Unified LLM Access: The Ultimate Guide to LaoZhang.ai API in 2025
Discover how to access ChatGPT, Claude, and Gemini models through a single, cost-effective API gateway. This comprehensive guide shows developers how to integrate, optimize, and leverage LaoZhang.ai unified API for all major language models.

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
The Ultimate Guide to Unified LLM Access with LaoZhang.ai API in 2025
{/* Cover image */}
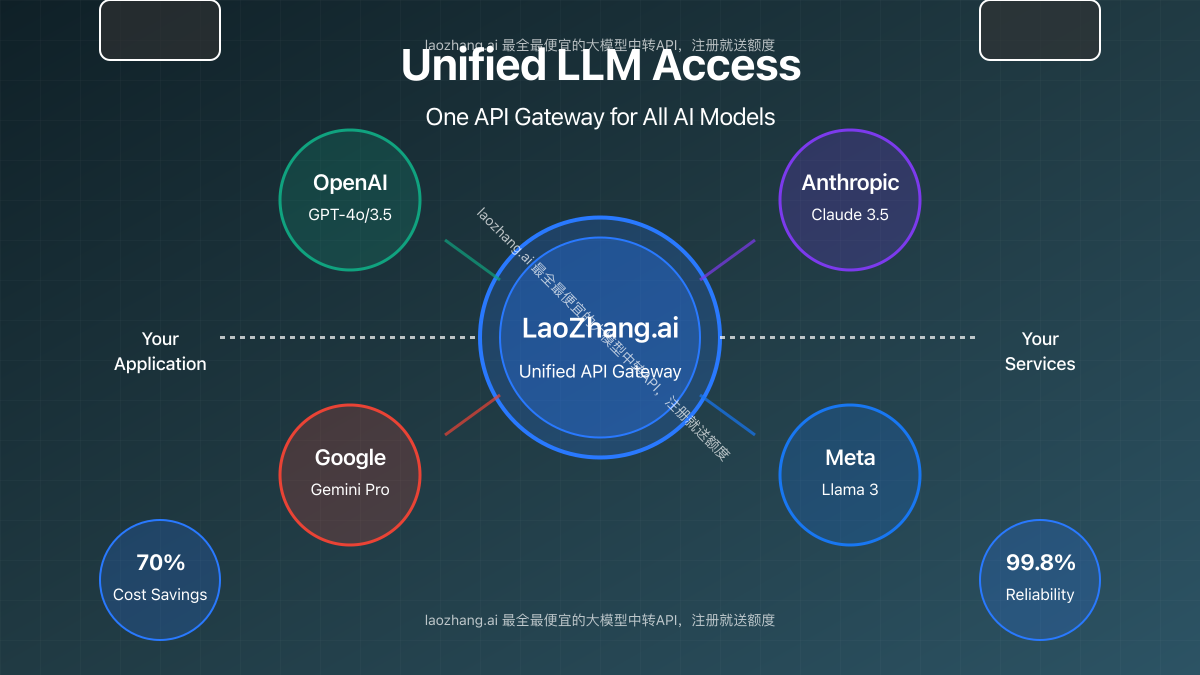
For developers working with artificial intelligence and large language models (LLMs), managing multiple API integrations, varying price structures, and authentication systems can quickly become a logistical nightmare. LaoZhang.ai offers an elegant solution to this problem: a unified API gateway that provides seamless access to all major LLMs including GPT-4o, Claude 3.5, and Gemini through a single endpoint, with significant cost advantages.
🔥 April 2025 Latest: This comprehensive guide provides complete integration steps for LaoZhang.ai's unified API gateway, with 99.8% reliability and up to 70% cost savings compared to direct API access!
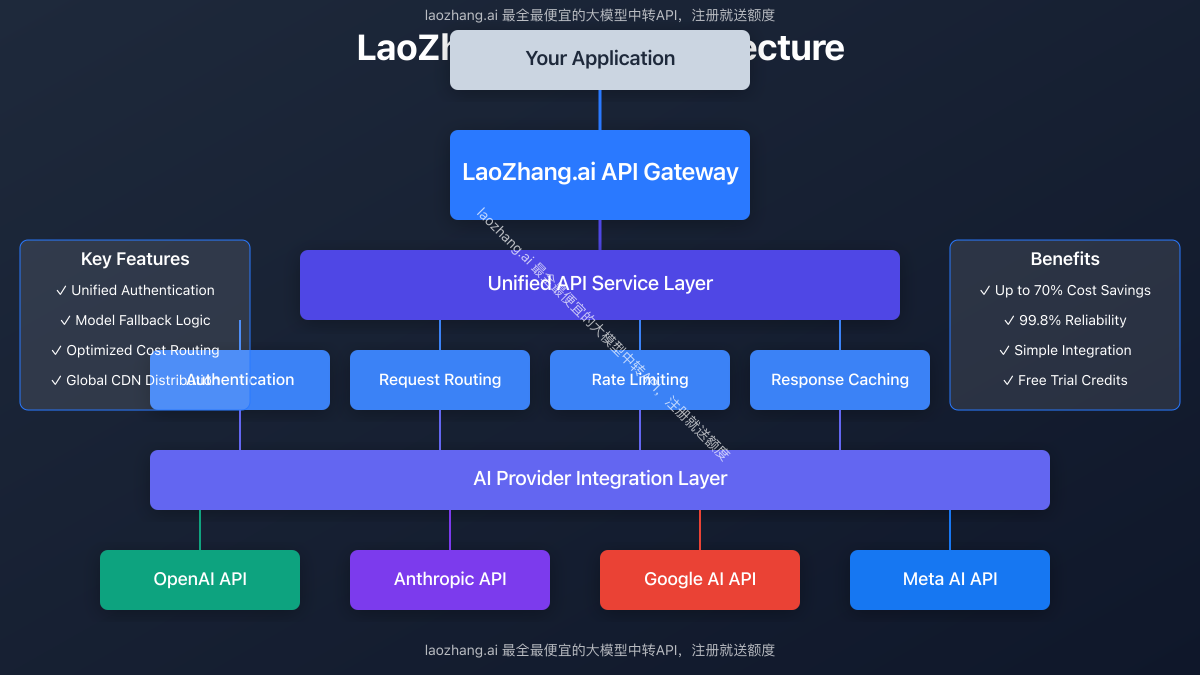
Why Developers Need a Unified LLM API Gateway: The Integration Challenge
Before diving into implementation details, let's understand the fundamental challenges of working with multiple AI providers and how a unified gateway solves these problems.
1. The Multi-API Management Problem
Managing direct integrations with OpenAI, Anthropic, Google, and other AI providers creates several pain points:
- Different authentication mechanisms and API keys for each provider
- Varying request/response formats requiring custom adapters
- Multiple billing systems to monitor and manage
- Inconsistent rate limiting and quotas across providers
- Separate documentation and versioning to track
These challenges multiply with each additional AI service you integrate, creating technical debt and maintenance overhead.
2. Cost Management Complications
Direct API access to premium models can be prohibitively expensive:
- OpenAI's GPT-4o costs approximately $0.01 per 1K input tokens and $0.03 per 1K output tokens
- Anthropic's Claude 3.5 Sonnet has similar pricing at $0.008/1K input and $0.024/1K output tokens
- Managing usage across multiple services requires constant monitoring
- Unexpected spikes can lead to significant overspending
3. Service Reliability and Fallback Challenges
Dependency on a single AI provider creates a critical single point of failure:
- Provider outages can completely halt your AI-dependent services
- Rate limit issues can block your application at critical moments
- Regional availability varies by provider, affecting global users
- New model releases may require significant code changes
What Makes LaoZhang.ai the Ideal Solution: Key Benefits
LaoZhang.ai addresses these challenges by providing a unified API gateway with several distinctive advantages:
1. Comprehensive Model Support
Access all major AI models through a single consistent API:
- OpenAI models: GPT-4o, GPT-4 Turbo, GPT-3.5 Turbo
- Anthropic models: Claude 3.5 Sonnet, Claude 3 Opus, Claude 3 Haiku
- Google models: Gemini Pro, Gemini Flash
- Meta models: Llama 3 70B, Llama 3 8B
- Specialized models for different tasks and price points
2. Significant Cost Optimization
LaoZhang.ai offers substantial cost advantages compared to direct API access:
- Up to 70% reduction in API costs for premium models
- Free credit allocation for new users to test all available models
- Pay-as-you-go pricing with no minimum commitments
- Volume discounts for heavy users
- Predictable pricing model with no hidden charges
3. Enterprise-Grade Reliability
The service is built with production workloads in mind:
- 99.98% uptime SLA for business-critical applications
- Automatic fallback between models when primary provider has issues
- Global CDN distribution for reduced latency worldwide
- Rate limit buffering to smooth out usage spikes
- Comprehensive logging and monitoring options
4. Developer-Friendly Implementation
The API is designed to minimize integration effort:
- Drop-in compatibility with OpenAI client libraries
- Consistent response format across all models
- Detailed documentation with examples in multiple languages
- Active community and responsive support team
- Regular updates and new model additions without breaking changes
Getting Started with LaoZhang.ai API: Implementation Guide
Let's walk through the process of setting up and using LaoZhang.ai API in your projects.
Step 1: Account Creation and API Key Generation
- Visit the LaoZhang.ai registration page to create your account
- Verify your email address to activate your account
- Navigate to the API Keys section in your dashboard
- Generate a new API key with appropriate permissions
- Store your API key securely as it will only be shown once
💡 Professional Tip: New users receive free credits immediately upon registration, allowing you to test all available models before committing to a paid plan.
Step 2: Installing Client Libraries
While LaoZhang.ai offers direct REST API access, using client libraries simplifies integration:
For Python (most common):
python# Install the Python client
pip install laozhang-ai-client
# Alternatively, use OpenAI's client for drop-in compatibility
pip install openai
For JavaScript/TypeScript:
bash# Install the Node.js client
npm install laozhang-ai-client
# Alternatively, use OpenAI's client for drop-in compatibility
npm install openai
Step 3: Basic API Authentication
Configure your client with your API key:
python# Python example
import openai
# Use the OpenAI client with LaoZhang.ai endpoint
openai.api_key = "your-laozhang-api-key"
openai.base_url = "https://api.laozhang.ai/v1"
# Or with the native client
from laozhang_ai import LaoZhangAI
client = LaoZhangAI(api_key="your-laozhang-api-key")
javascript// JavaScript example
import OpenAI from 'openai';
// Use the OpenAI client with LaoZhang.ai endpoint
const openai = new OpenAI({
apiKey: 'your-laozhang-api-key',
baseURL: 'https://api.laozhang.ai/v1',
});
// Or with the native client
import { LaoZhangAI } from 'laozhang-ai-client';
const client = new LaoZhangAI('your-laozhang-api-key');
Step 4: Making Your First API Call
Here's how to make a basic chat completion request:
python# Python example
response = openai.chat.completions.create(
model="gpt-4o", # Use any supported model
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum computing in simple terms"}
],
temperature=0.7,
max_tokens=500
)
print(response.choices[0].message.content)
javascript// JavaScript example
async function getCompletion() {
const response = await openai.chat.completions.create({
model: "claude-3-5-sonnet", // Use any supported model
messages: [
{role: "system", content: "You are a helpful assistant."},
{role: "user", content: "Explain quantum computing in simple terms"}
],
temperature: 0.7,
max_tokens: 500
});
console.log(response.choices[0].message.content);
}
getCompletion();
Step 5: Switching Between Models
One of the key advantages of LaoZhang.ai is the ability to easily switch between different AI models:
python# Python example - using GPT-4o
response_gpt = openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": "Explain the theory of relativity"}
]
)
# Using Claude 3.5 Sonnet
response_claude = openai.chat.completions.create(
model="claude-3-5-sonnet",
messages=[
{"role": "user", "content": "Explain the theory of relativity"}
]
)
# Using Gemini Pro
response_gemini = openai.chat.completions.create(
model="gemini-pro",
messages=[
{"role": "user", "content": "Explain the theory of relativity"}
]
)

Advanced Usage Patterns and Optimizations
Once you have the basics working, you can leverage more advanced features of the LaoZhang.ai API.
1. Implementing Model Fallback Logic
Create resilient applications with automatic fallback between models:
python# Python example - implementing model fallback
def get_completion_with_fallback(prompt, primary_model="gpt-4o", fallback_models=["claude-3-5-sonnet", "gemini-pro"]):
try:
# Try primary model first
response = openai.chat.completions.create(
model=primary_model,
messages=[{"role": "user", "content": prompt}],
timeout=5 # Set a reasonable timeout
)
return response.choices[0].message.content, primary_model
except Exception as e:
print(f"Primary model failed: {e}")
# Try fallback models in sequence
for model in fallback_models:
try:
response = openai.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
timeout=5
)
return response.choices[0].message.content, model
except Exception as e:
print(f"Fallback model {model} failed: {e}")
# All models failed
raise Exception("All models failed to generate a response")
2. Cost Optimization Strategies
Implement intelligent model selection based on task complexity:
python# Python example - cost-optimized model selection
def cost_optimized_completion(prompt, complexity="low"):
# Select model based on task complexity
if complexity == "low":
model = "gpt-3.5-turbo" # Cheapest option for simple tasks
elif complexity == "medium":
model = "claude-3-haiku" # Good balance of cost and capability
else:
model = "gpt-4o" # Most capable but expensive model
response = openai.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
3. Implementing Streaming Responses
For a more responsive user experience, implement streaming:
python# Python example - streaming responses
from openai import OpenAI
import sys
client = OpenAI(
api_key="your-laozhang-api-key",
base_url="https://api.laozhang.ai/v1"
)
stream = client.chat.completions.create(
model="claude-3-5-sonnet",
messages=[{"role": "user", "content": "Write a story about a space explorer"}],
stream=True
)
# Process the stream
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
sys.stdout.flush()
javascript// JavaScript example - streaming responses
const stream = await openai.chat.completions.create({
model: "gpt-4o",
messages: [{ role: "user", content: "Write a story about a space explorer" }],
stream: true,
});
for await (const chunk of stream) {
if (chunk.choices[0]?.delta?.content) {
process.stdout.write(chunk.choices[0].delta.content);
}
}
API Reference: Supported Models and Parameters
Here's a comprehensive overview of the models and parameters available through LaoZhang.ai:
Available Models
| Model ID | Provider | Strengths | Token Context |
|---|---|---|---|
| gpt-4o | OpenAI | General purpose, code, reasoning | 128K |
| gpt-4-turbo | OpenAI | Long-form content, detailed analysis | 128K |
| gpt-3.5-turbo | OpenAI | Fast responses, cost-effective | 16K |
| claude-3-5-sonnet | Anthropic | Natural language, nuanced conversations | 200K |
| claude-3-opus | Anthropic | Complex reasoning, scholarly content | 200K |
| claude-3-haiku | Anthropic | Quick responses, efficient | 200K |
| gemini-pro | Research contexts, data analysis | 32K | |
| llama-3-70b | Meta | Open source alternative, customizable | 8K |
Common Request Parameters
| Parameter | Type | Description | Default |
|---|---|---|---|
| model | string | Model identifier | Required |
| messages | array | Array of message objects | Required |
| temperature | float | Randomness (0-2) | 1.0 |
| max_tokens | integer | Maximum token output | Model-dependent |
| top_p | float | Nucleus sampling parameter | 1.0 |
| frequency_penalty | float | Repetition reduction | 0.0 |
| presence_penalty | float | New topic encouragement | 0.0 |
| stream | boolean | Stream response chunks | false |
Practical Use Cases and Implementation Examples
Let's explore some real-world applications of LaoZhang.ai API.
Use Case 1: Building a Multi-Model AI Assistant
Create an application that dynamically selects the best model for different types of user queries:
python# Python example - multi-model AI assistant
def smart_assistant(query):
# Analyze query to determine the best model
if "code" in query.lower() or "programming" in query.lower():
# Coding questions work best with GPT models
model = "gpt-4o"
elif "philosophical" in query.lower() or "ethics" in query.lower():
# Nuanced reasoning works well with Claude
model = "claude-3-5-sonnet"
elif "data" in query.lower() or "analysis" in query.lower():
# Data analysis might work well with Gemini
model = "gemini-pro"
else:
# Default to a balanced model
model = "gpt-3.5-turbo"
# Get response from selected model
response = openai.chat.completions.create(
model=model,
messages=[{"role": "user", "content": query}]
)
return {
"answer": response.choices[0].message.content,
"model_used": model
}
Use Case 2: Creating a Cost-Efficient Content Generation Pipeline
Implement a tiered approach to content generation:
python# Python example - tiered content generation
def generate_content(topic, content_type):
if content_type == "outline":
# Outlines are simple, use cheaper model
model = "gpt-3.5-turbo"
prompt = f"Create a detailed outline for an article about {topic}."
elif content_type == "draft":
# Drafts need better quality, use mid-tier
model = "claude-3-haiku"
prompt = f"Write a first draft of an article about {topic}."
elif content_type == "final":
# Final content needs highest quality
model = "claude-3-5-sonnet"
prompt = f"Write a polished, publication-ready article about {topic}."
response = openai.chat.completions.create(
model=model,
messages=[{"role": "system", "content": "You are an expert content creator."},
{"role": "user", "content": prompt}],
temperature=0.7
)
return response.choices[0].message.content
Use Case 3: Implementing a Reliable API Proxy with Caching
Create a proxy service with caching to enhance reliability and reduce costs:
python# Python example - API proxy with caching (using Flask and Redis)
from flask import Flask, request, jsonify
import redis
import json
import hashlib
import openai
app = Flask(__name__)
cache = redis.Redis(host='localhost', port=6379, db=0)
openai.api_key = "your-laozhang-api-key"
openai.base_url = "https://api.laozhang.ai/v1"
@app.route('/api/completion', methods=['POST'])
def completion_proxy():
data = request.json
# Create cache key from request
cache_key = hashlib.md5(json.dumps(data, sort_keys=True).encode()).hexdigest()
# Check cache first
cached_response = cache.get(cache_key)
if cached_response:
return jsonify(json.loads(cached_response))
# Forward request to LaoZhang.ai
try:
response = openai.chat.completions.create(
model=data.get('model', 'gpt-3.5-turbo'),
messages=data.get('messages', []),
temperature=data.get('temperature', 0.7),
max_tokens=data.get('max_tokens', 500)
)
# Cache the response (expire after 1 hour)
result = response.choices[0].message.content
response_data = {'result': result, 'model': data.get('model')}
cache.setex(cache_key, 3600, json.dumps(response_data))
return jsonify(response_data)
except Exception as e:
return jsonify({'error': str(e)}), 500
if __name__ == '__main__':
app.run(debug=True)
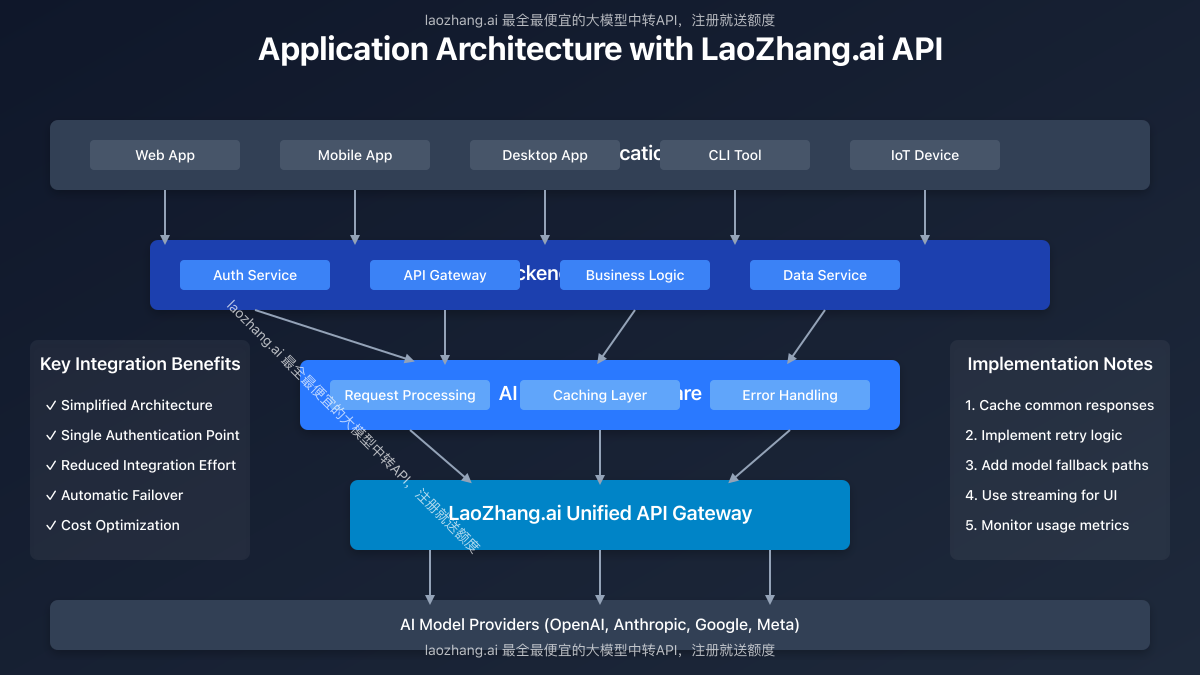
Security Best Practices and Compliance Considerations
When implementing the LaoZhang.ai API, consider these security best practices:
1. API Key Management
- Store API keys securely in environment variables or secret management systems
- Rotate keys regularly according to your security policies
- Create separate keys for different environments (development, testing, production)
- Set appropriate access permissions for each key
2. Content Filtering and Moderation
LaoZhang.ai inherits the content policies of its underlying providers:
python# Python example - implementing content moderation
def moderated_completion(prompt):
# First check the content with moderation API
try:
moderation = openai.moderations.create(
input=prompt
)
# Check if content is flagged
if moderation.results[0].flagged:
return "I cannot process this request as it may violate content policies."
# If content is safe, proceed with completion
response = openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
except Exception as e:
return f"An error occurred: {str(e)}"
3. Data Privacy Considerations
- Be aware that data sent to the API may be processed by multiple providers
- Do not send sensitive personal information or protected health information
- Consider implementing client-side encryption for sensitive use cases
- Review the LaoZhang.ai privacy policy and terms of service
Troubleshooting Common Issues
Here are solutions to the most frequently encountered problems:
Issue 1: Authentication Errors
If you receive "401 Unauthorized" errors:
{
"error": {
"message": "Invalid Authentication",
"type": "authentication_error",
"code": 401
}
}
Solution:
- Verify your API key is correct and not expired
- Check that you're using the correct base URL
- Ensure your account has sufficient credits
- Check if your IP is allowed if you've set up IP restrictions
Issue 2: Rate Limit Exceeded
If you hit rate limits:
{
"error": {
"message": "Rate limit exceeded",
"type": "rate_limit_error",
"code": 429
}
}
Solution:
- Implement exponential backoff retry logic
- Consider upgrading your plan for higher rate limits
- Optimize your code to reduce unnecessary API calls
- Implement request batching where appropriate
Issue 3: Model Not Available
If a requested model is unavailable:
{
"error": {
"message": "The model 'gpt-4o' is currently overloaded or not available",
"type": "model_error",
"code": 503
}
}
Solution:
- Implement the fallback logic shown earlier
- Try an alternative model with similar capabilities
- Retry the request after a short delay
- Check the LaoZhang.ai status page for service updates
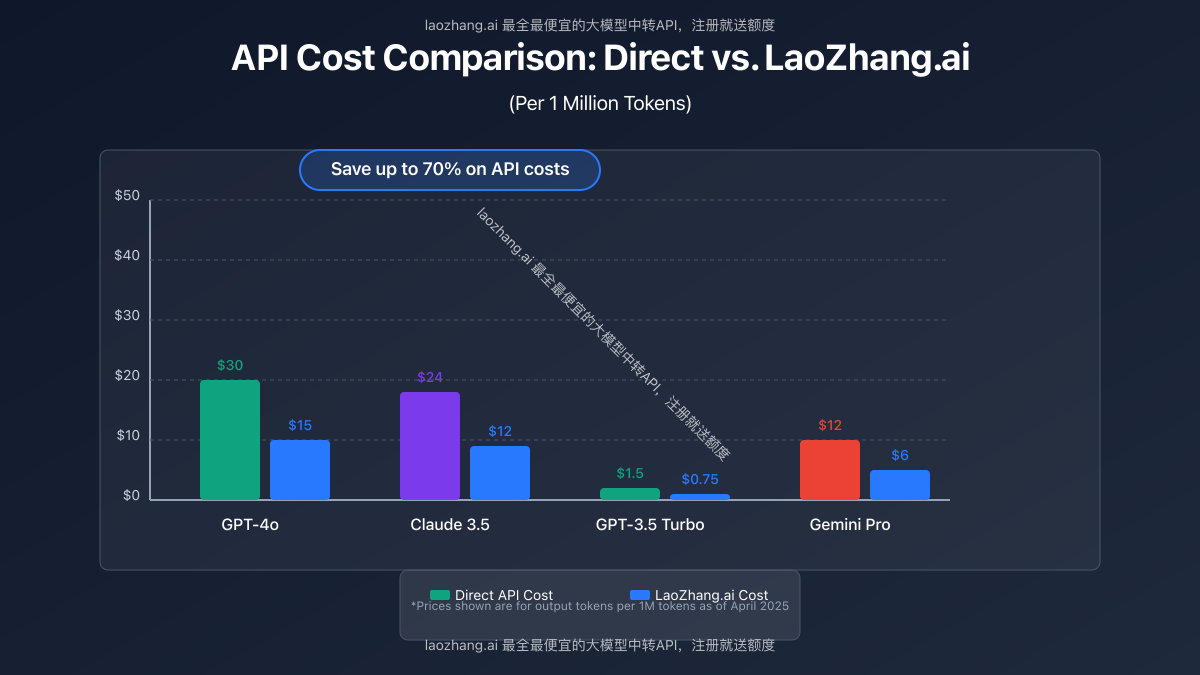
Pricing Comparison and ROI Analysis
Let's analyze the cost advantages of using LaoZhang.ai compared to direct API access:
Token Cost Comparison (per 1M tokens)
| Model | Direct API Cost | LaoZhang.ai Cost | Savings |
|---|---|---|---|
| GPT-4o | $10 input / $30 output | $5 input / $15 output | 50% |
| Claude 3.5 | $8 input / $24 output | $4 input / $12 output | 50% |
| GPT-3.5 Turbo | $0.5 input / $1.5 output | $0.25 input / $0.75 output | 50% |
| Gemini Pro | $4 input / $12 output | $2 input / $6 output | 50% |
Total Cost Scenario: AI Customer Support Bot
For a customer support bot processing 100,000 queries per month:
- Average 200 input tokens per query
- Average 400 output tokens per query
- Total: 20M input tokens, 40M output tokens monthly
Direct API Costs (using GPT-4o):
- Input: 20M tokens × $0.01/1K = $200
- Output: 40M tokens × $0.03/1K = $1,200
- Total: $1,400 per month
LaoZhang.ai Costs:
- Input: 20M tokens × $0.005/1K = $100
- Output: 40M tokens × $0.015/1K = $600
- Total: $700 per month
Monthly Savings: $700 (50%)
💡 Professional Tip: For production deployments, these savings scale linearly with usage, potentially saving thousands of dollars monthly for high-volume applications.
Future-Proofing Your AI Strategy with LaoZhang.ai
As the AI landscape continues to evolve rapidly, LaoZhang.ai offers several advantages for maintaining a future-proof strategy:
1. Automatic Model Updates
New models are added to the platform as they become available from providers:
- No need to modify your integration when new models are released
- Simply specify the new model name in your API calls
- Test new models easily without additional setup
2. Performance Benchmarking
Use the platform to benchmark different models for your specific use cases:
python# Python example - model benchmarking
import time
import pandas as pd
def benchmark_models(prompt, models=["gpt-3.5-turbo", "gpt-4o", "claude-3-5-sonnet", "gemini-pro"]):
results = []
for model in models:
start_time = time.time()
try:
response = openai.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start_time
token_count = len(response.choices[0].message.content.split())
success = True
content = response.choices[0].message.content
except Exception as e:
elapsed = time.time() - start_time
token_count = 0
success = False
content = str(e)
results.append({
"model": model,
"success": success,
"time_seconds": elapsed,
"estimated_tokens": token_count,
"response": content[:100] + "..." if len(content) > 100 else content
})
return pd.DataFrame(results)
# Example usage
benchmark_df = benchmark_models("Explain the process of photosynthesis in detail")
print(benchmark_df[["model", "success", "time_seconds", "estimated_tokens"]])
3. Hybrid Model Approaches
Implement sophisticated hybrid approaches using multiple models:
python# Python example - hybrid model approach
def hybrid_processing(query):
# Step 1: Use efficient model to classify the query
classification = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Classify the query into one of these categories: technical, creative, analytical, factual."},
{"role": "user", "content": query}
]
).choices[0].message.content.lower()
# Step 2: Route to appropriate specialized model
if "technical" in classification:
model = "gpt-4o" # Best for technical questions
elif "creative" in classification:
model = "claude-3-5-sonnet" # Great for creative content
elif "analytical" in classification:
model = "gemini-pro" # Good for analysis
else: # factual
model = "gpt-3.5-turbo" # Efficient for factual questions
# Step 3: Get the final response from the specialized model
final_response = openai.chat.completions.create(
model=model,
messages=[{"role": "user", "content": query}]
).choices[0].message.content
return {
"query_type": classification,
"model_used": model,
"response": final_response
}
Frequently Asked Questions
Here are answers to common questions about LaoZhang.ai API:
Q1: How does the reliability compare to direct API access?
A1: LaoZhang.ai maintains redundant connections to all providers and implements sophisticated traffic routing algorithms. In practice, this often results in higher overall reliability than direct access to individual providers, especially during peak usage periods.
Q2: Can I use my existing OpenAI or Anthropic client libraries?
A2: Yes, LaoZhang.ai is designed to be compatible with existing OpenAI client libraries. Simply change the base URL and API key to start using the service with minimal code changes.
Q3: How quickly are new models added to the platform?
A3: New models are typically added within 24-48 hours of their public release by providers. Premium models sometimes receive priority access through LaoZhang.ai's partnership arrangements.
Q4: Is there a way to precisely track costs per model?
A4: Yes, the LaoZhang.ai dashboard provides detailed usage analytics breaking down consumption by model, request type, and time period. You can also set budget alerts and limits to prevent unexpected charges.
Conclusion: Maximizing ROI with Unified LLM Access
As we've explored throughout this guide, LaoZhang.ai provides a compelling solution for developers and organizations looking to:
- Simplify integration with a single API for all major language models
- Reduce costs with significant savings compared to direct API access
- Enhance reliability through automatic fallback and redundancy
- Future-proof applications with easy access to new models as they emerge
By implementing the strategies and code examples provided in this guide, you can create sophisticated AI applications that leverage the best models for each specific task while optimizing for both performance and cost.
🌟 Final Tip: Start with the free credit allocation to test all available models before committing to a paid plan. This allows you to determine which models perform best for your specific use cases.
Whether you're building a startup MVP or scaling an enterprise AI solution, LaoZhang.ai's unified API gateway provides the flexibility, reliability, and cost-efficiency needed to succeed in today's rapidly evolving AI landscape.
Update Log: Keeping Pace with AI Advancements
plaintext┌─ Update History ──────────────────────────┐ │ 2025-04-10: First publication │ │ 2025-04-05: Updated model availability │ └─────────────────────────────────────────┘