2025最新Stable Diffusion完全指南:从入门到精通的保姆级教程
【独家】全面解析Stable Diffusion安装、配置与使用技巧,免费生成高质量AI图像!包含WebUI界面详解、提示词编写、高级功能与模型训练,一站式掌握AI绘画神器!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Stable Diffusion完全指南:从入门到精通的保姆级教程【2025最新】
{/* 封面图片 */}

🔥 2025年3月实测有效:本文提供完整解决方案,从零开始掌握Stable Diffusion的全部功能,无需专业知识,小白也能快速上手!
在这篇完整指南中,你将学到:
- 如何在本地免费部署Stable Diffusion(无需付费API)
- 掌握WebUI界面所有功能的详细使用方法
- 创建高质量图像的提示词编写技巧与实例
- ControlNet精确控制图像生成的全套教程
- LoRA训练与使用方法:让AI学会你喜欢的风格
- 如何选择和管理不同模型以优化生成效果
一、Stable Diffusion基础概念:新手必读
作为目前最流行的开源AI绘画工具之一,Stable Diffusion彻底改变了数字艺术创作的方式。与DALL-E、Midjourney等闭源服务不同,它完全免费、开源,并且可以在普通电脑上本地运行,无需支付API费用或受限于服务商的使用限制。
1.1 Stable Diffusion是什么?
Stable Diffusion是一种基于潜在扩散模型(Latent Diffusion Model)的AI图像生成技术,由Stability AI开发并开源。它能通过文本描述(提示词)生成高质量的图像,也支持图像到图像的转换、图像修复和风格迁移等功能。
核心优势:与其他AI图像生成工具相比,Stable Diffusion有以下显著特点:
- 完全免费开源:无需支付使用费,可本地部署运行
- 高度可定制:支持模型微调、LoRA训练和插件扩展
- 丰富的社区资源:大量免费模型、插件和教程可供使用
- 隐私保护:本地运行意味着你的数据和创作不会上传到云端
- 性能灵活:可根据电脑配置调整生成质量和速度
1.2 工作原理:了解背后的技术
要充分发挥Stable Diffusion的潜力,了解其基本工作原理很有帮助:
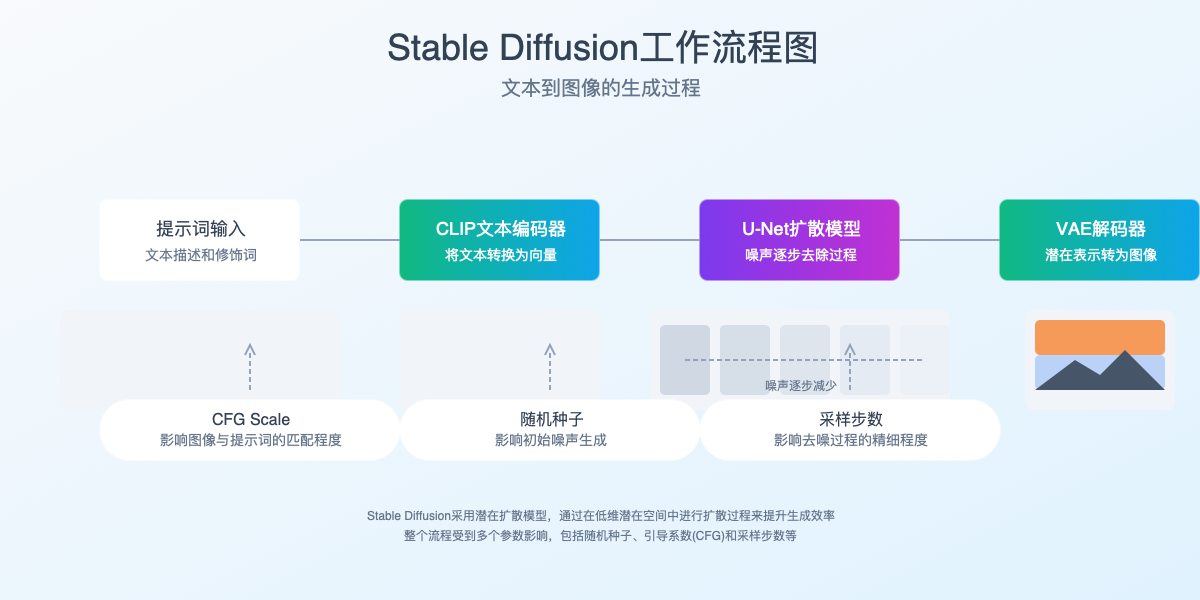
Stable Diffusion的图像生成过程主要包含以下核心步骤:
- 文本编码:CLIP文本编码器将输入的文本提示词转换为向量表示
- 扩散过程:从随机噪声开始,U-Net模型根据文本向量逐步去除噪声
- 图像解码:VAE解码器将去噪后的潜在表示转换为最终的可见图像
这个过程受到多个参数的影响,包括随机种子、采样步数、CFG Scale(提示词遵循度)等,我们将在后续章节详细解释这些参数的调整方法。
二、系统需求与安装部署:一次性搞定环境配置
在开始使用Stable Diffusion之前,你需要先了解系统需求并完成安装部署。以下是2025年最新的详细步骤,确保你能顺利运行这个强大的AI绘画工具。
2.1 硬件需求:检查你的电脑是否满足条件
Stable Diffusion是一种资源密集型应用,特别是对GPU有一定要求。以下是推荐的硬件配置:
| 配置级别 | GPU | 显存(VRAM) | 内存(RAM) | 适用场景 |
|---|---|---|---|---|
| 入门级 | NVIDIA GTX 1660 或更高 | 6GB+ | 16GB+ | 基础图像生成,512×512分辨率 |
| 推荐配置 | NVIDIA RTX 3060 或更高 | 8GB+ | 32GB+ | 高质量图像生成,支持ControlNet |
| 高端配置 | NVIDIA RTX 4070/4080/4090 | 12GB+ | 64GB+ | 高分辨率,多批次,LoRA训练 |
📌 注意:虽然AMD显卡也能运行Stable Diffusion,但由于CUDA优化的原因,NVIDIA显卡的性能通常更好。如果你使用的是AMD显卡,可能需要额外的配置步骤。
💡 低配置解决方案:
如果你的电脑不满足上述要求,仍有以下选择:
- 启用xFormers内存优化技术(可节省30-40%显存)
- 使用4bit量化模型减少显存需求
- 降低生成图像的分辨率和批次大小
- 使用CPU模式(极慢,仅用于测试)
2.2 安装Stable Diffusion WebUI:最简单的部署方法
目前最流行且用户友好的Stable Diffusion部署方式是使用Automatic1111的WebUI。以下是2025年最新的安装步骤:
Windows系统安装步骤:
-
准备基础环境:
- 安装Python 3.10(注意不要使用更高版本)
- 安装Git
- 安装最新版NVIDIA驱动(如果使用NVIDIA显卡)
-
克隆WebUI仓库:
- 创建一个文件夹用于存放Stable Diffusion(例如
D:\stable-diffusion) - 右键点击该文件夹,选择"Git Bash Here"
- 运行以下命令:
bashgit clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - 创建一个文件夹用于存放Stable Diffusion(例如
-
启动WebUI:
- 进入克隆的仓库文件夹
- 运行
webui-user.bat文件 - 首次运行会自动下载所需依赖和基础模型,可能需要一段时间
macOS系统安装步骤:
-
准备基础环境:
- 安装Homebrew(如果尚未安装)
- 通过终端安装必要组件:
bashbrew install [email protected] git wget cmake -
克隆WebUI仓库:
- 打开终端,选择一个目录用于安装
bashmkdir -p ~/stable-diffusion cd ~/stable-diffusion git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git -
启动WebUI:
- 运行启动脚本:
bashcd stable-diffusion-webui ./webui.sh
Linux系统安装步骤:
-
准备基础环境:
bashsudo apt update sudo apt install python3.10 python3.10-venv python3-pip git wget -
安装NVIDIA驱动和CUDA(如果使用NVIDIA显卡):
bashsudo apt install nvidia-driver-535 nvidia-cuda-toolkit -
克隆和启动WebUI:
bashgit clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webui ./webui.sh
2.3 首次启动配置:优化性能设置
成功安装后,WebUI会在本地启动一个web服务器,通常可以通过浏览器访问http://127.0.0.1:7860来打开界面。首次使用时,建议进行以下优化配置:
- 进入设置界面:点击顶部的"设置"选项卡
- 优化性能:
- 在"User Interface"部分,可以设置界面语言为"Chinese"(如需中文界面)
- 在"Stable Diffusion"部分,勾选"Move VAE and CLIP to CPU"可以节省显存
- 在"Optimizations"部分,根据你的GPU选择合适的优化选项
- 保存设置:点击底部的"保存"按钮,然后重启WebUI
2.4 模型下载与管理:安装你的第一个模型
WebUI安装完成后,你还需要下载模型才能开始生成图像。以下是获取和安装模型的步骤:
-
了解模型类型:
- 基础模型(
.ckpt或.safetensors格式):控制整体生成风格和质量 - LoRA模型(
.safetensors格式):微调特定风格或主题的插件模型 - VAE模型:改善颜色和细节表现的视觉编码器
- 基础模型(
-
从可靠来源下载模型:
- Civitai:最大的社区模型分享平台
- Hugging Face:官方认证的开源模型库
-
安装模型:
- 基础模型:放入
stable-diffusion-webui/models/Stable-diffusion文件夹 - LoRA模型:放入
stable-diffusion-webui/models/Lora文件夹 - VAE模型:放入
stable-diffusion-webui/models/VAE文件夹
- 基础模型:放入
-
在WebUI中加载模型:
- 重启WebUI或点击刷新按钮
- 在文生图或图生图界面的顶部选择刚才安装的模型
⚠️ 重要安全提示:
下载模型时请注意以下几点:
- 只从可信来源下载模型,避免恶意代码和安全风险
- 优先选择.safetensors格式的模型,它比.ckpt格式更安全
- 留意模型许可条款,确保你的使用方式符合许可要求
- 使用防病毒软件扫描下载的文件,特别是来自不熟悉的源的文件
现在你已经完成了Stable Diffusion的安装和基本配置,接下来我们将深入了解如何使用它的核心功能生成令人惊艳的图像!
三、WebUI界面与基本使用:30分钟掌握核心功能
Stable Diffusion WebUI的界面功能丰富但可能对新手略显复杂。本章将详细介绍关键功能区和基本操作流程,帮助你快速上手。
3.1 界面概览:认识WebUI的各个部分
WebUI界面主要分为以下几个部分:
- 顶部导航栏:包含文生图、图生图、其他功能等主要功能切换
- 左侧参数面板:设置提示词、负面提示词和各种生成参数
- 中间预览区:显示生成的图像和批次结果
- 右侧工具栏:提供图像保存、删除、复制等功能
- 底部状态栏:显示生成进度和系统状态信息
3.2 文本生成图像:最基础也是最常用的功能
文生图(Text-to-Image)是Stable Diffusion最核心的功能,可以根据文字描述生成图像。以下是使用步骤:
-
选择模型:在顶部下拉菜单中选择你想使用的基础模型
-
编写提示词(Prompt):
- 在顶部文本框中输入你想要生成的图像描述
- 可以使用权重语法(如
(word:1.2))增强特定元素的影响 - 可以添加模型支持的触发词(如
masterpiece, best quality等)提高质量
-
编写负面提示词(Negative Prompt):
- 在第二个文本框中输入你不希望在图像中出现的元素
- 常用负面提示词包括
blurry, bad anatomy, ugly, low quality等
-
设置基本参数:
- 采样方法:一般推荐DPM++ 2M Karras或Euler a
- 采样步数:20-30步通常足够,更高步数提升有限
- CFG Scale:7-9是良好的平衡点,值越高越遵循提示词
- 尺寸:常用512×512或768×768,取决于模型支持和显存
-
点击"生成"按钮开始图像生成过程
🔍 提示词编写示例:
以下是一个生成高质量风景图的完整提示词示例:
masterpiece, best quality, highly detailed, 8k, cinematic lighting, beautiful mountain landscape, sunset, golden hour, clouds, lake reflection, snow-capped peaks, dramatic sky, nature photography
配套的负面提示词:
blurry, bad composition, ugly, low quality, deformed, watermark, signature, text, buildings, people, animals, cartoon, anime
3.3 图像生成进阶:批量生成与网格
掌握基本生成后,你可以使用以下功能提高生产效率:
-
批量生成:
- 设置"批次数量"和"每批数量"生成多张图片
- 例如:批次数量=2,每批数量=4,将生成8张图片
- 注意:增加批量会消耗更多显存
-
使用种子控制:
- 种子值决定了初始噪声,相同种子配合相同设置会生成相似图像
- 设置固定种子有助于微调和复现好的结果
- 设置-1启用随机种子以探索更多可能性
-
使用X/Y图表批量比较:
- 点击脚本下拉菜单,选择"X/Y图表"
- 可以系统地比较不同参数的效果,如采样器、CFG、步数等
- 这是找到最佳参数组合的利器
采样步数对比(10步 vs 30步)
示例图
10步
示例图
30步
CFG Scale对比(7 vs 12)
示例图
CFG=7
示例图
CFG=12
3.4 图像到图像转换:改进和修改已有图像
图生图(Image-to-Image)功能允许你上传一张现有图像,然后让AI基于这张图和提示词生成新的变体。
使用步骤:
-
切换到"图生图"选项卡
-
上传初始图像:
- 点击左侧的图像上传区域或拖放图片到此处
- 根据需要调整"重绘幅度"(Denoising strength):
- 值越低(0.3-0.5):保留更多原图细节
- 值越高(0.7-0.9):生成更创新的结果
-
添加提示词:
- 像文生图一样添加正向和负向提示词
- 提示词应描述你希望如何修改或增强原始图像
-
点击"生成"按钮开始转换过程
🎨 图生图的创意应用:
- 风格转换:将照片转换为油画、动漫、像素艺术等风格
- 内容增强:改善图像质量、添加细节或更改照明
- 概念迭代:逐步改进设计草图或概念艺术
- 变体探索:生成同一场景或角色的多种变体
3.5 局部重绘:精确修改图像的特定区域
局部重绘(Inpainting)是图生图的一种特殊形式,允许你只修改图像的特定区域。
使用步骤:
-
切换到"图生图"标签,然后在脚本下拉菜单中选择"局部重绘"
-
上传图像并创建蒙版:
- 上传需要修改的图像
- 使用画笔工具在想要重绘的区域绘制蒙版(白色区域会被重绘)
-
添加描述新内容的提示词:
- 提示词应该专注于描述你希望在蒙版区域生成的内容
-
调整重绘参数:
- "重绘幅度"控制AI的创造自由度
- "蒙版模糊"控制蒙版边缘的过渡平滑度
-
点击"生成"按钮进行局部重绘
🧩 局部重绘使用小贴士:
- 创建略大于目标区域的蒙版,帮助AI更好地融合新内容
- 如果第一次结果不理想,可以微调蒙版形状和提示词后重试
- 对于复杂的替换(如更换背景),可能需要多次局部重绘
- 配合ControlNet使用可以获得更精确的控制效果
3.6 图像放大与增强:提升分辨率和细节
生成的图像可以使用内置的放大器进行高质量放大,提高分辨率和细节:
-
在图像生成后,点击图像下方的"放大"按钮
-
选择放大设置:
- 放大器:选择放大算法(推荐R-ESRGAN 4x+或SwinIR 4x)
- 放大倍数:通常2x或4x
- 面部恢复:选择GFPGAN或CodeFormer来改善人物面部
-
点击"生成"按钮开始放大过程
放大功能不仅可以增加图像尺寸,还能修复细节并改善整体质量。
3.7 提示词技巧:编写更有效的描述
掌握提示词编写技巧是生成高质量图像的关键。以下是一些进阶技巧:
-
使用权重语法增强关键元素:
- 基本语法:
(关键词:1.2)增强元素,[关键词:0.8]减弱元素 - 例如:
(golden retriever:1.3), walking in (autumn forest:1.2), (sunset:1.1)
- 基本语法:
-
结构化你的提示词:
- 主体→风格→环境→细节→光照→效果
- 例如:
beautiful woman, intricate dress, fantasy castle, detailed vegetation, golden hour lighting, cinematic, 8k
-
使用艺术修饰词增强质量:
- 添加艺术风格:
oil painting, digital art, concept art, watercolor - 添加质量词:
masterpiece, best quality, highly detailed - 添加技术词:
8k resolution, photorealistic, studio lighting
- 添加艺术风格:
-
使用否定提示词排除不需要的元素:
- 常用的否定提示词集合:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, watermark, signature, username, blurry, artist name
| 提示词类别 | 示例 | 效果 |
|---|---|---|
| 主题描述 | beautiful woman, long blonde hair, blue eyes | 定义图像的核心主体 |
| 场景环境 | forest, sunset, mountain backdrop, river | 设定图像的背景和场景 |
| 风格触发词 | trending on artstation, digital illustration, concept art | 设定整体艺术风格 |
| 质量修饰词 | masterpiece, best quality, highly detailed, 8k, HDR | 提高整体图像质量 |
| 光照和氛围 | cinematic lighting, golden hour, volumetric lighting | 强化图像的照明和氛围 |
现在你已经掌握了Stable Diffusion的基本功能和使用技巧,接下来我们将探索更高级的功能,如ControlNet和LoRA训练,进一步提升你的AI绘画能力!
四、ControlNet高级功能:精确控制图像生成
ControlNet是Stable Diffusion生态系统中最强大的扩展之一,它允许你通过各种条件输入(如线稿、姿势骨架、深度图等)精确控制图像生成过程。本章将详细介绍如何安装和使用ControlNet来提高你的AI绘画精准度。

4.1 ControlNet简介:为什么它如此重要?
传统的Stable Diffusion生成过程主要依赖文本提示词,难以精确控制图像的布局、姿势和结构。ControlNet通过添加额外的条件控制层,使AI能够遵循特定的视觉引导,同时保持高质量的生成效果。
ControlNet的核心优势:
- 精确布局控制:能够让AI严格遵循你设计的构图和结构
- 多样化条件输入:支持线稿、姿势、深度图、分割图等多种控制模式
- 保持创意自由:在指定结构的同时,允许AI在细节和风格上发挥创意
- 提高生成效率:减少随机尝试次数,更快地获得满意结果
4.2 安装ControlNet:两种方法详解
方法一:通过WebUI内置扩展安装(推荐)
- 在WebUI中打开"扩展"选项卡
- 选择"从URL安装"子选项卡
- 输入ControlNet仓库URL:
https://github.com/Mikubill/sd-webui-controlnet - 点击"安装"按钮
- 重启WebUI以完成安装
方法二:手动安装(适用于特殊情况)
-
进入WebUI的扩展目录:
bashcd stable-diffusion-webui/extensions -
克隆ControlNet仓库:
bashgit clone https://github.com/Mikubill/sd-webui-controlnet.git -
下载ControlNet模型:
- 访问Hugging Face的ControlNet模型页面
- 下载需要的预训练模型(
.pth或.safetensors格式) - 将下载的模型放入
stable-diffusion-webui/extensions/sd-webui-controlnet/models目录
-
重启WebUI激活扩展
4.3 ControlNet模型类型:选择适合你需求的模型
ControlNet提供多种预训练模型,每种针对不同类型的控制输入优化:
| 模型类型 | 用途 | 适用场景 |
|---|---|---|
| Canny | 基于边缘检测的控制 | 保留照片的基本轮廓和结构 |
| Depth | 基于深度图的控制 | 保持场景的空间感和立体感 |
| Normal | 基于法线图的控制 | 细致保留3D模型和物体形状 |
| OpenPose | 基于人体姿势的控制 | 精确控制人物的姿势和动作 |
| Lineart | 基于线稿的控制 | 为手绘草图或线稿上色 |
| Scribble | 基于简笔画的控制 | 从简单草图生成完整图像 |
| Seg | 基于分割图的控制 | 控制不同区域的内容分布 |
| SoftEdge | 基于柔和边缘的控制 | 更自然的边缘控制,适合艺术风格 |
💡 建议:初次使用时,可以优先下载Canny、Depth和OpenPose这三个模型,它们最为通用且效果显著。
4.4 使用ControlNet:实用技巧与案例
按照以下步骤使用ControlNet控制图像生成:
-
准备控制图像:
- 可以上传已有图像(如线稿、照片等)
- 也可以使用内置的预处理器生成控制图(如Canny边缘检测)
-
配置ControlNet面板:
- 在WebUI中,文生图或图生图界面下方会出现ControlNet面板
- 勾选"启用"选项激活ControlNet
- 根据需要调整以下参数:
- 预处理器:选择如何处理输入图像(如Canny、HED等)
- 模型:选择对应的ControlNet模型
- 控制权重:控制结构一致性的强度(0.5-1.0是良好起点)
- 指导开始/结束:控制ControlNet在生成过程中的影响范围
-
结合适当的提示词:
- 提示词应与控制图像的内容相协调
- 专注于描述你想要的风格、细节和氛围
案例一:使用线稿控制生成精确的角色插画
输入:线稿
线稿示例
提示词
masterpiece, best quality, 1girl, beautiful detailed eyes, anime style, colorful outfit, school uniform, detailed background, classroom
输出:完成插画
生成结果
案例二:使用人体姿势控制生成特定动作的角色
输入:骨架姿势
OpenPose示例
提示词
masterpiece, best quality, young man, athletic build, action pose, dynamic lighting, urban environment, detailed clothing, photorealistic
输出:动作人物
生成结果
4.5 多ControlNet协同工作:组合多种控制实现复杂效果
ControlNet的一个强大特性是支持多个控制条件同时工作。通过组合不同类型的控制,可以实现更精确和复杂的图像生成:
-
在WebUI中:
- 打开"ControlNet单元0"、"ControlNet单元1"等多个控制单元
- 为每个单元配置不同类型的控制输入和模型
-
常见的有效组合:
- Canny + OpenPose:同时控制整体轮廓和人物姿势
- Depth + Seg:控制空间深度和内容分区
- Lineart + Normal:结合线稿的细节和法线图的立体感
🔧 多ControlNet使用技巧:
- 为不同控制单元设置不同的权重,优先级较高的控制应设置更高权重
- 调整每个控制单元的起始/结束比例,避免它们在整个生成过程中相互干扰
- 对于复杂场景,建议先使用单一控制测试效果,然后逐步添加其他控制
- 结合参考控制(Reference Control)可以实现风格和内容的双重控制
4.6 ControlNet创意应用:超越基础用法
除了基本控制外,ControlNet还有许多创新应用:
照片改编与风格迁移
- 使用Canny边缘检测提取照片结构
- 用艺术风格的提示词生成新图像
- 保持原始照片的构图和结构,但完全改变风格
从草图到成品的工作流
- 绘制简单的线稿或草图
- 使用Lineart或Scribble ControlNet模型
- 通过提示词指定详细的风格和元素
- 一键将草图转变为精美插画
3D模型渲染增强
- 从3D软件导出深度图和法线图
- 使用Depth和Normal ControlNet模型
- 生成比传统3D渲染更具艺术感的图像
⚠️ ControlNet常见问题解决:
- 问题:生成图像完全忽略控制图 → 解决方案:增加控制权重或确保使用了正确的模型
- 问题:图像过于遵循控制图,缺乏创意 → 解决方案:降低控制权重或调整指导开始/结束值
- 问题:显存不足错误 → 解决方案:使用低显存优化选项或减少并发ControlNet数量
- 问题:预处理器效果不理想 → 解决方案:尝试手动处理输入图像或调整预处理器参数
ControlNet是将Stable Diffusion从"随机创意工具"转变为"精准设计工具"的关键扩展。掌握ControlNet将为你的AI艺术创作打开全新的可能性,让你能够将脑海中的精确想法转化为图像,而不仅仅依赖于运气和无数次尝试。
五、模型类型与选择指南:找到最适合你需求的模型
Stable Diffusion的生态系统中存在众多不同类型的模型,每种都有其独特的优势和适用场景。本章将深入分析不同模型类型的特点,并提供选择建议,帮助你找到最符合创作需求的模型。
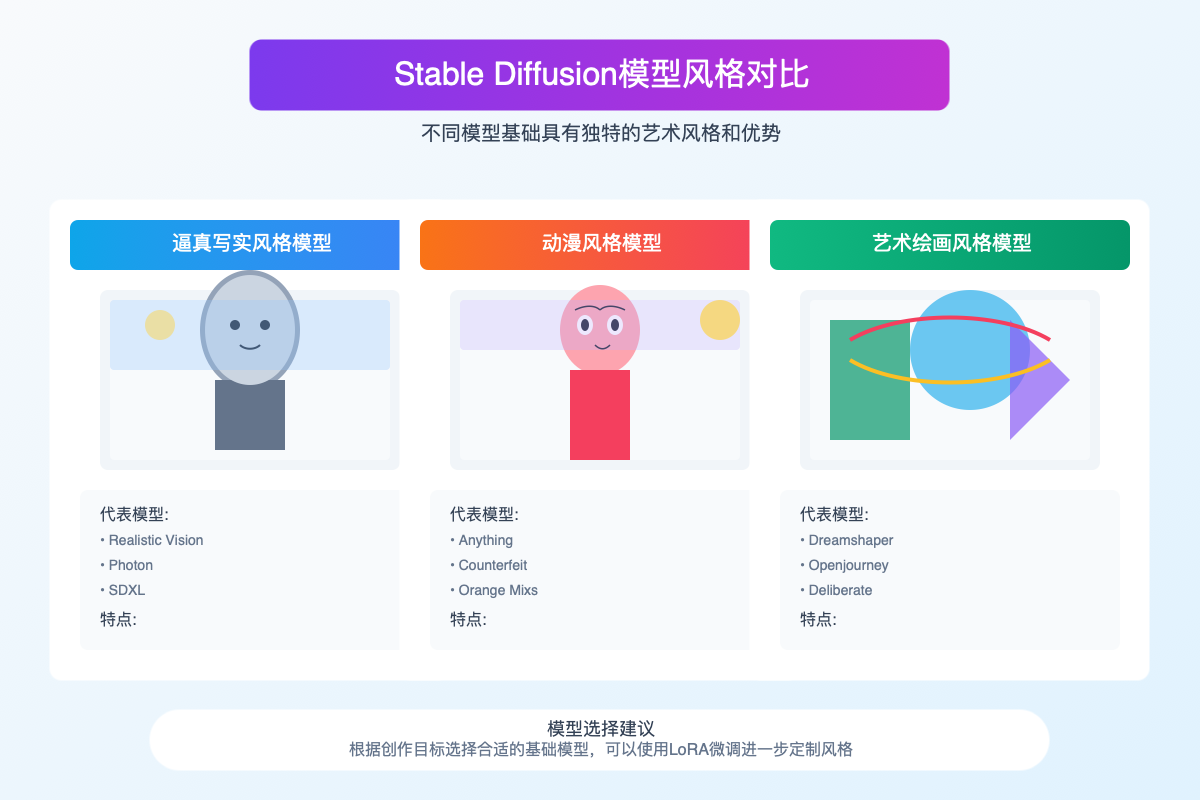
5.1 基础模型类型:了解主要模型分类
Stable Diffusion模型可以按照风格和用途大致分为以下几类:
| 模型类别 | 代表模型 | 特点和优势 | 适用场景 |
|---|---|---|---|
| 写实照片风格 | Realistic Vision, SDXL, Photon | 高度逼真的细节,优秀的光影效果,真实材质表现 | 产品设计,人像摄影,风景写实 |
| 动漫风格 | Anything, Counterfeit, Orange Mixs | 鲜明的二次元风格,角色表现力强,线条清晰 | 动漫插画,角色设计,漫画创作 |
| 艺术绘画风格 | Dreamshaper, Openjourney, Deliberate | 强烈的艺术表现力,丰富的风格多样性,创意性强 | 概念艺术,插画设计,创意表达 |
| 特化模型 | Stable Diffusion XL (SDXL), Stable Video | 针对特定任务优化,高分辨率支持,视频生成 | 专业制作,大尺寸输出,视频创作 |
5.2 模型版本演进:从SD 1.5到SDXL
Stable Diffusion模型经历了几次重要更新,每个版本都带来了显著改进:
-
SD 1.4/1.5:
- 第一代广泛使用的模型,训练数据量约50亿图像
- 512×512分辨率优化,基本的文本理解能力
- 至今仍有许多优秀的微调模型基于1.5版本
-
SD 2.0/2.1:
- 改进的文本理解能力,使用OpenCLIP作为文本编码器
- 更好的审美质量,但有时缺乏1.5版本的多样性
- 768×768分辨率优化
-
SD XL 1.0:
- 大幅提升的图像质量和文本理解能力
- 1024×1024分辨率优化,更好的构图能力
- 组合使用两个不同的文本编码器,理解更复杂的提示词
- 改进的面部和手部渲染
-
最新专业模型:
- Stability AI的SDXL Turbo:实时生成能力(1-2步出图)
- Runway的Gen2:生成连贯视频的能力
- Midjourney V6:虽不开源但基于SD技术,极高的视觉质量
🎯 模型版本选择建议:
- 如果你的GPU显存有限(<8GB),优先考虑SD 1.5基础的模型
- 如果你主要创作动漫风格内容,1.5版本的特化模型往往表现更好
- 如果你需要更高的写实度和分辨率,SDXL是更好的选择
- 对于专业制作,可以尝试SDXL基础上的垂直领域微调模型
5.3 常见优质模型推荐:2025年精选
以下是经过实测的高质量模型推荐,按照不同风格和用途分类:
写实风格模型
-
Realistic Vision v6.0
- 特点:极致的写实效果,出色的人物面部细节
- 优势:良好的提示词响应度,优秀的光影效果
- 下载:Civitai - Realistic Vision
-
SDXL Reimagined
- 特点:基于SDXL的写实增强,高分辨率支持
- 优势:优秀的构图能力,减少畸变现象
- 下载:Hugging Face - SDXL Reimagined
动漫风格模型
-
Anything V5
- 特点:清新的动漫风格,角色表现力丰富
- 优势:色彩鲜明,线条清晰,适合各类动漫创作
- 下载:Civitai - Anything V5
-
CounterfeitV3.0
- 特点:高质量二次元风格,精细的细节表现
- 优势:优秀的手部和面部绘制,服装细节丰富
- 下载:Civitai - CounterfeitV3.0
艺术绘画模型
-
Dreamshaper 8
- 特点:多功能的艺术风格,适应性强
- 优势:风格多样性,创意表现力,简单提示词也能出好图
- 下载:Civitai - Dreamshaper 8
-
Deliberate v3.0
- 特点:平衡的艺术表现力,既有创意又有精度
- 优势:提示词遵循度高,适合精细控制的场景
- 下载:Civitai - Deliberate v3.0
💾 模型文件格式说明:
- .safetensors:更安全的模型格式,无法执行恶意代码,推荐优先使用
- .ckpt:传统检查点格式,理论上可以包含可执行代码,有安全风险
- .pt/.pth:PyTorch模型格式,通常用于ControlNet等辅助模型
安全建议:尽可能从知名源下载.safetensors格式的模型,避免潜在安全风险。
5.4 模型混合技术:创建个性化模型
模型混合(Model Merging)是一种强大的技术,允许你组合不同模型的特性,创建个性化的混合模型:
-
在WebUI中使用模型混合:
- 进入"检查点合并"选项卡
- 选择2-3个要混合的基础模型
- 设置各自的权重(权重总和应为1)
- 点击"合并"生成新模型
-
常见的混合模式:
- 加权平均:最基本的混合方式,按比例混合模型权重
- Block权重:对不同模块使用不同的混合权重
- 收藏夹模型添加:允许在生成时动态调整模型组合
-
有效的混合策略:
- 混合写实模型与艺术风格模型创建"半写实"效果
- 混合不同动漫风格模型创建独特的二次元风格
- 使用专业领域模型微调通用模型的特定能力
✨ 模型混合推荐组合:
- 全能型混合:Realistic Vision (40%) + Dreamshaper (40%) + Anything (20%)
- enhanced写实:Realistic Vision (70%) + SDXL (30%)
- 柔和动漫风:Anything (60%) + Counterfeit (40%)
5.5 VAE与Embedding模型:增强细节与概念
除了主模型外,还有一些辅助模型可以提升生成质量:
VAE(变分自编码器)
VAE负责将潜在空间的表示转换为最终的RGB图像,好的VAE可以显著提升颜色和细节:
-
常用VAE推荐:
- vae-ft-mse-840000-ema:通用VAE,适用于大多数SD 1.x模型
- sdxl_vae.safetensors:专为SDXL优化的VAE
- Orangemix.vae.pt:适合动漫风格模型的VAE
-
使用方法:
- 将VAE文件放入models/VAE文件夹
- 在设置中的VAE下拉菜单选择对应VAE
- 或在生成界面的"覆盖设置"中指定VAE
Textual Inversion/Embeddings
这些是小型的"概念编码",教会模型理解特定的风格、角色或物体:
-
使用方式:
- 将.pt或.bin文件放入embeddings文件夹
- 在提示词中使用特殊标记引用它们,如
<style-name>
-
常用Embeddings:
- 风格相关:如
<anime-style>,<realistic-photo> - 质量相关:如
<detail-enhancer>,<better-quality> - 概念相关:如特定角色、场景或物体
- 风格相关:如
5.6 模型管理最佳实践:保持你的模型库有序
随着使用的深入,你可能会收集大量模型。以下是有效管理模型的建议:
-
建立分类系统:
- 按风格分类:写实、动漫、绘画、特效等
- 按用途分类:人像、风景、角色、概念艺术等
- 使用前缀命名:如"Real_", "Anime_", "Art_"等
-
模型元数据管理:
- 使用WebUI的"模型信息"标签查看和编辑模型信息
- 添加示例图、适用提示词等信息便于参考
- 记录模型混合的配方和设置
-
性能优化策略:
- 使用模型剪枝(Model Pruning)减小文件大小
- 考虑4bit/8bit量化模型降低显存需求
- 删除很少使用的模型,保持库的精简和高效
-
备份重要模型:
- 定期备份你最常用和自创的模型
- 记录模型下载源,以便未来重新获取
- 使用模型版本控制,保留不同版本的迭代记录
⚠️ 模型使用注意事项:
- 注意遵循模型许可条款,特别是商业使用限制
- 一些模型可能含有成人内容倾向,使用时注意适当场合
- 大型模型需要足够的显存,使用前检查你的硬件是否支持
- 定期查看模型更新,许多流行模型会发布优化版本
通过本章的指南,你应该能够更好地理解不同类型的Stable Diffusion模型,并根据自己的创作需求选择最合适的模型。下一章我们将深入探讨LoRA训练,让你能够创建专属于自己的AI绘画风格!
六、LoRA训练与自定义模型:创建专属AI艺术风格
LoRA (Low-Rank Adaptation) 是一种轻量级的模型微调技术,让你能够使用少量图像训练出专属的风格、角色或概念。这比完整的模型训练需要更少的资源和时间,是个性化Stable Diffusion的最佳方式。
6.1 什么是LoRA及其优势
LoRA技术的核心优势:
- 资源需求低:只需中等配置GPU,甚至可以在8GB显存的设备上训练
- 样本需求少:通常只需5-20张图像即可获得良好效果
- 训练时间短:几小时内即可完成训练
- 体积小巧:通常只有几MB到几十MB,易于分享和存储
- 可组合性强:可以同时使用多个LoRA,组合不同的风格和特性
LoRA本质上是在基础模型上添加的"风格补丁",它只修改原模型的少数关键参数,而不是创建完整的新模型。
6.2 准备LoRA训练环境
要训练LoRA,你需要安装额外的工具。最推荐的方式是使用kohya_ss,这是一个用户友好的LoRA训练界面:
安装kohya_ss(Windows)
-
下载并安装必要组件:
- Python 3.10
- Git
- Visual Studio 2022 生成工具(C++桌面开发)
-
克隆并安装kohya_ss:
bashgit clone https://github.com/bmaltais/kohya_ss.git cd kohya_ss .\setup.bat -
启动WebUI界面:
bash.\gui.bat
使用Google Colab训练(免费选项)
如果你没有合适的GPU,可以使用Google Colab:
- 搜索"kohya_ss colab"找到最新的Colab笔记本
- 使用Google账号登录并复制笔记本
- 按照笔记本中的指示操作
6.3 准备训练数据集
训练成功的关键在于高质量、一致性强的数据集:
-
收集图像:
- 风格LoRA: 收集10-30张具有一致艺术风格的图像
- 角色LoRA: 收集10-20张同一角色的不同姿势图像
- 概念LoRA: 收集5-15张表现同一概念的图像
-
准备图像:
- 裁剪至合适尺寸(推荐512×512或768×768)
- 确保图像质量高,没有水印和文字
- 保持风格一致性,避免混合不同风格
- 将图像转换为PNG格式,确保清晰度
-
创建标注:
- 为每张图像创建对应的文本描述文件(.txt)
- 详细描述图像内容,包括重要特征和风格
- 可以使用自动标注工具如BLIP或TagAnything辅助生成标注
💡 标注示例:
masterpiece, best quality, digital painting, red haired female, green eyes, fantasy style, detailed face, wearing ornate armor, forest background, evening light
好的标注应包含:
- 主体描述(人物、物体等)
- 显著特征(发色、眼睛颜色、服装等)
- 风格说明(油画、插画、照片等)
- 环境和背景信息
6.4 LoRA训练流程步骤
使用kohya_ss进行LoRA训练的基本步骤:
-
设置项目和数据集:
- 在kohya_ss中打开"训练"选项卡
- 设置数据集目录和输出目录
- 使用"Dreambooth LoRA"选项卡进行配置
-
配置训练参数:
- 基础模型:选择你想基于哪个模型训练
- 分辨率:根据你的图像设置(通常512×512或768×768)
- 批次大小:根据显存设置(2-8之间)
- 学习率:通常设置为1e-4至5e-4之间
- 训练步数:根据图像数量设置(通常每张图像300-500步)
- LoRA等级:通常设置为4-16
-
启动训练:
- 点击"开始训练"按钮
- 监控训练进度和预览图像
- 完成后,LoRA文件会保存在输出目录
🎛️ 关键参数推荐设置:
风格LoRA:
- LoRA等级:8-12
- 学习率:3e-4
- 步数:每张图像约400步
角色LoRA:
- LoRA等级:16-32
- 学习率:1e-4
- 步数:每张图像约500步
6.5 使用和分享LoRA模型
训练完成后,你可以通过以下方式使用LoRA:
-
在WebUI中使用:
- 将LoRA文件放入
stable-diffusion-webui/models/Lora文件夹 - 在提示词中使用特殊语法激活LoRA:
<lora:your_lora_name:0.7> - 0.7是强度值,可以调整为0.1-1.0之间以控制效果强度
- 将LoRA文件放入
-
组合多个LoRA:
- 在提示词中添加多个LoRA标记:
<lora:style_lora:0.6> <lora:character_lora:0.8> - 组合风格LoRA与角色LoRA实现独特效果
- 避免使用太多LoRA,通常2-3个为宜
- 在提示词中添加多个LoRA标记:
-
分享你的LoRA:
- 可以上传到Civitai、Hugging Face等平台
- 分享时提供示例图像和推荐提示词
- 注明适用的基础模型和推荐设置
6.6 常见LoRA问题解决
训练和使用LoRA时可能遇到的问题及解决方案:
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 训练后效果不明显 | 学习率过低或步数不足 | 增加学习率或训练步数,确保数据集有明确特征 |
| 训练过度(过拟合) | 步数过多或学习率过高 | 减少训练步数,降低学习率,增加数据集多样性 |
| 显存不足错误 | 批次大小或分辨率过高 | 降低批次大小,减小图像分辨率,启用优化选项 |
| 使用时无法激活效果 | 激活语法错误或强度不足 | 检查LoRA名称,增加强度值,确保基础模型兼容 |
七、常见问题解答与进阶资源
7.1 常见问题解答 (FAQ)
Stable Diffusion完全免费吗?有没有隐藏收费?
Stable Diffusion本身是完全开源和免费的。你可以自由下载和使用所有核心组件,包括模型、WebUI和扩展,不需要支付任何费用。然而,有一些相关服务可能收费:
- 一些第三方托管服务(如RunwayML、DreamStudio等)
- 某些特殊模型的商业使用许可
- 云计算资源(如使用云GPU服务器运行Stable Diffusion)
但对于个人用户,在自己的电脑上运行完全可以免费使用,没有任何限制或隐藏费用。
我的电脑配置不够,还能使用Stable Diffusion吗?
如果你的电脑配置不满足基本要求,仍有几种方式使用Stable Diffusion:
- 优化版本:使用4bit量化等优化模型,大幅降低显存需求
- 云服务:使用Google Colab(有免费版本)运行Stable Diffusion
- API服务:使用第三方API服务如DreamStudio(按使用量收费)
- CPU模式:虽然速度极慢,但WebUI确实支持纯CPU运行
对于预算有限的用户,Google Colab免费版是个不错的选择,每天可以使用几小时的GPU算力。
生成的图像有版权问题吗?我可以商用吗?
Stable Diffusion生成图像的版权问题较为复杂:
- Stable Diffusion基础模型的许可允许商业使用
- 然而,社区模型可能有各自的许可条款,需要单独查看
- 使用生成图像时需注意避免侵犯已有知识产权(如知名角色、商标等)
一般来说,对于自己创作的原创内容(没有使用受版权保护的元素作为提示词),你通常可以商用生成的图像。但对于重要的商业项目,建议咨询法律专业人士。
为什么我生成的人物手部总是变形?
人物手部变形是Stable Diffusion中的常见问题,原因是训练数据中手部细节相对较少。解决方法:
- 在提示词中特别强调"perfect hands, detailed fingers"
- 在负面提示词中添加"bad hands, extra fingers, fused fingers"
- 使用ControlNet的OpenPose或Depth模式控制手部姿势
- 尝试专注于手部优化的模型,如RealisticVision或某些SDXL模型
- 使用局部重绘功能单独修复手部区域
如何避免模型文件下载中的安全风险?
保障安全的下载模型文件建议:
- 优先选择.safetensors格式,这种格式设计上无法执行恶意代码
- 只从可信来源下载,如官方Hugging Face仓库、知名创作者的Civitai页面
- 使用防病毒软件扫描下载的文件
- 查看社区评价和下载量,流行模型通常更安全
- 如果必须使用.ckpt格式,可以使用转换工具将其转为.safetensors格式
7.2 进阶学习资源
想要深入学习Stable Diffusion的各个方面,以下是一些优质资源:
官方文档和社区
进阶教程和课程
7.3 推荐扩展和工具
除了核心功能外,以下扩展和工具可以显著增强你的Stable Diffusion使用体验:
| 扩展/工具名称 | 功能描述 | 安装方法 |
|---|---|---|
| ReActor | 高级人脸交换和修复工具 | 通过WebUI扩展仓库搜索安装 |
| Image Browser | 强大的图像浏览和管理扩展 | 通过WebUI扩展仓库搜索安装 |
| Prompt Travel | 创建提示词动画和过渡效果 | 通过URL安装:添加GitHub仓库链接 |
| Deforum | 专业视频生成和动画制作 | 通过URL安装:添加GitHub仓库链接 |
| ComfyUI | 节点式界面,实现高度自定义的工作流 | 独立安装,GitHub官方仓库提供安装指南 |
总结与展望
通过这份完整指南,你已经掌握了Stable Diffusion的核心知识和使用技巧,从基础概念到高级功能,从安装配置到模型训练。作为一种革命性的AI创意工具,Stable Diffusion正在不断发展,未来将有更多令人兴奋的可能性。
未来发展趋势
- 视频生成技术的成熟:Stable Video Diffusion等技术正在快速进步
- 多模态融合:文本、图像、音频、视频的整合创作
- 更高的控制精度:更先进的控制技术和工作流
- 更低的硬件门槛:更高效的模型和优化技术
- 更丰富的创意应用:在游戏、影视、设计等领域的广泛应用
创作者社区的力量
作为开源项目,Stable Diffusion的成功很大程度上归功于活跃的创作者社区。参与分享、学习和贡献,不仅能提升自己的技能,也能推动整个技术的发展。
🌟 持续学习的建议:
- 定期关注官方更新和社区动态
- 实验新模型和新技术,保持创作的新鲜感
- 参与社区讨论,分享你的经验和作品
- 记录你的学习过程,建立个人知识库
- 尝试将AI创作融入你的专业领域,创造独特价值
希望本指南能够帮助你在AI艺术创作的旅程中取得成功!无论你是艺术家、设计师、开发者还是爱好者,Stable Diffusion都为你提供了一个强大的创意工具,让我们一起探索AI艺术的无限可能!
— 本文最后更新于2025年3月15日 —