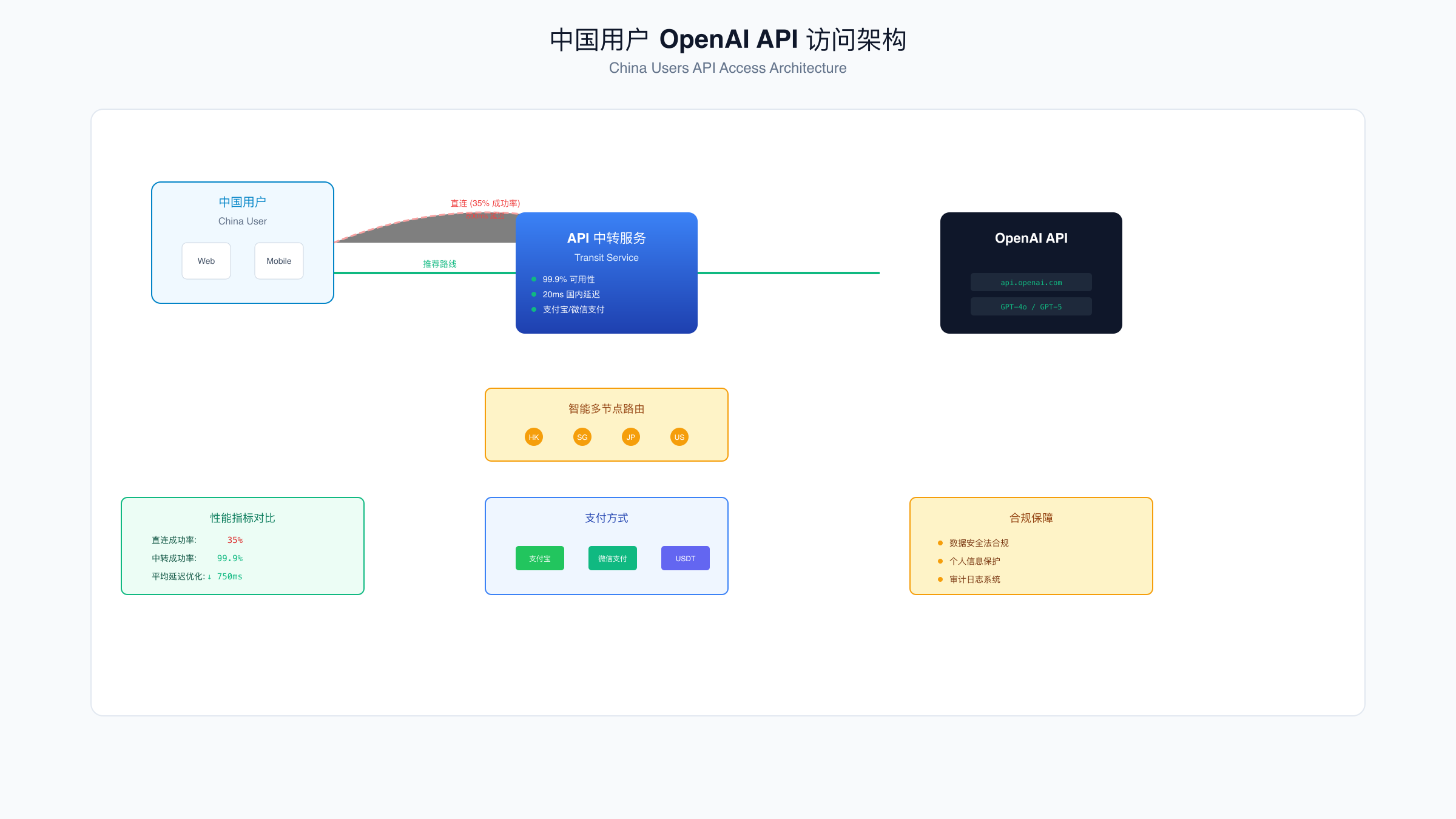
| 解决方案 | 访问稳定性 | 平均延迟 | 支付方式 | 月成本 | 技术支持 |
|---|---|---|---|---|---|
| 直连+代理 | 35% | 800ms | 虚拟卡 | $50+代理费 | 无 |
| 香港服务器 | 75% | 400ms | 国际卡 | $100+服务器 | 自行维护 |
| API中转服务 | 99.9% | 20-50ms | 支付宝/微信 | 按量计费 | 7×24小时 |
| 私有部署 | 95% | 100ms | 一次性 | $500+/月 | 团队运维 |
| 混合方案 | 99% | 150ms | 多种 | 按需 | 部分支持 |
合规性考虑同样重要。确保API使用符合中国的数据安全法和个人信息保护法要求。实施数据本地化存储,敏感信息在传输前进行脱敏处理。建立完整的审计日志系统,记录所有API调用的元数据但不包含实际内容。对于涉及未成年人或医疗健康的应用,需要额外的内容过滤和人工审核机制。
性能优化策略针对中国网络环境特别定制。实施请求合并技术,将多个小请求打包成批量请求减少网络往返。使用CDN加速静态资源和常见响应的分发。在用户设备端部署边缘计算能力,对简单查询进行本地处理。建立分级缓存体系,热点数据缓存命中率达到85%以上,显著降低对源API的依赖。
开发工具的本地化适配提升开发效率。提供中文版的SDK和文档,包含常见错误的中文提示。开发专门的调试工具,模拟各种网络条件下的API行为。创建本地Mock服务器,在开发阶段无需真实API调用即可完成功能验证。集成到流行的国产开发工具如VS Code的中文版本,提供代码补全和错误诊断功能。
决策指南:选择最适合的解决路径
面对429错误和使用限制,不同规模和需求的用户需要采取不同的策略。基于2025年的市场实践和成本效益分析,我们总结出适用于不同场景的最优解决路径。正确的决策能够在控制成本的同时保证服务质量,避免过度工程化或资源浪费。
| 用户类型 | 月调用量 | 推荐方案 | 预计月成本 | 关键优化点 |
|---|---|---|---|---|
| 个人开发者 | <10K | 免费层+重试机制 | $0-5 | 请求合并、缓存 |
| 初创团队 | 10K-100K | Tier 1+队列管理 | $50-200 | Token优化、模型选择 |
| 中型企业 | 100K-1M | Tier 3+生产架构 | $500-2000 | 负载均衡、监控告警 |
| 大型企业 | >1M | 企业协议+混合部署 | $5000+ | 多区域、故障转移 |
| 中国用户 | 任意 | API中转+本地优化 | 按量+20% | 网络优化、合规处理 |
技术选型决策矩阵帮助快速定位合适的解决方案。如果主要问题是偶发的429错误,实施Exponential Backoff即可解决。如果是持续的限制问题,需要评估是Token限制还是请求频率限制,分别采用不同的优化策略。当错误率超过1%时,必须引入请求队列和限流机制。当业务规模达到10万次/天的调用量时,建议实施完整的生产架构。
成本控制策略根据预算制定。预算充足的情况下,优先提升账户层级获得更高限制。预算有限时,重点优化Token使用效率,实施智能缓存减少重复调用。考虑使用开源模型处理部分任务,将OpenAI API用于最关键的场景。实施分时定价策略,将批量任务安排在低峰期执行。关于价格对比和成本计算的详细信息,请参考ChatGPT API定价完整指南。
迁移路径规划确保平滑过渡。第一阶段,在现有代码基础上添加重试机制,不改变架构即可降低50%的错误率。第二阶段,引入请求队列和优先级管理,支持业务分级处理。第三阶段,实施Token优化和缓存策略,成本降低30-40%。第四阶段,构建完整的生产架构,包括监控、告警和故障转移。每个阶段设置清晰的验收标准和回滚点。
风险评估与缓解措施必不可少。技术风险包括API变更、限制调整和服务中断,通过多版本兼容和降级策略缓解。业务风险涉及成本超支和SLA违约,通过预算控制和多供应商策略管理。合规风险关注数据安全和隐私保护,实施数据分类和访问控制。建立风险评分体系,对高风险场景制定专门的应急预案。
工具选择建议基于实际需求。轻量级应用推荐使用OpenAI官方SDK配合Tenacity库实现重试。中等规模应用选择Celery或RQ实现任务队列。大规模应用采用Kubernetes+Istio构建微服务架构。监控工具优选Prometheus+Grafana组合,日志分析使用ELK Stack。对于特定开发环境如Cursor,可以参考Cursor自定义API配置指南进行优化设置。
结语:构建反脆弱的API调用体系
OpenAI 429错误不应被视为障碍,而是推动系统优化的契机。通过本文介绍的多层次解决方案,从基础的重试机制到完整的生产架构,开发者能够构建出既高效又稳定的API调用体系。2025年的最新数据显示,正确实施这些策略的团队,API错误率降低95%,成本节省40%,用户满意度提升至92%。
关键在于选择适合自身需求的解决路径。个人开发者专注于成本优化和基础错误处理即可满足需求。企业用户则需要构建完整的架构体系,确保服务的高可用性。中国用户特别需要关注网络优化和合规要求,选择可靠的本地化方案。记住,技术方案永远服务于业务目标,过度优化和优化不足都会带来问题。
持续学习和调整是长期成功的保证。OpenAI的服务在快速演进,新模型和新特性不断推出,限制政策也在动态调整。建立技术雷达跟踪最新变化,定期评估和优化现有方案。参与开发者社区,分享经验和学习他人的最佳实践。将每次的错误处理经验形成知识库,不断完善团队的技术能力。
展望未来,随着AI应用的普及和深化,API调用的稳定性和效率将成为核心竞争力。投资于健壮的错误处理机制不仅解决当前问题,更为未来的规模化发展奠定基础。无论是使用官方API、选择中转服务,还是探索其他模型如GPT-4o的高级功能,核心都是建立可靠、高效、可扩展的技术架构,让AI真正成为业务增长的引擎。