OpenAI Tokenizer完全指南:理解、使用与优化【2025实用教程】
【实测指南】深入解析OpenAI Tokenizer原理与应用技巧,掌握token计算方法、节省API费用,内附详细示例代码与实战经验。适用于GPT-4、GPT-3.5、Claude等模型,新手也能快速上手!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
OpenAI Tokenizer完全指南:理解、使用与优化【2025实用教程】
{/* 封面图片 */}

在大型语言模型(如GPT-4、GPT-3.5、Claude等)的使用过程中,"token"是一个关键概念,直接影响API调用成本、模型性能和生成质量。然而,许多开发者对tokenization的具体工作原理和优化方法知之甚少,导致不必要的API成本浪费或性能瓶颈。
🔥 2025年3月实测有效:本文提供OpenAI Tokenizer的全面解析,从基础概念到高级优化技巧,帮助你精确控制token用量,最高可节省30-50%的API费用!
【基础概念】什么是Token?为什么它如此重要?
在深入了解OpenAI Tokenizer之前,我们先来厘清几个基本概念。
Token的本质:比字符更细,比词更粗的语言单位
Token是大型语言模型处理文本的基本单位,但它既不是字符也不是完整的单词,而是介于两者之间的概念:
- 一个token可能是一个单字符、单词的一部分、完整单词,甚至是常见的短语
- 常见单词通常由1个token表示(如"the"、"cat")
- 不常见词汇可能被分解为多个token(如"tokenization"会被分为"token"、"ization")
- 标点符号、空格等也会被算作单独的token
为什么token如此重要?费用、限制与性能的关键
理解token的重要性,需要从三个核心维度考虑:
- API费用计算基础:几乎所有大型语言模型API(包括OpenAI、Anthropic)都按token数量计费,而非字符数或单词数
- 上下文窗口限制:每个模型都有固定的token上限(如GPT-4有128K,GPT-3.5有16K),超过限制将截断文本
- 生成效率影响:token数量直接影响模型的思考和生成速度,以及最终生成内容的质量

【工作原理】OpenAI Tokenizer如何将文本转换为token?
了解了token的概念后,让我们深入理解OpenAI Tokenizer的工作原理。
Byte Pair Encoding (BPE):OpenAI tokenization的核心算法
OpenAI的tokenizer基于BPE(Byte Pair Encoding)算法,这是一种数据压缩算法,经过专门优化用于自然语言处理:
- 初始化:首先将所有文本拆分为单个字符
- 统计频率:统计字符对出现的频率
- 合并替换:将最常见的字符对合并为一个新的token
- 迭代优化:重复统计和合并过程,直到达到预设的词汇量(vocabulary size)
BPE算法的核心思想是:频繁一起出现的字符应该被编码为一个token,这使得常见单词和短语能够被高效表示。
Tiktoken库:OpenAI官方的Token实现
OpenAI提供了tiktoken库作为官方的tokenization实现,它有几个核心特点:
- 高性能:C++实现的核心,比纯Python实现快10-100倍
- 可逆性:不仅可以将文本转为token,还可以将token序列还原为原始文本
- 模型一致性:确保与OpenAI API使用的tokenizer完全一致
- 支持多种编码方案:针对不同模型版本提供对应的编码器(如cl100k_base用于GPT-4和GPT-3.5-turbo)
💡 专业提示:不同的OpenAI模型可能使用不同的tokenizer,确保使用与目标模型匹配的编码器至关重要!
【实战工具】掌握OpenAI Tokenizer的实用工具与方法
经过理论学习,现在让我们开始实践,掌握实用的tokenization工具。
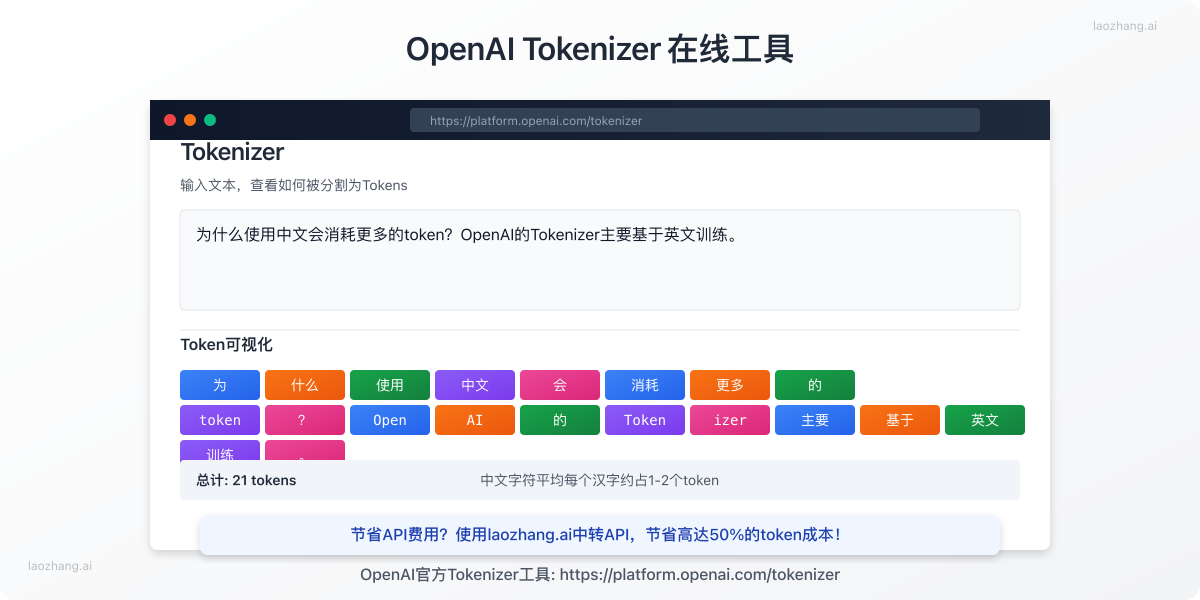
官方在线Tokenizer工具:直观了解token拆分
OpenAI提供了一个在线的Tokenizer工具,可以帮助你直观理解文本是如何被分割成token的:
- 访问https://platform.openai.com/tokenizer
- 在输入框中粘贴任意文本
- 工具会即时显示文本被拆分的token,并用不同颜色标记
- 同时显示总token数量,方便估算API调用成本
这个工具特别适合初学者建立对token的直观认识,也适合快速检查特定文本的token数量。
使用tiktoken库进行编程计算:精确掌控
对于开发者而言,直接在代码中使用tiktoken库是更高效的方式:
python# 安装tiktoken库
# pip install tiktoken
import tiktoken
# 选择与你使用的模型匹配的编码器
# gpt-4, gpt-3.5-turbo, text-embedding-ada-002使用cl100k_base
encoding = tiktoken.get_encoding("cl100k_base")
# 也可以直接指定模型名称
# encoding = tiktoken.encoding_for_model("gpt-4")
# 将文本转换为token
text = "Hello, world! 你好,世界!"
tokens = encoding.encode(text)
# 计算token数量
token_count = len(tokens)
print(f"Token数量: {token_count}") # Token数量: 11
# 解码token(转回文本)
decoded_text = encoding.decode(tokens)
print(f"解码后文本: {decoded_text}") # 解码后文本: Hello, world! 你好,世界!
# 查看每个token的ID
for token in tokens:
print(f"Token ID: {token}, Token文本: {encoding.decode([token])}")
这段代码展示了如何使用tiktoken库进行基本的token操作,包括编码、解码和token计数。
不同语言中的token估算:英文vs中文vs代码
不同类型的内容在tokenization过程中效率各不相同。以下是一些粗略的估算规则:
- 英文文本:一个token约等于4个字符或3/4个单词
- 中文文本:一个汉字通常消耗1-2个token,比英文效率低
- 代码:因包含特殊字符和结构,通常比普通英文消耗更多token
- 数字:纯数字序列较为紧凑,但也会按照特定规则分割
⚠️ 注意:这些只是粗略估算,实际token数量可能有较大偏差,生产环境中应使用tiktoken等工具进行精确计算!
【高级技巧】Token优化策略:如何有效降低API调用成本
了解了token的基本概念和计算方法后,我们来探讨如何通过token优化策略降低API调用成本。
1. 提示词工程(Prompt Engineering)技巧
精心设计的提示可以大幅降低token消耗:
- 使用简洁指令:避免冗余解释和重复内容
- 利用格式标记:使用固定格式如"Q:"和"A:"替代长句描述
- 采用递进式提问:将复杂问题分解为多个独立请求,避免大量上下文携带
- 指定输出格式:明确要求模型输出简洁格式如JSON或表格
2. 减少不必要的上下文信息
精简上下文可以显著节省token:
- 移除冗余历史记录:只保留与当前请求相关的历史对话
- 摘要替代全文:对长文本进行摘要后再输入模型
- 上下文"修剪":定期从对话历史中删除非核心信息
- 使用多次短请求:将大型任务分解为多个小型请求
3. 多模态策略:结合嵌入向量和RAG技术
高级用户可以利用向量数据库和检索增强生成(RAG)技术:
- 使用嵌入向量:将长文档转换为向量存储
- 相关性检索:只检索与当前查询最相关的内容段落
- 动态上下文构建:根据查询动态组装最相关的上下文

4. 代码实现:Token使用优化示例
以下是一个优化token使用的实际代码示例:
pythonimport tiktoken
import re
def optimize_prompt(text, max_tokens=4000):
"""优化提示词,减少token数量同时保留核心内容"""
# 使用GPT-4/3.5的编码器
encoding = tiktoken.encoding_for_model("gpt-4")
# 计算当前token数量
current_tokens = len(encoding.encode(text))
# 如果已经在限制范围内,直接返回
if current_tokens <= max_tokens:
return text, current_tokens
# 1. 移除多余空白
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'\n\s*\n', '\n', text)
# 2. 移除冗余表达
common_redundant = [
r'请注意,', r'值得一提的是,', r'需要强调的是,',
r'换句话说,', r'简单来说,', r'总的来说,'
]
for pattern in common_redundant:
text = re.sub(pattern, '', text)
# 3. 使用缩写
abbreviations = {
'例如': '如',
'也就是说': '即',
'人工智能': 'AI',
}
for full, abbr in abbreviations.items():
text = text.replace(full, abbr)
# 4. 如果还是太长,进行截断,保留前后内容
tokens = encoding.encode(text)
if len(tokens) > max_tokens:
# 保留前2/3和后1/3的内容
front = int(max_tokens * 0.67)
back = max_tokens - front
tokens = tokens[:front] + tokens[-back:]
text = encoding.decode(tokens)
# 返回优化后的文本和token数量
optimized_tokens = len(encoding.encode(text))
return text, optimized_tokens
# 使用示例
long_text = """[这里是一段非常长的文本...]"""
optimized_text, token_count = optimize_prompt(long_text, max_tokens=3000)
print(f"优化前token数: {len(tiktoken.encoding_for_model('gpt-4').encode(long_text))}")
print(f"优化后token数: {token_count}")
print(f"节省比例: {(1 - token_count/len(tiktoken.encoding_for_model('gpt-4').encode(long_text)))*100:.2f}%")
这个函数实现了基本的token优化策略,包括移除冗余、使用缩写和智能截断,可以显著减少token用量。
【实战分析】不同模型的Tokenizer差异与兼容性
了解不同模型的tokenizer差异,对于多模型应用开发至关重要。
OpenAI模型家族的tokenizer差异
OpenAI不同模型使用不同的tokenizer:
| 模型 | Tokenizer编码 | 说明 |
|---|---|---|
| GPT-4/GPT-4o | cl100k_base | 最新编码,支持更多语言和特殊符号 |
| GPT-3.5-Turbo | cl100k_base | 与GPT-4使用相同编码 |
| GPT-3(Davinci等) | p50k_base | 较早的编码,对某些语言支持有限 |
| Codex系列 | p50k_base | 专为代码优化的同时使用p50k编码 |
| Embedding模型 | cl100k_base | 嵌入模型同样使用新编码 |
与其他模型对比:Claude、Gemini和开源模型
不同厂商和开源模型的tokenizer存在较大差异:
- Claude(Anthropic):使用自己的BPE tokenizer,但原理类似,中文编码效率略低于OpenAI
- Gemini(Google):采用SentencePiece tokenizer,对多语言支持较好
- 开源模型:根据模型不同,可能使用BPE、WordPiece、SentencePiece等不同方案
在跨模型应用开发中,需要注意这些差异,并进行相应的适配。
【应用场景】Tokenizer在不同场景中的实际应用
理解了token的原理和优化方法后,我们来看一些具体的应用场景。
1. API成本预估与管理
精确的token计算对成本控制至关重要:
pythonimport tiktoken
import json
def estimate_api_cost(prompt, model="gpt-4", max_tokens=500):
"""估算API调用成本"""
# 模型价格(每1K token,单位:美元)
pricing = {
"gpt-4": {"input": 0.01, "output": 0.03},
"gpt-4o": {"input": 0.005, "output": 0.015},
"gpt-3.5-turbo": {"input": 0.0005, "output": 0.0015}
}
# 获取正确的编码器
encoding = tiktoken.encoding_for_model(model)
# 计算输入token
input_tokens = len(encoding.encode(prompt))
# 估算输出token(假设使用max_tokens)
output_tokens = max_tokens
# 计算成本
input_cost = (input_tokens / 1000) * pricing[model]["input"]
output_cost = (output_tokens / 1000) * pricing[model]["output"]
total_cost = input_cost + output_cost
return {
"model": model,
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"input_cost": round(input_cost, 6),
"output_cost": round(output_cost, 6),
"total_cost": round(total_cost, 6)
}
# 使用示例
prompt = "请分析以下Python代码并优化其性能:\n\ndef fibonacci(n):\n if n <= 1:\n return n\n else:\n return fibonacci(n-1) + fibonacci(n-2)"
cost_estimate = estimate_api_cost(prompt, model="gpt-4", max_tokens=750)
print(json.dumps(cost_estimate, indent=2))
这个函数可以帮助开发者在API调用前估算成本,在高流量应用中特别有价值。
2. 长文档处理与分块策略
处理超出上下文长度的文档时,需要智能分块:
pythonimport tiktoken
from typing import List, Dict
def chunk_document(document: str, chunk_size: int = 1000, overlap: int = 100, model: str = "gpt-4") -> List[Dict]:
"""将长文档分割成重叠的块,以适应模型上下文窗口"""
encoding = tiktoken.encoding_for_model(model)
tokens = encoding.encode(document)
chunks = []
i = 0
while i < len(tokens):
# 确定当前块的结束位置
end = min(i + chunk_size, len(tokens))
# 提取当前块
chunk_tokens = tokens[i:end]
chunk_text = encoding.decode(chunk_tokens)
# 添加到结果列表
chunks.append({
"text": chunk_text,
"token_count": len(chunk_tokens),
"start_idx": i,
"end_idx": end
})
# 移动到下一块的起始位置(考虑重叠)
i = end - overlap if end < len(tokens) else len(tokens)
return chunks
# 使用示例
with open("long_document.txt", "r", encoding="utf-8") as f:
document = f.read()
chunks = chunk_document(document, chunk_size=2000, overlap=200)
print(f"文档被分割为{len(chunks)}个块")
for i, chunk in enumerate(chunks[:2]): # 只打印前两个块作为示例
print(f"块 {i+1}: {chunk['token_count']} tokens")
print(f"前100个字符: {chunk['text'][:100]}...")
这种分块策略可以处理任意长度的文档,同时保持上下文连贯性。
3. 多语言处理优化
不同语言的token效率差异很大,需要针对性优化:
pythonimport tiktoken
import matplotlib.pyplot as plt
import numpy as np
def analyze_language_efficiency():
"""分析不同语言的token效率"""
encoding = tiktoken.encoding_for_model("gpt-4")
samples = {
"英文": "This is a sample of English text for tokenization analysis. It contains regular words and punctuation.",
"中文": "这是用于分词分析的中文示例文本。它包含常见汉字和标点符号。",
"中英混合": "这是一个混合了English和中文的示例,用于testing不同语言混合的token效率。",
"代码": "def calculate_fibonacci(n):\n if n <= 1:\n return n\n return calculate_fibonacci(n-1) + calculate_fibonacci(n-2)",
"数字": "12345678901234567890 987654321098765432109876543210"
}
results = {}
for lang, text in samples.items():
chars = len(text)
tokens = len(encoding.encode(text))
results[lang] = {
"文本": text[:30] + "...",
"字符数": chars,
"Token数": tokens,
"字符/Token比": round(chars/tokens, 2)
}
return results
# 使用示例
efficiency_data = analyze_language_efficiency()
for lang, data in efficiency_data.items():
print(f"{lang}:")
for k, v in data.items():
print(f" {k}: {v}")
print()
这个函数可以帮助开发者了解不同类型内容的token效率,进而做出更明智的内容优化决策。
【最佳实践】企业级Tokenizer应用策略
对于专业开发者和企业用户,以下是一些高级最佳实践。
Token池与预算管理系统
在企业环境中,实施token池和预算管理是控制成本的关键:
- 实施token配额:为不同部门、项目或用户设置token使用限额
- 使用预算告警:当token使用接近预算时触发警报
- 实时监控:建立仪表板追踪token使用情况和成本
- 优化调度:根据业务价值和优先级调整不同任务的token分配
动态模型选择策略
智能选择合适的模型可以优化成本和性能:
- 任务复杂度评估:简单任务使用轻量模型,复杂任务使用高级模型
- 内容长度感知:短内容使用标准模型,长内容考虑使用更大上下文窗口的模型
- 质量-成本平衡:构建决策树,基于任务重要性和预算自动选择模型
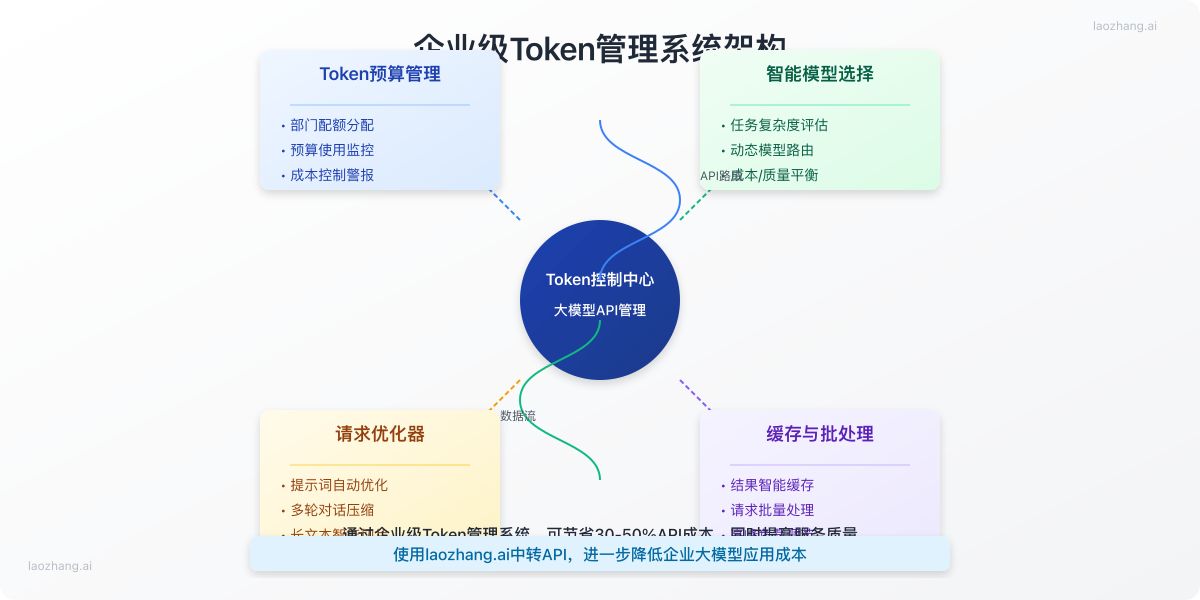
批处理与缓存机制
通过批处理和缓存进一步优化token使用:
- 请求合并:将多个小请求合并为更大的批处理请求
- 结果缓存:对常见查询结果进行缓存,避免重复token消耗
- 增量处理:对大型文档实施增量处理,避免重复分析已处理部分
【使用LaoZhang.AI】通过中转API降低30%以上token成本
了解了token的重要性后,如何实际降低API成本?LaoZhang.AI提供了一个理想解决方案。
为什么选择LaoZhang.AI中转API?
LaoZhang.AI的中转API服务提供多项优势:
- 高达50%的成本节省:相比OpenAI官方API价格更低
- 多模型支持:同时支持GPT-4、GPT-3.5、Claude等多种模型
- 免费额度:注册即送免费token,可测试所有功能
- 稳定性保障:多节点部署,确保API调用稳定可靠
- 完全兼容:与OpenAI官方API完全兼容,无需修改现有代码
如何通过LaoZhang.AI使用Tokenizer服务
LaoZhang.AI不仅提供API服务,还包含token计算工具:
bash# 使用LaoZhang.AI API调用示例
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "计算以下文本的token数量:'这是一个测试文本,用于演示token计算。'"}
]
}'
注册地址:https://api.laozhang.ai/register/
【常见问题】Tokenizer使用FAQ
最后,让我们解答一些关于tokenization的常见问题。
Q1: 不同编程语言如何实现token计算?
A1: 除了Python的tiktoken库外,还有多种语言的实现:
- JavaScript/TypeScript: 可以使用gpt-tokenizer或gpt-3-encoder库
- Java: 可使用OpenAI Java SDK中的token计算功能
- Go: 使用go-tiktoken库
- Ruby: 使用tiktoken_ruby库
- C#/.NET: 使用tiktoken-sharp库
Q2: token计数是否包括空格和标点符号?
A2: 是的,空格、标点符号、换行符等都会被计算为token。一个空格通常是一个独立的token,而标点符号有时会与相邻单词组合成一个token,具体取决于训练数据中的频率。
Q3: 如何处理大型代码库的token优化?
A3: 对于大型代码库,可以:
- 使用抽象摘要替代完整代码
- 仅提交相关函数和上下文,而非整个文件
- 使用注释标记关键部分,过滤非关键代码
- 考虑使用代码专用模型(如Codex系列),它们对代码的处理效率更高
Q4: 图片和其他多模态内容如何计算token?
A4: 多模态模型(如GPT-4V)中,图像也会消耗token:
- 图像通常根据分辨率转换为token,消耗大量token(一张高清图可能消耗数千token)
- 最佳实践是压缩图像,裁剪到仅包含必要内容,降低分辨率以优化token使用
【总结】掌握Token优化,成为AI API使用专家
通过本文的学习,我们已经全面了解了OpenAI Tokenizer的工作原理、实用工具和优化技巧。让我们回顾几个关键要点:
- 理解token本质:token是介于字符和单词之间的语言单位,是大模型API计费和上下文窗口的基本单位
- 掌握计算工具:使用OpenAI的在线工具或tiktoken库准确计算token数量
- 优化策略实施:通过简化提示、压缩上下文和分块处理优化token使用
- 成本管理方案:建立token预算系统,使用LaoZhang.AI等中转服务降低成本
- 不同语言适配:注意中文、代码等不同内容类型的token效率差异
🌟 专业提示:token优化是一门平衡艺术,目标是在保证生成质量的前提下,最小化token消耗。适当的token节省不仅降低成本,还能提升模型响应速度!
希望这篇指南能帮助你更有效地使用大型语言模型API,充分发挥其潜力的同时控制成本。如有任何问题,欢迎在评论区讨论!
【更新日志】持续完善的技术指南
plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-03-15:首次发布完整指南 │ │ 2025-03-20:更新价格和模型信息 │ │ 2025-03-27:增加企业级最佳实践部分 │ └──────────────────────────────────────┘