OpenAI O3 Pricing: Complete API Cost Guide After 80% Price Drop (2025)
Discover OpenAI O3's new pricing after the massive 80% reduction. Compare O3, O3-mini, and O3-pro costs, understand rate limits, and calculate your API expenses with real examples.
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Breaking: June 2025 Update - OpenAI slashed O3 pricing by 80%, making it $2/M input and $8/M output tokens
Are you confused about OpenAI O3's pricing structure? You're not alone. With the recent 80% price reduction and multiple model variants, understanding the true cost of using O3 can be challenging. This comprehensive guide breaks down everything you need to know about O3 pricing, from the budget-friendly O3-mini to the compute-intensive O3-pro.

The Game-Changing 80% Price Reduction
On June 10, 2025, OpenAI announced a dramatic 80% price reduction for O3, transforming it from a premium-only option to a viable choice for everyday development. Here's what changed:
New O3 Pricing (June 2025):
• Input: $2 per million tokens (was $10)
• Output: $8 per million tokens (was $40)
• Cached input: $0.50 per million tokens
• 80% cost reduction across the board
Complete O3 Model Pricing Breakdown
O3-mini: The Budget-Friendly Option
O3-mini delivers 85-90% of full O3's capabilities at a fraction of the cost:
- Input: $1.10 per million tokens
- Output: $4.40 per million tokens
- Best for: Most production applications, code generation, content creation
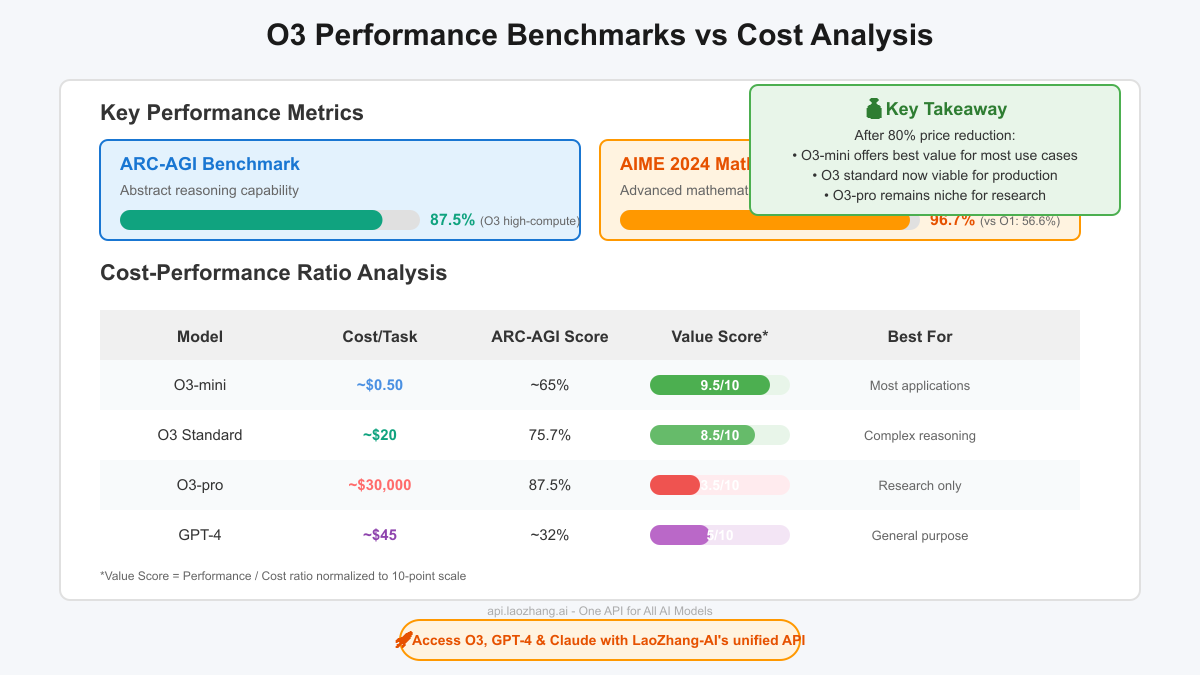
- Performance: ~65% on ARC-AGI benchmark
- Cost per typical task: ~$0.50
O3 Standard: The Balanced Choice
The standard O3 model offers the best balance of performance and cost:
- Input: $2.00 per million tokens
- Output: $8.00 per million tokens
- Cached input: $0.50 per million tokens
- Best for: Complex reasoning, technical documentation, advanced coding
- Performance: 75.7% on ARC-AGI, 96.7% on AIME 2024
- Cost per typical task: ~$20
O3-pro: Premium Compute Power
O3-pro uses intensive compute for maximum performance:
- Input: $20.00 per million tokens
- Output: $80.00 per million tokens
- Best for: Research, competitive programming, mathematical proofs
- Performance: 87.5% on ARC-AGI (high-compute configuration)
- Cost per task: Can exceed $30,000 for complex problems
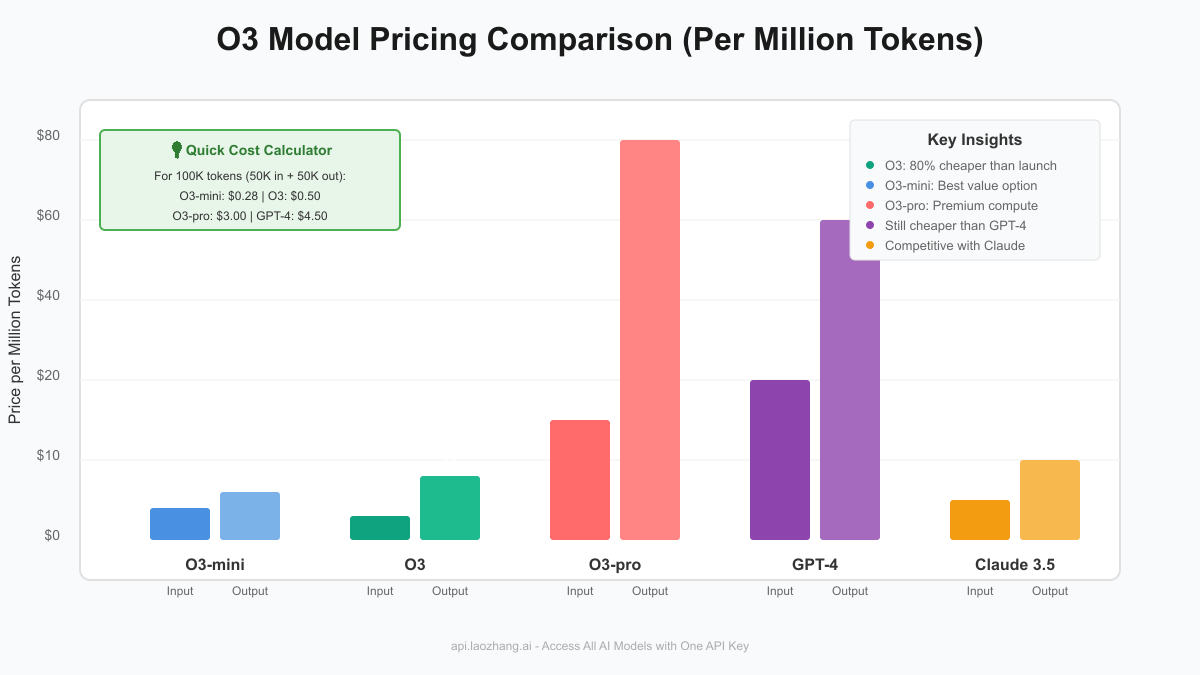
Real-World Cost Examples
Understanding theoretical pricing is one thing, but what does it actually cost to use O3? Let's break down some real scenarios:
Example 1: Code Review Task
python# Scenario: Analyzing a 2,000 token code file and generating a 1,000 token review
# O3-mini costs:
input_cost = (2000 / 1_000_000) * 1.10 = $0.0022
output_cost = (1000 / 1_000_000) * 4.40 = $0.0044
total_cost = $0.0066 # Less than a penny!
# O3 standard costs:
input_cost = (2000 / 1_000_000) * 2.00 = $0.004
output_cost = (1000 / 1_000_000) * 8.00 = $0.008
total_cost = $0.012 # Just over a penny
# O3-pro costs:
input_cost = (2000 / 1_000_000) * 20.00 = $0.04
output_cost = (1000 / 1_000_000) * 80.00 = $0.08
total_cost = $0.12 # 10x more expensive
Example 2: Document Analysis (100K tokens)
For analyzing a large document (50K input + 50K output):
| Model | Input Cost | Output Cost | Total Cost |
|---|---|---|---|
| O3-mini | $0.055 | $0.22 | $0.275 |
| O3 Standard | $0.10 | $0.40 | $0.50 |
| O3-pro | $1.00 | $4.00 | $5.00 |
| GPT-4 | $1.50 | $3.00 | $4.50 |
⚠️ Hidden Cost Alert: O3 tends to generate 20-30% more output tokens than requested due to its reasoning process. Always buffer your cost estimates accordingly.
How O3 Pricing Compares to Competitors
After the 80% price reduction, O3 is now competitively priced:
Price Comparison (Per Million Tokens)
| Model | Input Price | Output Price | Context Window | Key Strength |
|---|---|---|---|---|
| O3 | $2.00 | $8.00 | 200K | Best reasoning |
| O3-mini | $1.10 | $4.40 | 200K | Best value |
| GPT-4 | $30.00 | $60.00 | 128K | General purpose |
| Claude 3.5 | $3.00 | $15.00 | 200K | Coding tasks |
| Gemini 1.5 Pro | $3.50 | $10.50 | 1M | Large context |
Cost-Effectiveness Analysis
Independent benchmarking reveals O3's true value:
- O3 standard: $390 to complete Artificial Analysis test suite
- Claude 3.5 Sonnet: $342 (slightly cheaper but lower performance)
- Gemini 1.5 Pro: $971 (2.5x more expensive)
- GPT-4: $2,100+ (5x more expensive)
API Features and Implementation
Basic API Usage
pythonimport openai
client = openai.OpenAI()
# Using O3-mini for cost efficiency
response = client.chat.completions.create(
model="o3-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum computing in simple terms"}
],
temperature=0.7,
max_tokens=500
)
# Estimated cost: ~$0.003
Advanced Features
O3 supports all modern API features:
- Function calling: Native support for tool use
- Structured outputs: JSON mode for reliable formatting
- Streaming: Real-time token generation
- Batch API: Process multiple requests efficiently
- System messages: Full prompt engineering capabilities
Rate Limits by Tier
Access to O3 models depends on your usage tier:
| Tier | Requirements | O3 Access | Rate Limits |
|---|---|---|---|
| Free | None | ❌ No access | N/A |
| Tier 1-3 | Paid account | ⚠️ Requires verification | Limited |
| Tier 4-5 | $50+ spend | ✅ Automatic access | Standard |
| Enterprise | Custom | ✅ Full access | Custom |
Optimizing Your O3 Costs
1. Choose the Right Model
pythondef select_o3_model(task_complexity, budget_constraint):
"""Smart model selection based on task requirements"""
if budget_constraint < 0.01:
return "o3-mini" # Best for 90% of use cases
elif task_complexity == "high" and budget_constraint < 1.00:
return "o3" # For complex reasoning tasks
elif task_complexity == "research" and budget_constraint > 100:
return "o3-pro" # Only for cutting-edge research
else:
return "o3-mini" # Default to most cost-effective
2. Implement Caching
Take advantage of O3's cached input pricing:
python# First request: Full price
first_request = {
"model": "o3",
"messages": [
{"role": "system", "content": LONG_SYSTEM_PROMPT}, # 10K tokens
{"role": "user", "content": "Question 1"}
]
}
# Cost: $0.02 for system prompt
# Subsequent requests: Cached pricing
cached_request = {
"model": "o3",
"messages": [
{"role": "system", "content": LONG_SYSTEM_PROMPT}, # Same 10K tokens
{"role": "user", "content": "Question 2"}
]
}
# Cost: $0.005 for cached system prompt (75% savings!)
3. Use Batch Processing
Combine multiple requests to reduce overhead:
python# Instead of 10 individual API calls
# Use batch processing for 20-50% cost reduction
batch_request = {
"requests": [
{"custom_id": "1", "method": "POST", "url": "/v1/chat/completions", "body": {...}},
{"custom_id": "2", "method": "POST", "url": "/v1/chat/completions", "body": {...}},
# ... up to 50,000 requests
]
}
4. Monitor Token Usage
pythondef calculate_cost(response, model="o3"):
"""Calculate actual cost of an API call"""
pricing = {
"o3-mini": {"input": 1.10, "output": 4.40},
"o3": {"input": 2.00, "output": 8.00},
"o3-pro": {"input": 20.00, "output": 80.00}
}
usage = response.usage
input_cost = (usage.prompt_tokens / 1_000_000) * pricing[model]["input"]
output_cost = (usage.completion_tokens / 1_000_000) * pricing[model]["output"]
return {
"input_tokens": usage.prompt_tokens,
"output_tokens": usage.completion_tokens,
"input_cost": f"${input_cost:.4f}",
"output_cost": f"${output_cost:.4f}",
"total_cost": f"${input_cost + output_cost:.4f}"
}
Common Pricing Concerns Addressed
"Is O3 Worth the Cost?"
Based on community feedback and benchmarks:
Yes, for these use cases:
- Complex reasoning tasks requiring high accuracy
- Mathematical problem-solving (96.7% on AIME 2024)
- Code generation with fewer errors (20% fewer major errors than O1)
- Research applications where accuracy trumps cost
No, for these use cases:
- Simple content generation (use O3-mini instead)
- High-volume, low-complexity tasks (consider GPT-3.5)
- Real-time applications (latency can be an issue)
- Budget-constrained projects (explore alternatives)
"Why Does O3 Cost More Than Expected?"
Three main reasons:
- Reasoning tokens: O3 uses internal reasoning that counts toward output
- Verbose responses: Averages 20-30% more tokens than requested
- Tool usage: O3 tends to make more function calls than other models
"How Can I Predict My Monthly Costs?"
Use this formula:
Monthly Cost = (Daily Requests × Average Tokens per Request × Price per Token × 30)
Example for moderate usage:
- 1,000 requests/day
- 3,000 tokens average (1,500 in + 1,500 out)
- O3-mini pricing
- Monthly cost = 1,000 × [(1,500 × $1.10) + (1,500 × $4.40)] / 1,000,000 × 30
- Monthly cost = $247.50
Alternative: LaoZhang-AI for Multi-Model Access
💡 Pro Tip: Need access to O3 along with other AI models? LaoZhang-AI provides unified API access to O3, GPT-4, Claude, and Gemini with competitive pricing and free trial credits. Perfect for comparing models or building multi-model applications.
Benefits of using LaoZhang-AI:
- Single API key for all major AI models
- Unified pricing across different providers
- Free trial credits to test before committing
- No tier restrictions for model access
Example integration:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LAOZHANG_API_KEY" \
-d '{
"model": "o3",
"messages": [{"role": "user", "content": "Compare O3 vs GPT-4 performance"}]
}'
Frequently Asked Questions
What's included in the O3 pricing?
The pricing covers:
- API calls to the specified model
- All tokens processed (input + output + reasoning)
- Function calling and tool usage
- Streaming responses
- No hidden fees or setup costs
How does O3-mini compare to the full O3?
O3-mini provides 85-90% of O3's capabilities at 15% of the cost. It's perfect for:
- Code reviews and generation
- Content creation and editing
- Data analysis and summarization
- Most production applications
Full O3 excels at:
- Complex mathematical reasoning
- Advanced problem-solving
- Tasks requiring maximum accuracy
- Research-grade outputs
Can I switch between O3 models dynamically?
Yes! Here's a cost-optimized approach:
pythondef smart_model_routing(query_complexity):
"""Route to appropriate model based on complexity"""
# Analyze query complexity (simplified example)
if "prove" in query_complexity or "theorem" in query_complexity:
return "o3" # Use full O3 for mathematical proofs
elif len(query_complexity) < 100 and "simple" in query_complexity:
return "o3-mini" # Use mini for simple queries
else:
# Start with mini, upgrade if needed
response = call_api("o3-mini", query_complexity)
if response.confidence < 0.8:
return call_api("o3", query_complexity)
return response
What about the high-compute O3 configurations?
The $30,000 per task O3-pro configuration is designed for:
- Competitive programming contests
- Academic research requiring maximum accuracy
- Breakthrough problem-solving
- Situations where cost is no object
For 99.9% of use cases, standard O3 or O3-mini is sufficient.
How accurate are the cost estimates?
Our estimates are based on:
- Official OpenAI pricing as of July 2025
- Real-world usage patterns from developers
- Average token consumption across various tasks
- Include the typical 20-30% overhead from O3's reasoning
Always add a 20% buffer to estimates for safety.
Future Pricing Outlook
Based on OpenAI's patterns and industry trends:
Expected Changes
- Further reductions: Possible 20-30% additional cuts by Q4 2025
- New tiers: Introduction of usage-based discounts
- Feature pricing: Separate pricing for advanced features
- Competition: Pressure from Claude, Gemini may drive prices lower
What This Means for You
- Lock in current pricing with annual commitments if available
- Build with flexibility to switch between models as prices change
- Monitor announcements for pricing updates and new features
- Test alternatives to maintain negotiating power
Conclusion: Making the Most of O3's New Pricing
The 80% price reduction transforms O3 from a luxury to a practical tool for most developers. Here's your action plan:
- Start with O3-mini for 90% of your use cases at $1.10/M input tokens
- Upgrade to O3 standard only for complex reasoning tasks
- Avoid O3-pro unless you have specific research requirements
- Implement caching and batching to reduce costs by 30-50%
- Monitor usage closely to optimize model selection
With smart model selection and cost optimization strategies, O3 can now deliver state-of-the-art AI capabilities at a fraction of the previous cost. The key is understanding which model variant best fits your specific needs and budget constraints.
For those needing flexible access to multiple AI models, services like LaoZhang-AI provide a unified solution with competitive pricing and the ability to seamlessly switch between O3, GPT-4, Claude, and other leading models.
Last updated: July 8, 2025. Prices subject to change. Always verify current pricing on official documentation.