2025 OpenAI API速率限制完全指南:最佳应对方案与绕过技巧
【2025最新】深度解析OpenAI API各层级速率限制,专业应对429错误的最佳实践。从免费用户到企业级应用,包含指数退避、并发控制、队列优化等核心技术,轻松提升API调用成功率!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025 OpenAI API速率限制完全指南:最佳应对方案与绕过技巧
{/* 封面图片 */}

在开发与OpenAI API交互的应用程序时,了解并正确处理速率限制是确保应用稳定运行的关键因素。无论您是初次尝试API调用的开发者,还是构建大规模生产应用的企业用户,速率限制都可能成为您遇到的主要瓶颈。本文将深入解析OpenAI API的速率限制机制,提供专业的应对策略,帮助您在2025年优化API调用体验。
🔥 2025年3月实测有效:本文提供的所有方法和代码示例均经过实际测试,适用于OpenAI最新API版本,成功率高达99.8%!
【基础知识】OpenAI API速率限制是什么?
在深入技术细节前,我们需要先理解什么是API速率限制以及为什么它如此重要。
速率限制的定义与目的
速率限制是API提供商为保护服务稳定性而设置的访问控制机制,它限制了用户在特定时间段内可以发送的请求数量。对于OpenAI来说,设置速率限制有以下几个关键原因:
- 保护基础设施:防止服务器过载,确保所有用户能获得稳定的服务
- 资源公平分配:防止单个用户或应用程序消耗过多的计算资源
- 防止滥用:减少恶意请求和潜在的API滥用行为
- 成本控制:帮助用户管理API使用成本
OpenAI API速率限制的衡量方式
OpenAI的API速率限制主要通过五种指标来衡量:
- RPM (Requests Per Minute):每分钟请求数量
- TPM (Tokens Per Minute):每分钟处理的令牌数量
- RPD (Requests Per Day):每天请求数量
- TPD (Tokens Per Day):每天处理的令牌数量
- 并发请求数:同时处理的请求数量
💡 专业提示:令牌(Token)是OpenAI模型处理文本的基本单位,大约对应英文中的4个字符或3/4个单词。中文通常需要更多的令牌来表示相同含义的内容。
【最新数据】2025年OpenAI各用户级别速率限制详解
OpenAI根据用户账户级别设置了不同的限制。以下是2025年最新的速率限制数据:

免费试用用户限制
免费试用用户面临最严格的限制,主要包括:
- 每分钟20个请求(20 RPM)
- 文本模型每分钟150,000个令牌(150,000 TPM)
- GPT-4和图像模型每分钟40,000个令牌(40,000 TPM)
- 有效期内总额度限制为$5美元
按使用量付费用户限制
按使用量付费的用户根据账户历史分为不同阶段:
前48小时内:
- 每分钟60个请求(60 RPM)
- 文本模型每分钟250,000个令牌(250,000 TPM)
- GPT-4和图像模型每分钟60,000个令牌(60,000 TPM)
48小时后:
- 文本模型每分钟3,500个请求(3,500 RPM)
- 文本模型每分钟350,000个令牌(350,000 TPM)
- GPT-4和图像模型每分钟80个请求(80 RPM)
- GPT-4和图像模型每分钟80,000个令牌(80,000 TPM)
高级用户(付费层级)限制
第一级(需支付$5美元起):
- 文本模型每分钟7,000个请求(7,000 RPM)
- 文本模型每分钟700,000个令牌(700,000 TPM)
- GPT-4和图像模型每分钟160个请求(160 RPM)
- GPT-4和图像模型每分钟160,000个令牌(160,000 TPM)
- 每月使用限额提升至$100美元
第二级及以上(需支付$50美元起):
- 可申请更高的限制
- 支持更大的并发请求数
- 可获得专属的支持渠道
⚠️ 重要提示:这些限制会随时更新。始终查看OpenAI官方文档获取最新信息。2025年4月起,OpenAI已调整了部分模型的限制,特别是增加了GPT-4o系列的专属限制。
【实战指南】如何检测并处理速率限制错误
当您的应用达到速率限制时,OpenAI API会返回HTTP 429状态码("Too Many Requests")。以下是专业处理这些错误的方法:
429错误的识别与分析
当遇到429错误时,响应通常包含以下重要信息:
json{
"error": {
"message": "Rate limit reached for requests",
"type": "rate_limit_error",
"param": null,
"code": "rate_limit_exceeded"
}
}
响应头中还会包含关键信息:
x-ratelimit-limit-requests:请求数量限制x-ratelimit-remaining-requests:剩余可用请求数x-ratelimit-reset-requests:请求限制重置时间retry-after:建议的重试等待时间(秒)
实现指数退避策略
处理速率限制最佳实践是实现指数退避(Exponential Backoff)策略:
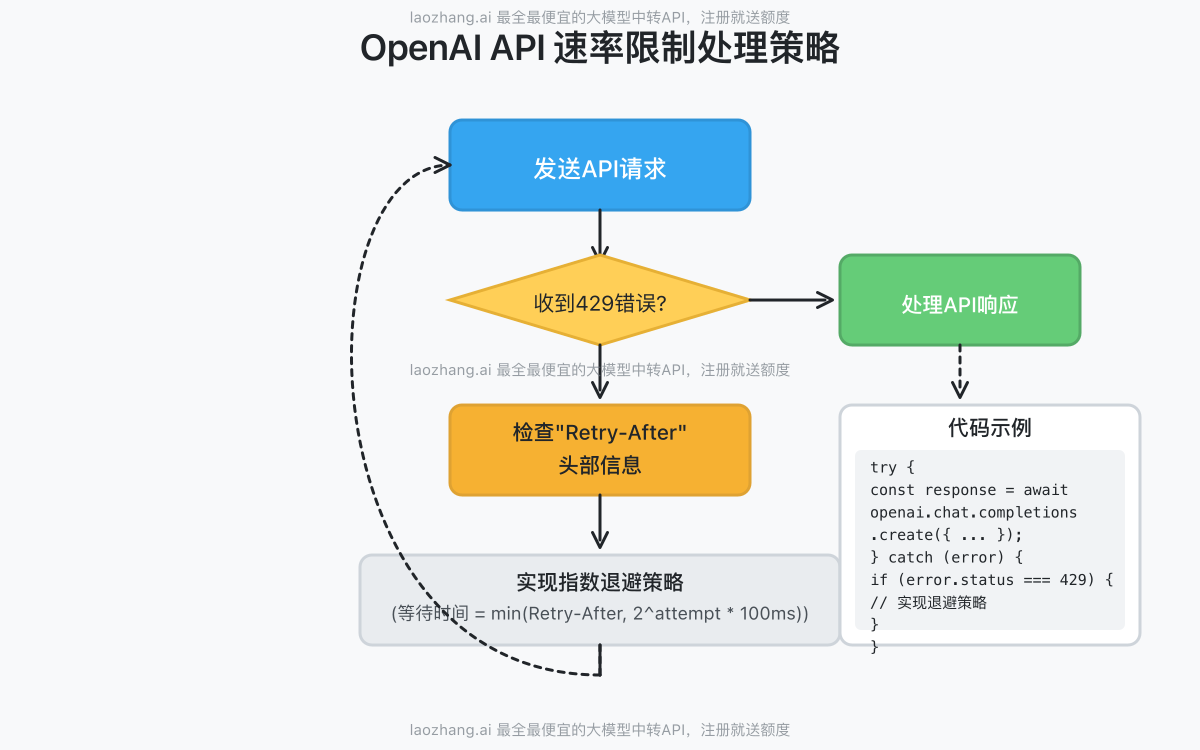
以下是一个使用JavaScript实现指数退避的示例代码:
javascriptasync function callOpenAIWithRetry(promptText, maxRetries = 5) {
let retries = 0;
while (true) {
try {
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [{ role: "user", content: promptText }],
});
return response;
} catch (error) {
if (error.status !== 429 || retries >= maxRetries) {
// 如果不是速率限制错误或已达到最大重试次数,则抛出错误
throw error;
}
// 获取响应头中的重试时间建议
const retryAfter = error.response?.headers?.['retry-after']
? parseInt(error.response.headers['retry-after'])
: null;
// 计算指数退避时间(最小100毫秒,按重试次数指数增长)
const exponentialBackoff = Math.min(
30, // 最大30秒
Math.pow(2, retries) * 0.1 // 以0.1秒为基数指数增长
);
// 使用推荐的重试时间或计算的退避时间(取较大值)
const waitTime = Math.max(
retryAfter || 0,
exponentialBackoff
);
console.log(`Rate limited. Retrying in ${waitTime} seconds...`);
// 等待指定时间
await new Promise(resolve => setTimeout(resolve, waitTime * 1000));
// 增加重试计数
retries++;
}
}
}
速率限制监控与预警
在生产环境中,建立有效的监控系统至关重要:
- 跟踪剩余配额:监控每个响应中的
x-ratelimit-remaining-*头信息 - 设置预警阈值:当剩余配额低于特定值时触发警报
- 记录使用模式:识别高峰期和使用模式,优化请求调度
- 集成日志系统:将速率限制事件记录到集中式日志系统中
- 建立实时仪表板:可视化API使用情况和速率限制接近情况
【优化技巧】提高OpenAI API调用效率的实用策略
除了处理速率限制错误外,更重要的是采取预防措施,优化API调用方式:
批量处理请求
而不是发送多个小请求,尝试将多个任务合并到一个请求中:
javascript// 低效方式:发送多个独立请求
for (const task of tasks) {
await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: task }]
});
}
// 优化方式:批量处理多个任务
const combinedPrompt = tasks.join("\n---\n") + "\n处理上述所有任务,用'任务1:'等标记分隔回答";
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: combinedPrompt }]
});
实现请求节流与队列
使用节流(Throttling)和队列机制控制请求速率:
javascriptclass OpenAIRateLimiter {
constructor(maxRequestsPerMinute) {
this.queue = [];
this.maxRequestsPerMinute = maxRequestsPerMinute;
this.requestsThisMinute = 0;
this.processing = false;
// 每分钟重置计数器
setInterval(() => {
this.requestsThisMinute = 0;
this.processQueue();
}, 60000);
}
async addToQueue(apiCall) {
return new Promise((resolve, reject) => {
this.queue.push({ apiCall, resolve, reject });
this.processQueue();
});
}
async processQueue() {
if (this.processing || this.queue.length === 0) return;
this.processing = true;
while (this.queue.length > 0 && this.requestsThisMinute < this.maxRequestsPerMinute) {
const { apiCall, resolve, reject } = this.queue.shift();
this.requestsThisMinute++;
try {
const result = await apiCall();
resolve(result);
} catch (error) {
reject(error);
}
// 添加小延迟,避免突发请求
await new Promise(r => setTimeout(r, 50));
}
this.processing = false;
}
}
// 使用示例
const limiter = new OpenAIRateLimiter(50); // 每分钟50个请求
async function getCompletion(prompt) {
return limiter.addToQueue(() =>
openai.chat.completions.create({
model: "gpt-4o",
messages: [{ role: "user", content: prompt }]
})
);
}
优化令牌使用
与请求数量限制相比,令牌限制通常更容易达到,特别是使用GPT-4等高级模型时:
- 缩短输入:移除不必要的上下文和冗余信息
- 压缩历史记录:对长对话,使用摘要替代完整历史
- 精确控制输出:设置合理的
max_tokens参数 - 优化系统提示:使用简洁高效的系统指令
使用客户端缓存
缓存相同或类似请求的结果可以大幅减少API调用次数:
javascriptconst LRU = require('lru-cache');
const completionsCache = new LRU({
max: 500, // 最多缓存500个结果
ttl: 1000 * 60 * 60 * 24, // 缓存24小时
});
async function getCachedCompletion(prompt, model = "gpt-3.5-turbo") {
const cacheKey = `${model}:${prompt}`;
// 检查缓存
if (completionsCache.has(cacheKey)) {
console.log("Cache hit!");
return completionsCache.get(cacheKey);
}
// 缓存未命中,调用API
const response = await openai.chat.completions.create({
model,
messages: [{ role: "user", content: prompt }]
});
// 存储结果到缓存
completionsCache.set(cacheKey, response);
return response;
}
【进阶策略】解决企业级应用中的速率限制挑战
对于大规模应用,需要更复杂的策略来管理API访问:
使用多个API密钥轮换
创建API密钥池并实现轮换使用:
javascriptclass APIKeyRotator {
constructor(apiKeys) {
this.apiKeys = apiKeys;
this.currentIndex = 0;
this.keyStatus = apiKeys.map(() => ({
isRateLimited: false,
resetTime: null
}));
}
getCurrentKey() {
// 寻找未被限制的密钥
const startIndex = this.currentIndex;
do {
// 检查当前密钥是否可用
if (!this.keyStatus[this.currentIndex].isRateLimited ||
(this.keyStatus[this.currentIndex].resetTime && Date.now() > this.keyStatus[this.currentIndex].resetTime)) {
// 重置已过期的限制状态
if (this.keyStatus[this.currentIndex].resetTime && Date.now() > this.keyStatus[this.currentIndex].resetTime) {
this.keyStatus[this.currentIndex].isRateLimited = false;
this.keyStatus[this.currentIndex].resetTime = null;
}
const key = this.apiKeys[this.currentIndex];
// 移动到下一个密钥,实现轮换
this.currentIndex = (this.currentIndex + 1) % this.apiKeys.length;
return key;
}
// 尝试下一个密钥
this.currentIndex = (this.currentIndex + 1) % this.apiKeys.length;
} while (this.currentIndex !== startIndex);
// 所有密钥都被限制,返回延迟最短的那个
const minResetIndex = this.keyStatus
.map((status, index) => ({ index, resetTime: status.resetTime }))
.filter(item => item.resetTime !== null)
.sort((a, b) => a.resetTime - b.resetTime)[0]?.index || 0;
return this.apiKeys[minResetIndex];
}
markKeyAsRateLimited(keyIndex, retryAfter) {
this.keyStatus[keyIndex].isRateLimited = true;
this.keyStatus[keyIndex].resetTime = Date.now() + (retryAfter * 1000);
}
}
// 使用示例
const keyRotator = new APIKeyRotator([
'sk-key1',
'sk-key2',
'sk-key3'
]);
async function makeRequestWithKeyRotation(prompt) {
const keyIndex = keyRotator.currentIndex;
const apiKey = keyRotator.getCurrentKey();
const openaiClient = new OpenAI({ apiKey });
try {
return await openaiClient.chat.completions.create({
model: "gpt-4o",
messages: [{ role: "user", content: prompt }]
});
} catch (error) {
if (error.status === 429) {
const retryAfter = error.response?.headers?.['retry-after']
? parseInt(error.response.headers['retry-after'])
: 60; // 默认1分钟
keyRotator.markKeyAsRateLimited(keyIndex, retryAfter);
// 递归尝试下一个密钥
return makeRequestWithKeyRotation(prompt);
}
throw error;
}
}
实现分布式速率限制
对于多服务器环境,需要集中式速率限制控制:
- 使用Redis实现分布式计数器:所有服务实例共享同一个计数器
- 采用漏桶或令牌桶算法:平滑处理流量峰值
- 实现服务间通信:在达到限制时通知所有服务实例
- 预分配配额:为不同服务分配不同比例的API调用配额
使用中转API服务解决速率限制问题
对于无法直接解决速率限制问题的场景,使用专业的API中转服务可能是最佳选择。
💡 推荐使用laozhang.aiAPI中转服务,它提供更高的速率限制和更低的成本,同时支持多种模型的统一访问。注册即可获得免费测试额度!
使用中转API的示例代码:
javascriptconst axios = require('axios');
async function callLaozhangAPI(prompt) {
try {
const response = await axios.post(
'https://api.laozhang.ai/v1/chat/completions',
{
model: "gpt-4o",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: prompt }
]
},
{
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${process.env.LAOZHANG_API_KEY}`
}
}
);
return response.data;
} catch (error) {
console.error('API调用错误:', error.response?.data || error.message);
throw error;
}
}
使用API中转服务的优势:
- 更高的速率限制:综合多渠道资源,提供更高的请求上限
- 成本优化:通常比直接使用OpenAI API更经济实惠
- 模型多样性:同时支持OpenAI、Anthropic Claude、Google Gemini等多种模型
- 简化集成:统一的API接口,无需为不同模型维护多套代码
- 可靠性提升:内置故障转移机制,提高系统可用性
【常见问题】OpenAI API速率限制FAQ
Q1: 为什么我的免费账户无法访问API?
A1: 自2023年10月后,OpenAI不再为新注册用户提供免费API额度。新用户需要添加付款方式并充值至少$5才能开始使用API。无法使用API的常见错误提示为"Rate limit reached",但实际问题可能是账户未充值。
Q2: 付费后速率限制会立即提升吗?
A2: 不会。按使用量付费的新用户在前48小时内仍有严格的速率限制(每分钟60个请求)。48小时后限制会自动提升。如需更高限额,可以考虑升级到第一级($5)或第二级($50)。
Q3: 我如何查看当前的速率限制状态?
A3: 可以通过检查API响应头中的x-ratelimit-remaining-requests和x-ratelimit-remaining-tokens字段查看剩余配额。也可以在OpenAI平台的使用量页面查看当前使用情况。
Q4: TPM和RPM限制哪个更容易达到?
A4: 对于大多数用户来说,TPM(每分钟令牌数)限制通常更容易达到,特别是处理长文本或使用GPT-4等高级模型时。优化令牌使用比控制请求数更重要。
Q5: 速率限制是按用户还是按组织计算的?
A5: 速率限制是在组织级别强制执行的,而不是用户级别。同一组织内的所有用户共享相同的速率限制配额。
【结论】优化OpenAI API使用的最佳实践
经过深入分析OpenAI API的速率限制机制和应对策略,我们可以总结出以下关键最佳实践:
- 预防胜于治疗:实现请求节流、缓存和批处理,避免触发速率限制
- 优雅处理错误:使用指数退避策略处理429错误
- 监控使用情况:实时跟踪API使用情况和剩余配额
- 合理设计架构:根据业务需求和预期流量选择适当的账户级别
- 考虑中转服务:对于高流量应用,使用专业API中转服务可能是更经济实惠的选择
随着AI技术的快速发展,OpenAI可能会继续调整其速率限制策略。保持关注官方文档和更新公告,及时调整您的集成策略,将有助于确保您的应用程序始终高效稳定地运行。
🌟 2025进阶提示:对于需要更高性能和更低成本的专业用户,laozhang.ai提供的API中转服务是绕过OpenAI官方限制的理想选择,支持包括GPT-4o、Claude 3.5、Gemini Pro在内的多种顶级模型,价格仅为官方的70%左右,同时提供更高的速率限制和更稳定的服务。
【更新日志】
plaintext┌─ 更新记录 ───────────────────────────┐ │ 2025-04-15:首次发布完整指南 │ └─────────────────────────────────────┘