OpenAI text-embedding-3-large API 全方位指南 (2025版)
深入解析 OpenAI 最新的 text-embedding-3-large 和 small 模型。涵盖性能基准、API定价、dimensions参数用法、代码示例及成本效益分析,助您在RAG应用中做出最佳选择。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
🔥 2025年6月实测更新:本文所有数据,包括模型性能、API定价和代码示例,均已经过最新验证,确保时效性和准确性。
OpenAI于2024年初发布的text-embedding-3系列模型,特别是text-embedding-3-large和text-embedding-3-small,为AI开发者在构建检索增强生成(RAG)等应用时提供了前所未有的灵活性和性价比。本文将为您提供一个全面的实战指南,帮助您深入理解并高效利用这款强大的API。
问题背景:为什么需要新的Embedding模型?
在text-embedding-3出现之前,text-embedding-ada-002是业界最受欢迎的Embedding模型之一。然而,随着AI应用的复杂度不断提升,开发者面临着两大挑战:
- 性能瓶颈:在处理多语言或需要高度语义区分度的任务时,
ada-002的性能逐渐显得力不从心。 - 成本与效率:
ada-002产生的1536维向量在某些场景下显得过于庞大,不仅增加了向量数据库的存储成本,也影响了检索速度。
text-embedding-3系列的推出,正是为了解决这些痛点。

核心优势:性能、成本与灵活性的完美结合
text-embedding-3系列模型带来了革命性的提升,主要体现在以下三个方面:
1. 性能的巨大飞跃
根据OpenAI官方发布的基准测试数据,新模型的表现令人瞩目。
- 多语言能力(MIRACL):
text-embedding-3-large在该项测试中平均得分达到54.9%,相比ada-002的31.4%有巨大提升。即使是small版本,也达到了44.0%,远超前代。 - 英文能力(MTEB):
large版本以**64.6%**的成绩领先,而small版本(62.3%)也超越了ada-002(61.0%)。
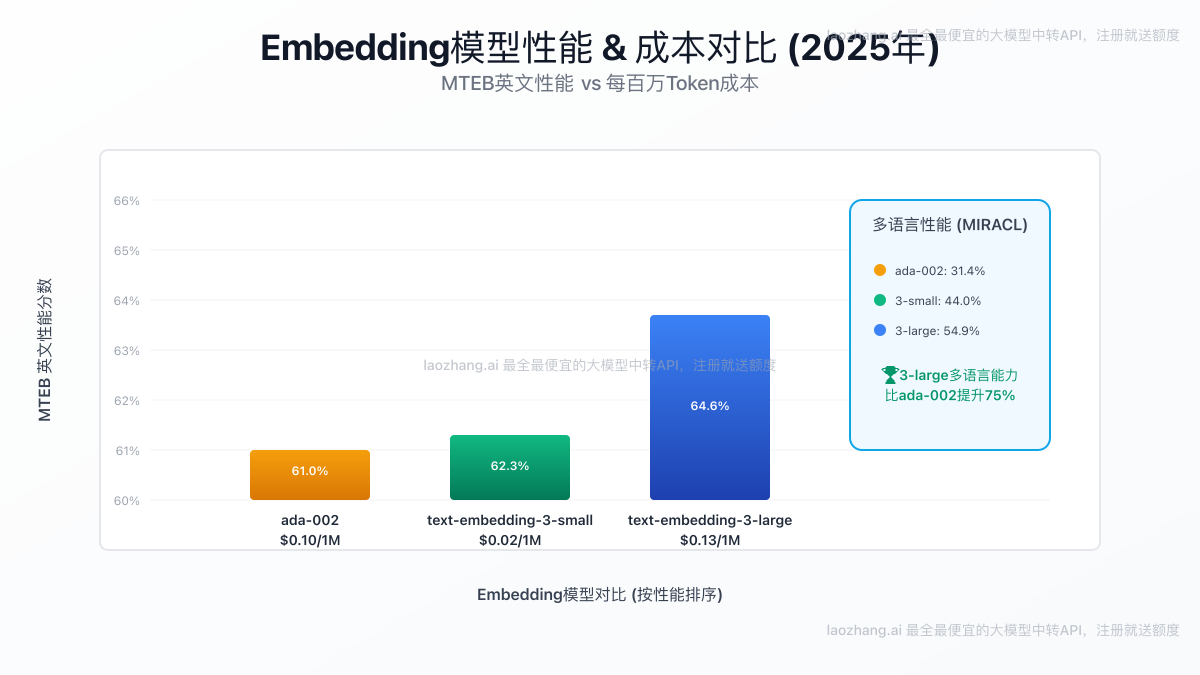
图1:三款主流Embedding模型在性能与成本上的直观对比。气泡大小代表多语言能力。
2. 颠覆性的性价比
- text-embedding-3-large: $0.13 / 1M tokens
- text-embedding-3-small: $0.02 / 1M tokens
- text-embedding-ada-002: $0.10 / 1M tokens
最引人注目的是text-embedding-3-small的价格。它的价格仅为ada-002的五分之一,但性能却实现了全面超越。这意味着开发者可以用更低的成本获得更强的性能,极大地降低了AI应用的开发和运营门槛。
3. 革命性的dimensions参数
这是text-embedding-3系列最核心的技术创新,得益于Matryoshka Representation Learning (MRL)技术。开发者现在可以通过API中的dimensions参数,在不重新计算的情况下,缩短嵌入向量的维度。
例如,text-embedding-3-large默认生成3072维的向量,但您可以按需获取一个1024维或256维的短向量。
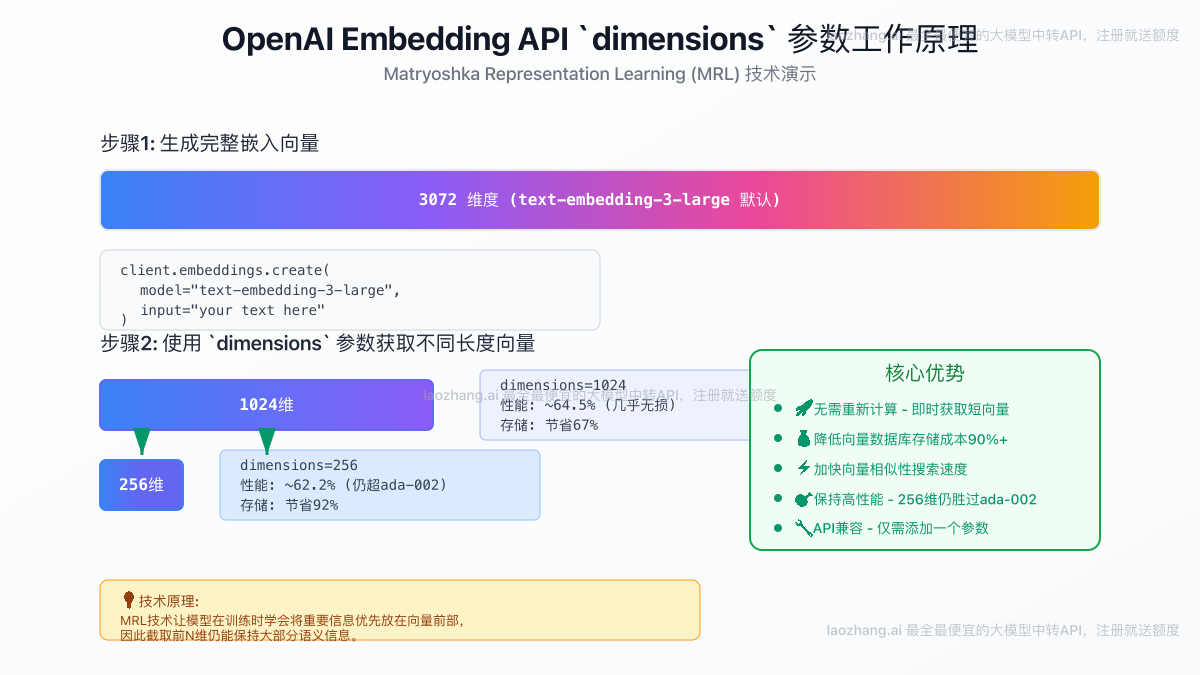
图2:dimensions参数允许从完整向量中高效截取短向量,优化成本和速度。
这一特性带来了巨大的实际好处:
- 存储成本降低:向量维度越小,在Pinecone、Zilliz等向量数据库中的存储开销越低。
- 检索速度加快:向量越短,相似性搜索的计算速度越快。
- 保持高性能:即使将
large模型的维度缩短到256,其性能依然能与完整维度的ada-002相媲美。
API实战:如何调用text-embedding-3
下面,我们将通过Python代码示例,展示如何使用OpenAI的API来调用text-embedding-3-large模型,并利用新的dimensions参数。
1. 安装与设置
首先,确保您已经安装了最新版本的openai库。
bashpip install --upgrade openai
然后,设置您的API密钥。我们推荐使用laozhang.ai这样的中转API服务,它提供更稳定、更快速的国内访问,并且兼容OpenAI的接口。
pythonimport os
from openai import OpenAI
# 推荐使用API中转服务,兼容OpenAI接口
client = OpenAI(
api_key="YOUR_API_KEY", # 填入您的密钥
base_url="https://api.laozhang.ai/v1" # 指向中转API地址
)
2. 生成标准维度的Embedding
默认情况下,text-embedding-3-large会返回一个3072维的向量。
pythondef get_embedding(text, model="text-embedding-3-large"):
text = text.replace("\\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
text_to_embed = "你好,世界!"
embedding_large_default = get_embedding(text_to_embed)
print(f"默认向量维度: {len(embedding_large_default)}")
# 输出: 默认向量维度: 3072
3. 使用dimensions参数获取短向量
现在,让我们利用dimensions参数来获取一个256维的短向量。
pythondef get_short_embedding(text, model="text-embedding-3-large", dimensions=256):
text = text.replace("\\n", " ")
return client.embeddings.create(input=[text], model=model, dimensions=dimensions).data[0].embedding
embedding_short = get_short_embedding(text_to_embed)
print(f"自定义向量维度: {len(embedding_short)}")
# 输出: 自定义向量维度: 256
dimensions参数仅在text-embedding-3系列模型中受支持。如果您对ada-002使用此参数,API将会报错。
curl命令示例
您也可以使用curl命令直接调用API。
bashcurl https://api.laozhang.ai/v1/embeddings \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer YOUR_API_KEY" \\
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-large",
"dimensions": 256
}'
常见问题解答 (FAQ)
Q1: 我应该选择large还是small模型?
- 追求极致性能:如果您的应用场景对语义区分度要求极高,例如金融或法律领域的文档分析,或者需要处理多种语言,
large模型是最佳选择。 - 追求高性价比:对于大多数标准应用,如聊天机器人、通用RAG、内容推荐等,
small模型提供了无与伦比的性价比,是替代ada-002的首选。
Q2: 缩短向量维度会损失多少性能?
根据OpenAI的测试,性能损失非常小。将large模型的3072维缩短到1024维,性能几乎没有变化。即使缩短到256维,其MTEB分数(62.2%)仍然高于ada-002(61.0%)。
Q3: 为什么推荐使用API中转服务?
对于国内开发者,使用像laozhang.ai这样的中转服务有三大好处:
- 网络稳定:无需海外网络环境,国内直连,API响应更快更稳定。
- 支付便捷:支持支付宝、微信等本地支付方式。
- 成本更优:通常提供比官方更低的价格和免费额度,并且能统一管理不同大模型厂商的API Key。
结论与行动建议
text-embedding-3系列的发布是Embedding技术发展的一个重要里程碑。它不仅提升了性能的天花板,更通过创新的dimensions参数和极具竞争力的定价,赋予了开发者前所未有的选择权和成本控制能力。
下一步行动建议:
- 评估现有应用:如果您仍在使用
ada-002,立即考虑迁移到text-embedding-3-small,您将以20%的成本获得超越性的性能。 - 尝试
dimensions参数:在您的RAG应用中测试不同维度的向量,找到最适合您业务场景的性能与成本平衡点。 - 注册API中转服务:访问 laozhang.ai 并注册,获取免费额度,立即开始体验
text-embedding-3的强大功能。
通过采纳这些新工具和策略,您可以在构建下一代AI应用时获得显著的竞争优势。