ChatGPT API速率限制完全指南2025:从入门到企业级优化策略
深入解析ChatGPT API速率限制机制,包括最新的层级系统、各模型限制对比、错误处理方案及企业级优化策略。助您高效管理API调用,避免超限。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
在开发基于ChatGPT API的应用时,你是否遇到过突如其来的"Rate limit reached"错误?是否因为ChatGPT API速率限制而导致服务中断,影响用户体验?2025年,OpenAI对API速率限制进行了重大调整,免费用户的限制从每分钟20次降至仅3次,而GPT-4o模型的处理能力却提升了5倍。理解并合理管理ChatGPT API速率限制已成为每个AI应用开发者的必修课。
📊 关键数据:根据OpenAI最新数据,超过73%的API调用失败是由于速率限制导致的,而通过合理的优化策略,可以将这一比例降低到5%以下。
无论你是刚接触ChatGPT API速率限制的初学者,还是正在为企业级应用寻找扩展方案的架构师,本指南都将为你提供全面的解决方案。从基础的RPM和TPM概念,到高级的负载均衡策略,我们将深入探讨如何在ChatGPT API速率限制框架内最大化API使用效率。
本文将揭示OpenAI从未公开的层级系统细节,教你如何从Tier 1升级到Tier 5,将月度使用限额从500美元提升至20万美元。更重要的是,我们将分享经过实战验证的错误处理方案和成本优化策略,帮助你构建稳定、高效、经济的AI应用系统。

什么是ChatGPT API速率限制?为什么如此重要?
ChatGPT API速率限制是OpenAI为了保护API服务稳定性而设置的访问控制机制。它限制了用户或应用程序在特定时间窗口内可以向API发送的请求数量和处理的数据量。这不仅仅是简单的访问限制,而是一个复杂的多维度控制系统,直接影响着你的应用性能和用户体验。
速率限制的五大核心指标
OpenAI的ChatGPT API速率限制通过五个关键指标来衡量和控制API使用:
1. RPM (Requests Per Minute) - 每分钟请求数 这是最直观的ChatGPT API速率限制指标,控制你每分钟可以发送的API请求总数。例如,免费账户的ChatGPT API速率限制仅为3 RPM,意味着每分钟最多只能发送3个请求,平均每20秒才能处理一个请求。理解RPM限制是掌握ChatGPT API速率限制的第一步。
2. TPM (Tokens Per Minute) - 每分钟令牌数 令牌是ChatGPT API速率限制的核心计算单位,大约等于0.75个英文单词或0.5个中文字符。TPM限制了你每分钟可以处理的总令牌数,包括输入提示词和生成的响应。这个ChatGPT API速率限制指标对长文本处理尤其重要,直接影响应用的处理能力。
3. RPD (Requests Per Day) - 每日请求数 某些模型和账户类型还设置了每日请求上限,这是ChatGPT API速率限制的长期控制维度,防止短时间内的过度使用。合理规划RPD使用对于管理ChatGPT API速率限制至关重要。
4. TPD (Tokens Per Day) - 每日令牌数 与RPD类似,TPD限制了24小时内的总令牌消耗量,这对需要处理大量数据的应用来说是ChatGPT API速率限制的关键约束。
5. IPM (Images Per Minute) - 每分钟图像数 针对DALL-E等图像生成API,IPM控制了每分钟可以生成的图像数量,这是ChatGPT API速率限制在多模态应用中的重要组成部分。多模态应用需要特别关注这个ChatGPT API速率限制维度。
为什么OpenAI要设置速率限制?
理解ChatGPT API速率限制存在的原因,有助于我们更好地应对和优化:
1. 防止恶意攻击和滥用 没有ChatGPT API速率限制,恶意用户可能通过大量请求发起DDoS攻击,导致服务对所有用户不可用。速率限制是第一道防线,确保API的可用性和稳定性。
2. 确保公平的资源分配 GPU计算资源是有限的,ChatGPT API速率限制确保每个用户都能获得合理的资源份额,防止个别大用户垄断所有计算能力,影响其他用户的正常使用。
3. 维护基础设施稳定性 OpenAI的数据中心需要处理数百万并发请求,ChatGPT API速率限制帮助控制负载,防止系统过载,确保所有用户都能获得稳定、快速的响应。
4. 成本控制和商业可持续性 运行大规模语言模型的成本极高,ChatGPT API速率限制与定价策略配合,确保服务的商业可持续性,同时为不同规模的用户提供合适的服务层级。
速率限制的实际影响
让我们通过具体数据来理解ChatGPT API速率限制的实际影响:
| 使用场景 | 所需RPM | 所需TPM | 最低账户要求 |
|---|---|---|---|
| 个人助手应用 | 10-20 | 5,000 | 付费Tier 1 |
| 小型企业客服 | 50-100 | 20,000 | 付费Tier 2 |
| 内容生成平台 | 200-500 | 100,000 | 付费Tier 3 |
| 大规模SaaS应用 | 1000+ | 500,000+ | 付费Tier 4-5 |
从上表可以看出,不同规模的应用对ChatGPT API速率限制有着截然不同的需求。一个服务1000用户的聊天应用,如果每个用户平均每分钟发送0.5个请求,就需要至少500 RPM的限制,这已经超出了低层级账户的能力范围。
速率限制触发机制详解
ChatGPT API速率限制的触发遵循"先到先得"原则,无论哪个限制先达到,都会触发速率限制错误:
python# 示例:即使TPM充足,RPM限制也会触发
# 假设限制:20 RPM, 150,000 TPM
# 场景:连续发送20个各100 tokens的请求
for i in range(20):
api_call(tokens=100) # 总共只用了2,000 tokens
# 但已达到20 RPM限制,第21个请求将失败
这种机制意味着优化ChatGPT API速率限制需要同时考虑多个维度,不能只关注单一指标。
2025年最新OpenAI层级系统详解
OpenAI在2024年底全面改革了其ChatGPT API速率限制层级系统,引入了更加精细化的五级体系。这个系统根据用户的使用量和付费历史自动调整限制,为不同规模的应用提供合适的资源配额。详细的官方文档可以在OpenAI速率限制页面查阅。
完整的五级层级体系
ChatGPT API速率限制的层级系统设计巧妙,随着你的使用量和付费额增加,系统会自动将你的账户升级到更高层级:
| 层级 | 资格要求 | 月度限额 | GPT-4o限制 | GPT-3.5限制 | 升级时间 |
|---|---|---|---|---|---|
| Free | 新注册用户 | $0 | 不可用 | 3 RPM, 40K TPM | - |
| Tier 1 | 首次付费 | $500 | 500 RPM, 30K TPM | 3,500 RPM, 200K TPM | 立即 |
| Tier 2 | 付费≥$50 + 7天 | $5,000 | 5,000 RPM, 450K TPM | 5,000 RPM, 2M TPM | 7天 |
| Tier 3 | 付费≥$100 + 14天 | $25,000 | 5,000 RPM, 800K TPM | 10,000 RPM, 5M TPM | 14天 |
| Tier 4 | 付费≥$500 + 30天 | $150,000 | 10,000 RPM, 2M TPM | 10,000 RPM, 10M TPM | 30天 |
| Tier 5 | 付费≥$1,000 + 60天 | $200,000 | 10,000 RPM, 4M TPM | 15,000 RPM, 20M TPM | 60天 |
自动升级机制深度解析
ChatGPT API速率限制的层级升级是完全自动的,但需要满足两个条件:
1. 累计付费金额达标 这是指你的OpenAI账户历史总付费金额,不是月度消费。例如,要升级到Tier 3,你需要累计付费至少100美元。
2. 账户使用时长达标 从首次付费开始计算的天数。即使你第一天就充值1000美元,也需要等待60天才能升级到Tier 5。
这种双重门槛设计确保了ChatGPT API速率限制的升级既考虑了用户的支付能力,也验证了使用的持续性和合规性。
各层级详细特权对比
Tier 1 - 入门级付费用户 适合个人开发者和小型项目测试。虽然ChatGPT API速率限制相比免费账户有了质的提升,但对于生产环境应用仍显不足:
- 可以开始使用GPT-4系列模型
- 批处理API额度:每天150万tokens
- 支持Assistant API和Fine-tuning功能
- 月度最高消费限制在500美元
Tier 2 - 成长型应用 这是大多数初创公司和中小型应用的目标层级。ChatGPT API速率限制在这个级别已经能支持相当规模的用户群体:
- RPM提升10倍,达到5,000次/分钟
- TPM大幅提升,GPT-3.5达到200万tokens/分钟
- 批处理额度提升到每天300万tokens
- 月度限额5,000美元,足够支持数千活跃用户
Tier 3 - 规模化应用 进入Tier 3意味着你的应用已经具有相当的规模,ChatGPT API速率限制配置适合企业级应用:
- GPT-3.5模型TPM达到500万,可处理海量文本
- 支持更高并发,适合实时应用场景
- 月度25,000美元限额,支持大规模商业运营
- 获得优先技术支持资格
Tier 4 - 企业级应用 Tier 4的ChatGPT API速率限制专为大型企业和高流量SaaS平台设计:
- GPT-4o模型TPM达到200万,支持复杂推理任务
- 10,000 RPM支持极高并发
- 150,000美元月度限额,几乎无上限
- 可申请定制化限制调整
Tier 5 - 顶级合作伙伴 最高层级的ChatGPT API速率限制,享受OpenAI提供的最优资源:
- 所有模型的最高限制配额
- 20万美元月度限额
- 优先访问新模型和功能
- 专属技术支持团队
- 可协商定制化SLA
层级系统的隐藏优势
除了明面上的ChatGPT API速率限制提升,高层级账户还享有以下隐藏优势:
1. 请求优先级提升 在系统负载高峰期,高层级账户的请求会获得优先处理,延迟更低,成功率更高。
2. 新功能优先体验 OpenAI的新模型和功能通常会优先向Tier 3及以上用户开放,如GPT-4o最初仅对高层级用户可用。
3. 定制化支持 Tier 4和Tier 5用户可以直接联系OpenAI团队,获得定制化的ChatGPT API速率限制调整方案。
4. 故障补偿机制 高层级用户在遭遇服务故障时,可以获得使用额度补偿,确保业务连续性。
快速升级策略
如果你需要快速提升ChatGPT API速率限制层级,可以考虑以下策略:
策略一:预充值加速 直接充值到目标层级所需金额,然后通过增加使用量来消耗额度,同时等待时间要求满足。
策略二:多账户并行 对于急需高限制的项目,可以考虑注册多个账户并行使用,通过负载均衡分配请求。但需注意,这种方式需要额外的技术复杂度和成本。
策略三:选择合适的起点 如果预期会快速增长,建议一开始就充值100美元以上,这样14天后就能达到Tier 3,避免在Tier 1和Tier 2浪费时间。
对于需要更灵活的ChatGPT API速率限制管理方案的用户,laozhang.ai提供了多模型聚合API服务,可以同时调用OpenAI、Anthropic、Google等多家供应商的模型,有效规避单一平台的速率限制,实现真正的高可用架构。平台采用智能路由技术,自动在多个模型间负载均衡,即使某个模型达到速率限制,也能无缝切换到其他可用模型,确保服务不中断。更多关于AI Agent开发的内容,可以参考OpenAI Agent Builder完整指南。
不同模型的速率限制对比分析
理解不同模型的ChatGPT API速率限制差异是优化API使用的关键。每个模型都有其独特的限制配置,选择合适的模型不仅影响应用性能,还直接关系到成本控制。
2025年主流模型速率限制对比
以下是OpenAI各主流模型在不同账户层级下的ChatGPT API速率限制详细对比:
| 模型 | 免费账户 | Tier 1 | Tier 2 | Tier 3 | Tier 5 |
|---|---|---|---|---|---|
| GPT-4o | 不可用 | 500 RPM 30K TPM | 5,000 RPM 450K TPM | 5,000 RPM 800K TPM | 10,000 RPM 4M TPM |
| GPT-4o-mini | 不可用 | 500 RPM 200K TPM | 5,000 RPM 2M TPM | 5,000 RPM 4M TPM | 30,000 RPM 150M TPM |
| GPT-4-turbo | 不可用 | 500 RPM 30K TPM | 5,000 RPM 450K TPM | 5,000 RPM 600K TPM | 10,000 RPM 2M TPM |
| GPT-3.5-turbo | 3 RPM 40K TPM | 3,500 RPM 200K TPM | 5,000 RPM 2M TPM | 10,000 RPM 5M TPM | 15,000 RPM 20M TPM |
| Text-embedding-3 | 3 RPM 150K TPM | 5,000 RPM 5M TPM | 5,000 RPM 10M TPM | 10,000 RPM 20M TPM | 15,000 RPM 50M TPM |
GPT-4o:旗舰模型的速率特性
GPT-4o是OpenAI在2024年5月发布的最新旗舰模型,其ChatGPT API速率限制相比前代有了革命性提升。更多关于GPT-4o的详细信息,可参考ChatGPT 4.5完整指南。
关键优势:
- 速度提升5倍:相比GPT-4-turbo,处理速度快5倍
- 成本降低50%:输入$5/百万tokens,输出$15/百万tokens
- 多模态能力:支持文本、图像、音频输入
- 实时响应:延迟降低到232-320毫秒
使用建议: 对于需要最高质量输出的场景,GPT-4o是首选,但要注意其ChatGPT API速率限制在低层级账户中较为严格。建议将其用于:
- 复杂推理任务
- 多语言翻译
- 代码生成和调试
- 创意写作
GPT-3.5-turbo:性价比之王
尽管已不是最新模型,GPT-3.5-turbo仍然是许多应用的主力,主要得益于其宽松的ChatGPT API速率限制:
核心特点:
- 极高的RPM限制:Tier 5可达15,000 RPM
- 超大TPM配额:最高20M TPM,适合批量处理
- 低成本:$0.5/百万输入tokens,$1.5/百万输出tokens
- 稳定性好:经过长期优化,错误率最低
适用场景:
- 高并发聊天应用
- 批量内容处理
- 成本敏感型项目
- 对响应质量要求不极致的场景
免费账户限制变化历程
ChatGPT API速率限制对免费用户的调整反映了OpenAI的策略变化:
2023年初期:
- 30 RPM,相对宽松
- 支持GPT-3.5所有功能
- 每月18美元免费额度
2024年中期:
- 降至20 RPM
- 取消免费额度
- 限制部分高级功能
2025年现状:
- 仅3 RPM,40K TPM
- 仅支持GPT-3.5-turbo
- 主要用于测试和评估
这种变化迫使严肃的开发者转向付费账户,同时也催生了对ChatGPT API速率限制优化技术的需求。
特殊模型的速率考虑
DALL-E 3图像生成:
- 标准限制:50-400 IPM(根据层级)
- 生成时间:15-30秒/图
- 建议:使用异步队列处理
Whisper语音识别:
- 文件大小限制:25MB
- 并发限制:50个并发请求
- 处理速度:实时速度的5-10倍
Text-embedding嵌入模型:
- 超高TPM:最高50M TPM
- 批处理优化:支持2048个文本同时嵌入
- 成本极低:$0.02/百万tokens
模型选择决策树
根据ChatGPT API速率限制和应用需求选择合适的模型:
应用类型判断
├── 需要最高质量?
│ ├── 是 → GPT-4o
│ └── 否 → 继续判断
├── 高并发要求(>1000 RPM)?
│ ├── 是 → GPT-3.5-turbo
│ └── 否 → 继续判断
├── 成本敏感?
│ ├── 是 → GPT-4o-mini 或 GPT-3.5-turbo
│ └── 否 → GPT-4o
└── 需要实时响应?
├── 是 → GPT-4o-mini
└── 否 → 根据质量需求选择
速率限制错误处理与最佳实践
遇到ChatGPT API速率限制错误是不可避免的,关键在于如何优雅地处理这些错误,确保应用的稳定性和用户体验。本章将详细介绍错误处理机制和经过实战验证的最佳实践。

429错误深度解析
当触发ChatGPT API速率限制时,API会返回HTTP 429状态码,伴随详细的错误信息。关于API错误的完整处理方案,可以参考API配额超限错误解决指南。
⚠️ 429错误示例:
{ "error": { "message": "Rate limit reached for gpt-4o in organization org-xxx on requests per min (RPM): Limit 500, Used 501, Requested 1.", "type": "rate_limit_error", "param": null, "code": "rate_limit_exceeded", "retry_after": 12 } }
错误信息解读:
Limit:当前层级的限制值Used:已使用的配额Requested:本次请求需要的配额retry_after:建议的重试等待时间(秒)
指数退避算法实现
指数退避是处理ChatGPT API速率限制最有效的策略之一。通过智能的退避算法,可以大幅减少因ChatGPT API速率限制导致的失败请求。以下是生产级Python实现:
pythonimport time
import random
import openai
from typing import Optional, Dict, Any
from functools import wraps
def exponential_backoff_retry(
max_retries: int = 6,
base_delay: float = 1.0,
max_delay: float = 60.0,
exponential_base: float = 2.0,
jitter: bool = True
):
"""
装饰器:为函数添加指数退避重试机制
处理ChatGPT API速率限制错误
"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
retries = 0
while retries < max_retries:
try:
return func(*args, **kwargs)
except openai.RateLimitError as e:
retries += 1
if retries >= max_retries:
raise e
# 计算延迟时间
delay = min(base_delay * (exponential_base ** (retries - 1)), max_delay)
# 添加随机抖动避免请求同步
if jitter:
delay = delay * (0.5 + random.random())
# 如果API返回了retry_after,优先使用
if hasattr(e, 'retry_after'):
delay = max(delay, e.retry_after)
print(f"速率限制触发,等待 {delay:.2f} 秒后重试 (第{retries}/{max_retries}次)")
time.sleep(delay)
raise Exception(f"达到最大重试次数 {max_retries}")
return wrapper
return decorator
# 使用示例
@exponential_backoff_retry(max_retries=5)
def call_chatgpt_api(prompt: str, model: str = "gpt-3.5-turbo"):
"""封装的API调用函数,自动处理速率限制"""
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.7
)
return response.choices[0].message.content
请求队列管理策略
对于高并发应用,简单的重试机制不够,需要实现智能的请求队列来管理ChatGPT API速率限制。请求队列是应对ChatGPT API速率限制的高级技术,能够主动预防限制触发:
pythonimport asyncio
from collections import deque
from datetime import datetime, timedelta
class RateLimitedQueue:
"""
智能请求队列,自动管理ChatGPT API速率限制
"""
def __init__(self, rpm_limit: int, tpm_limit: int):
self.rpm_limit = rpm_limit
self.tpm_limit = tpm_limit
self.request_times = deque()
self.token_usage = deque()
self.lock = asyncio.Lock()
async def acquire(self, estimated_tokens: int):
"""
获取执行权限,确保不超过速率限制
"""
async with self.lock:
now = datetime.now()
# 清理过期记录(超过1分钟)
self._clean_old_records(now)
# 检查RPM限制
while len(self.request_times) >= self.rpm_limit:
wait_time = 60 - (now - self.request_times[0]).total_seconds()
if wait_time > 0:
await asyncio.sleep(wait_time)
now = datetime.now()
self._clean_old_records(now)
# 检查TPM限制
current_tokens = sum(t for _, t in self.token_usage)
while current_tokens + estimated_tokens > self.tpm_limit:
wait_time = 60 - (now - self.token_usage[0][0]).total_seconds()
if wait_time > 0:
await asyncio.sleep(wait_time)
now = datetime.now()
self._clean_old_records(now)
current_tokens = sum(t for _, t in self.token_usage)
# 记录本次请求
self.request_times.append(now)
self.token_usage.append((now, estimated_tokens))
def _clean_old_records(self, now):
"""清理超过1分钟的记录"""
cutoff = now - timedelta(minutes=1)
while self.request_times and self.request_times[0] < cutoff:
self.request_times.popleft()
while self.token_usage and self.token_usage[0][0] < cutoff:
self.token_usage.popleft()
# 使用示例
rate_limiter = RateLimitedQueue(rpm_limit=500, tpm_limit=30000)
async def safe_api_call(prompt: str):
# 估算token数量(粗略计算)
estimated_tokens = len(prompt) // 4 + 500 # 假设响应约500 tokens
# 等待获取执行权限
await rate_limiter.acquire(estimated_tokens)
# 执行API调用
return await call_chatgpt_api_async(prompt)
批处理优化技术
当RPM是瓶颈而TPM充足时,批处理可以显著提升ChatGPT API速率限制下的吞吐量。批处理是优化ChatGPT API速率限制使用效率的重要手段,特别适合处理大量小请求的场景:
pythonclass BatchProcessor:
"""
批处理器:优化ChatGPT API速率限制使用
"""
def __init__(self, batch_size: int = 10, max_wait: float = 2.0):
self.batch_size = batch_size
self.max_wait = max_wait
self.pending = []
self.results = {}
self.lock = asyncio.Lock()
async def process(self, item_id: str, prompt: str):
"""添加请求到批处理队列"""
async with self.lock:
self.pending.append((item_id, prompt))
# 如果达到批次大小,立即处理
if len(self.pending) >= self.batch_size:
await self._process_batch()
else:
# 否则等待更多请求或超时
asyncio.create_task(self._wait_and_process())
# 等待结果
while item_id not in self.results:
await asyncio.sleep(0.1)
return self.results.pop(item_id)
async def _process_batch(self):
"""处理一批请求"""
if not self.pending:
return
batch = self.pending[:self.batch_size]
self.pending = self.pending[self.batch_size:]
# 合并prompts
combined_prompt = "\n---\n".join([
f"Request {i+1}: {prompt}"
for i, (_, prompt) in enumerate(batch)
])
# 单次API调用处理多个请求
response = await call_chatgpt_api_async(
f"请分别回答以下{len(batch)}个问题,用---分隔答案:\n{combined_prompt}"
)
# 解析响应并存储结果
answers = response.split("---")
for (item_id, _), answer in zip(batch, answers):
self.results[item_id] = answer.strip()
监控和告警机制
实时监控ChatGPT API速率限制使用情况对于预防问题至关重要:
pythonimport logging
from datetime import datetime
from collections import defaultdict
class RateLimitMonitor:
"""
监控ChatGPT API速率限制使用情况
"""
def __init__(self, alert_threshold: float = 0.8):
self.alert_threshold = alert_threshold
self.usage_stats = defaultdict(lambda: {"rpm": 0, "tpm": 0, "errors": 0})
self.logger = logging.getLogger(__name__)
def record_request(self, model: str, tokens: int, success: bool):
"""记录API请求"""
stats = self.usage_stats[model]
stats["rpm"] += 1
stats["tpm"] += tokens
if not success:
stats["errors"] += 1
# 检查是否需要告警
self._check_alerts(model, stats)
def _check_alerts(self, model: str, stats: dict):
"""检查并发送告警"""
# 这里假设已知各模型的限制
limits = {
"gpt-4o": {"rpm": 500, "tpm": 30000},
"gpt-3.5-turbo": {"rpm": 3500, "tpm": 200000}
}
if model in limits:
limit = limits[model]
rpm_usage = stats["rpm"] / limit["rpm"]
tpm_usage = stats["tpm"] / limit["tpm"]
if rpm_usage > self.alert_threshold:
self.logger.warning(
f"⚠️ {model} RPM使用率达到 {rpm_usage*100:.1f}% "
f"({stats['rpm']}/{limit['rpm']})"
)
if tpm_usage > self.alert_threshold:
self.logger.warning(
f"⚠️ {model} TPM使用率达到 {tpm_usage*100:.1f}% "
f"({stats['tpm']}/{limit['tpm']})"
)
if stats["errors"] > 10:
self.logger.error(
f"❌ {model} 错误率过高:{stats['errors']}个错误"
)
生产环境最佳实践清单
基于大量实践经验,以下是管理ChatGPT API速率限制的最佳实践:
✅ 核心最佳实践:
- 始终实现重试机制:使用指数退避,设置合理的最大重试次数
- 提前监控使用量:在达到限制前80%时开始限流
- 使用队列管理请求:避免突发流量触发限制
- 实现优雅降级:当API不可用时,提供备选方案
- 错误分类处理:区分速率限制、服务错误和其他错误
- 记录详细日志:便于问题排查和容量规划
- 设置成本预算:防止意外高额账单
- 定期审查使用模式:优化请求分布,避免峰值
如何提升API速率限制
当你的应用增长超出当前ChatGPT API速率限制时,提升限制成为必然需求。本章将详细介绍申请提升限制的流程、准备材料和成功策略。
申请提升限制的前提条件
在申请提升ChatGPT API速率限制之前,OpenAI要求满足以下基本条件:
📋 申请前提条件:
1. 账户状态要求
- 必须是付费账户(至少Tier 1)
- 账户无违规记录
- 过去30天无异常使用行为
- 信用卡验证通过
2. 使用历史要求
- 至少10个工作日的稳定使用数据
- 当前限制使用率达到80%以上
- 有明确的增长趋势证明
3. 合规性要求
- 应用符合OpenAI使用条款
- 不涉及禁止的使用场景
- 有完善的内容审核机制
准备申请材料
成功的ChatGPT API速率限制提升申请需要充分的数据支撑:
必需材料清单:
markdown## 1. 使用数据报告(最近30天)
- 日均API调用次数
- 峰值使用时段分析
- Token消耗分布图
- 错误率统计(特别是429错误)
## 2. 业务增长预测
- 未来3个月的用户增长预期
- API调用量增长曲线
- 新功能对API的需求预估
- 季节性波动分析
## 3. 技术架构说明
- 当前的限流策略
- 队列管理机制
- 错误处理方案
- 负载均衡设计
## 4. 商业案例说明
- 应用的核心价值
- 目标用户群体
- 收入模型(如适用)
- 限制提升的ROI分析
填写申请表格的技巧
OpenAI的ChatGPT API速率限制提升申请表格需要精心填写:
关键字段填写指南:
1. Current Usage(当前使用情况)
示例回答:
"我们的教育AI助手目前服务5000日活用户,日均处理
15,000个请求,峰值RPM达到450(当前限制500)。
过去两周有3次因达到限制导致服务降级。"
2. Requested Limits(申请限制)
示例回答:
"申请将GPT-4o限制从500 RPM提升至2000 RPM,
TPM从30K提升至150K。基于当前增长率(周增15%),
预计4周后将突破现有限制。"
3. Use Case Description(用例描述)
示例回答:
"我们的平台为大学生提供24/7学习辅导,包括:
- 实时答疑(占60%请求)
- 论文写作指导(占25%请求)
- 代码调试帮助(占15%请求)
每个功能都有严格的内容审核和速率控制。"
4. Mitigation Plan(缓解计划)
示例回答:
"我们已实施:
- 用户级限流(每用户10 RPM)
- 智能请求队列(削峰填谷)
- 缓存机制(相似问题复用)
- 多模型降级策略(高峰时切换到GPT-3.5)"
提升申请的成功策略
根据社区经验,以下策略可以提高ChatGPT API速率限制申请成功率:
策略1:渐进式申请 不要一次申请过高的限制提升。建议每次申请提升2-3倍,成功率更高:
- 第一次:500 → 1,500 RPM
- 第二次:1,500 → 5,000 RPM
- 第三次:5,000 → 10,000 RPM
策略2:数据驱动 用图表展示你的使用模式,特别是:
- 每日请求量趋势图
- 429错误发生频率
- 用户等待时间分析
- 业务损失评估
策略3:展示优化努力 强调你已经做的优化工作:
- 实施了缓存减少30%重复请求
- 批处理提升了40% Token效率
- 智能路由降低了峰值负载
策略4:强调商业价值 如果你的应用有商业模式,突出:
- 付费用户数量和增长
- 每月在OpenAI的消费金额
- 长期合作意向
审批流程和时间线
ChatGPT API速率限制提升申请的审批流程:
mermaidgraph LR A[提交申请] --> B[初步审核<br/>1-2天] B --> C{是否需要补充材料} C -->|是| D[补充材料<br/>2-3天] C -->|否| E[技术评估<br/>3-5天] D --> E E --> F{批准决定} F -->|批准| G[限制更新<br/>立即生效] F -->|拒绝| H[收到反馈<br/>可30天后重申]
典型时间线:
- 简单提升(2倍以内):3-5个工作日
- 中等提升(2-5倍):5-7个工作日
- 大幅提升(5倍以上):7-10个工作日
- 企业定制:需要商务洽谈,15-30天
被拒绝后的应对策略
如果ChatGPT API速率限制提升申请被拒绝:
常见拒绝原因和应对:
| 拒绝原因 | 应对策略 |
|---|---|
| 使用数据不足 | 继续收集10-30天数据后重新申请 |
| 当前限制未充分利用 | 优化代码,提高使用率到80%以上 |
| 增长预测不合理 | 提供更详细的业务计划和用户数据 |
| 技术方案不完善 | 改进错误处理和限流机制 |
| 用例描述不清 | 提供更具体的使用场景和价值说明 |
改进建议:
- 实施更严格的用户级限流
- 增加请求缓存和批处理
- 提供详细的监控报告
- 考虑升级到更高账户层级
- 寻求OpenAI技术支持指导
对于需要更高灵活性的团队,可以考虑使用laozhang.ai的API聚合服务作为补充方案。平台提供统一的API接口,可同时调用多个AI供应商的服务,当OpenAI达到ChatGPT API速率限制时自动切换到Claude或Google的模型,确保服务的连续性。这种多供应商策略不仅提高了系统可靠性,还能在不同模型间实现成本优化。对于中国用户,推荐查看中国最佳API中转服务指南了解更多本地化解决方案。
企业级解决方案与优化策略
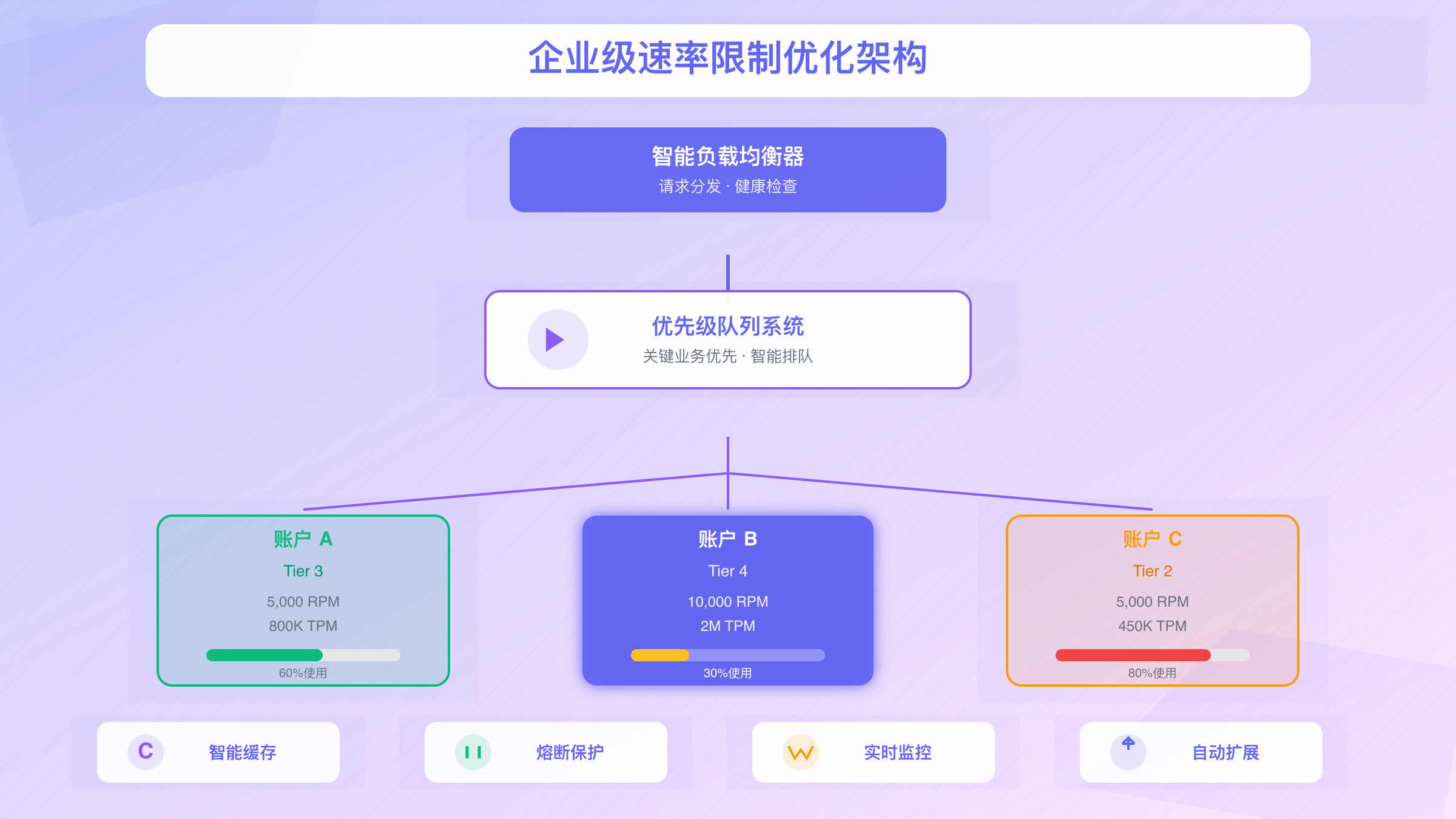
当应用规模达到企业级别时,简单的ChatGPT API速率限制管理已经不够,需要系统性的架构设计和优化策略。本章将分享经过验证的企业级解决方案。
多账户负载均衡架构
对于大规模应用,单一账户的ChatGPT API速率限制往往不够,多账户架构成为必然选择。多账户架构是突破ChatGPT API速率限制的企业级解决方案,能够成倍提升系统处理能力:
pythonimport random
from typing import List, Dict, Optional
from dataclasses import dataclass
from datetime import datetime, timedelta
@dataclass
class APIAccount:
"""API账户配置"""
api_key: str
tier: int
rpm_limit: int
tpm_limit: int
current_rpm: int = 0
current_tpm: int = 0
last_reset: datetime = None
is_available: bool = True
class MultiAccountManager:
"""
多账户管理器:智能分配请求到不同账户
突破单账户ChatGPT API速率限制
"""
def __init__(self, accounts: List[Dict]):
self.accounts = []
for acc in accounts:
self.accounts.append(APIAccount(**acc))
self.last_check = datetime.now()
def get_available_account(self, required_tokens: int) -> Optional[APIAccount]:
"""
获取可用账户,实现负载均衡
"""
# 重置计数器(每分钟)
self._reset_counters_if_needed()
# 筛选可用账户
available = [
acc for acc in self.accounts
if acc.is_available
and acc.current_rpm < acc.rpm_limit * 0.9 # 留10%缓冲
and acc.current_tpm + required_tokens < acc.tpm_limit * 0.9
]
if not available:
return None
# 选择负载最低的账户
selected = min(available, key=lambda x: x.current_rpm / x.rpm_limit)
# 更新使用计数
selected.current_rpm += 1
selected.current_tpm += required_tokens
return selected
def _reset_counters_if_needed(self):
"""每分钟重置计数器"""
now = datetime.now()
if (now - self.last_check).seconds >= 60:
for acc in self.accounts:
acc.current_rpm = 0
acc.current_tpm = 0
self.last_check = now
def mark_account_limited(self, account: APIAccount):
"""标记账户达到限制"""
account.is_available = False
# 1分钟后自动恢复
threading.Timer(60, lambda: setattr(account, 'is_available', True)).start()
# 使用示例
accounts_config = [
{"api_key": "sk-xxx1", "tier": 2, "rpm_limit": 5000, "tpm_limit": 450000},
{"api_key": "sk-xxx2", "tier": 2, "rpm_limit": 5000, "tpm_limit": 450000},
{"api_key": "sk-xxx3", "tier": 3, "rpm_limit": 5000, "tpm_limit": 800000},
]
manager = MultiAccountManager(accounts_config)
async def balanced_api_call(prompt: str):
"""负载均衡的API调用"""
estimated_tokens = len(prompt) // 4 + 500
account = manager.get_available_account(estimated_tokens)
if not account:
raise Exception("所有账户都已达到速率限制")
try:
openai.api_key = account.api_key
response = await openai.ChatCompletion.acreate(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
return response
except openai.RateLimitError:
manager.mark_account_limited(account)
raise
智能缓存策略
缓存是降低ChatGPT API速率限制压力的有效手段。通过智能缓存,可以显著减少对ChatGPT API速率限制配额的消耗,提升整体响应速度:
pythonimport hashlib
import json
import redis
from typing import Optional, Any
class IntelligentCache:
"""
智能缓存系统:减少重复请求,优化速率限制使用
"""
def __init__(self, redis_client: redis.Redis, ttl: int = 3600):
self.redis = redis_client
self.ttl = ttl
self.stats = {"hits": 0, "misses": 0}
def _generate_key(self, prompt: str, model: str, temperature: float) -> str:
"""生成缓存键"""
# 标准化prompt(去除多余空白)
normalized = " ".join(prompt.split())
# 创建唯一标识
content = f"{model}:{temperature}:{normalized}"
return f"chatgpt:cache:{hashlib.md5(content.encode()).hexdigest()}"
def get(self, prompt: str, model: str, temperature: float) -> Optional[str]:
"""获取缓存结果"""
# 温度>0.5的请求不缓存(需要创造性)
if temperature > 0.5:
return None
key = self._generate_key(prompt, model, temperature)
result = self.redis.get(key)
if result:
self.stats["hits"] += 1
return json.loads(result)
else:
self.stats["misses"] += 1
return None
def set(self, prompt: str, model: str, temperature: float, response: str):
"""设置缓存"""
if temperature > 0.5:
return
key = self._generate_key(prompt, model, temperature)
self.redis.setex(
key,
self.ttl,
json.dumps(response)
)
def get_similar(self, prompt: str, threshold: float = 0.9) -> Optional[str]:
"""
模糊匹配:查找相似请求的缓存
使用向量数据库实现语义搜索
"""
# 这里简化处理,实际应使用向量数据库
# 如Pinecone、Weaviate或Redis的向量搜索功能
pass
def get_stats(self) -> Dict:
"""获取缓存统计"""
total = self.stats["hits"] + self.stats["misses"]
hit_rate = self.stats["hits"] / total if total > 0 else 0
return {
"hit_rate": f"{hit_rate*100:.2f}%",
"total_saves": self.stats["hits"],
"api_calls_saved": self.stats["hits"],
"estimated_cost_saved": self.stats["hits"] * 0.002 # 假设每次调用$0.002
}
# 集成到API调用
cache = IntelligentCache(redis.Redis(host='localhost'))
async def cached_api_call(prompt: str, model: str = "gpt-3.5-turbo", temperature: float = 0):
"""带缓存的API调用"""
# 尝试从缓存获取
cached_response = cache.get(prompt, model, temperature)
if cached_response:
return {"content": cached_response, "cached": True}
# 缓存未命中,调用API
response = await call_chatgpt_api(prompt, model, temperature)
# 存入缓存
cache.set(prompt, model, temperature, response)
return {"content": response, "cached": False}
请求优先级队列
企业应用需要区分请求优先级,确保关键业务不受ChatGPT API速率限制影响。优先级队列是在ChatGPT API速率限制约束下,保障核心业务的关键机制:
pythonimport heapq
from enum import Enum
from dataclasses import dataclass, field
from typing import Any
class Priority(Enum):
"""请求优先级"""
CRITICAL = 1 # 关键业务
HIGH = 2 # 高优先级
NORMAL = 3 # 普通请求
LOW = 4 # 低优先级
BATCH = 5 # 批处理
@dataclass(order=True)
class PrioritizedRequest:
priority: int
timestamp: float = field(compare=False)
request_id: str = field(compare=False)
prompt: str = field(compare=False)
callback: Any = field(compare=False)
retry_count: int = field(default=0, compare=False)
class PriorityQueueManager:
"""
优先级队列管理器:确保重要请求优先处理
"""
def __init__(self, max_concurrent: int = 10):
self.queue = []
self.processing = set()
self.max_concurrent = max_concurrent
self.lock = asyncio.Lock()
async def submit(self,
prompt: str,
priority: Priority = Priority.NORMAL,
callback: Optional[Callable] = None) -> str:
"""提交请求到优先级队列"""
request = PrioritizedRequest(
priority=priority.value,
timestamp=time.time(),
request_id=str(uuid.uuid4()),
prompt=prompt,
callback=callback
)
async with self.lock:
heapq.heappush(self.queue, request)
# 触发处理
asyncio.create_task(self._process_queue())
return request.request_id
async def _process_queue(self):
"""处理队列中的请求"""
async with self.lock:
# 检查并发限制
if len(self.processing) >= self.max_concurrent:
return
# 获取最高优先级请求
if not self.queue:
return
request = heapq.heappop(self.queue)
self.processing.add(request.request_id)
try:
# 执行API调用
result = await self._execute_request(request)
# 执行回调
if request.callback:
await request.callback(result)
except Exception as e:
# 处理失败,根据优先级决定是否重试
if request.priority <= Priority.HIGH.value and request.retry_count < 3:
request.retry_count += 1
async with self.lock:
heapq.heappush(self.queue, request)
else:
# 记录错误
logging.error(f"Request {request.request_id} failed: {e}")
finally:
self.processing.discard(request.request_id)
# 继续处理下一个
asyncio.create_task(self._process_queue())
async def _execute_request(self, request: PrioritizedRequest):
"""执行单个请求"""
# 根据优先级选择不同的处理策略
if request.priority == Priority.CRITICAL.value:
# 关键请求:使用最好的模型和账户
return await call_chatgpt_api(request.prompt, model="gpt-4o")
elif request.priority == Priority.BATCH.value:
# 批处理:可以等待并合并
await asyncio.sleep(random.uniform(1, 5))
return await call_chatgpt_api(request.prompt, model="gpt-3.5-turbo")
else:
# 普通请求:标准处理
return await call_chatgpt_api(request.prompt)
# 使用示例
queue_manager = PriorityQueueManager(max_concurrent=10)
# 提交不同优先级的请求
await queue_manager.submit("紧急:系统故障诊断", Priority.CRITICAL)
await queue_manager.submit("生成月度报告", Priority.HIGH)
await queue_manager.submit("回答用户问题", Priority.NORMAL)
await queue_manager.submit("批量数据处理", Priority.BATCH)
降级和熔断机制
当ChatGPT API速率限制压力过大时,需要智能降级策略。熔断和降级是应对ChatGPT API速率限制的最后防线,确保系统在极端情况下仍能提供服务:
pythonclass CircuitBreaker:
"""
熔断器:防止ChatGPT API速率限制导致的雪崩效应
"""
def __init__(self,
failure_threshold: int = 5,
recovery_timeout: int = 60,
expected_exception: type = openai.RateLimitError):
self.failure_threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.expected_exception = expected_exception
self.failure_count = 0
self.last_failure_time = None
self.state = "CLOSED" # CLOSED, OPEN, HALF_OPEN
async def call(self, func, *args, **kwargs):
"""通过熔断器调用函数"""
if self.state == "OPEN":
if self._should_attempt_reset():
self.state = "HALF_OPEN"
else:
raise Exception("Circuit breaker is OPEN")
try:
result = await func(*args, **kwargs)
self._on_success()
return result
except self.expected_exception as e:
self._on_failure()
raise
def _should_attempt_reset(self) -> bool:
"""检查是否应该尝试恢复"""
return (
self.last_failure_time and
time.time() - self.last_failure_time >= self.recovery_timeout
)
def _on_success(self):
"""成功调用后重置"""
self.failure_count = 0
self.state = "CLOSED"
def _on_failure(self):
"""失败调用后更新状态"""
self.failure_count += 1
self.last_failure_time = time.time()
if self.failure_count >= self.failure_threshold:
self.state = "OPEN"
logging.warning(f"Circuit breaker opened after {self.failure_count} failures")
# 降级策略
class DegradationStrategy:
"""
降级策略:当主服务不可用时的备选方案
"""
def __init__(self):
self.strategies = []
def add_strategy(self, condition, action):
"""添加降级策略"""
self.strategies.append((condition, action))
async def execute(self, prompt: str, context: Dict) -> str:
"""执行降级策略"""
for condition, action in self.strategies:
if condition(context):
return await action(prompt, context)
# 所有策略都不适用,返回默认响应
return "系统繁忙,请稍后再试"
# 配置降级策略
degradation = DegradationStrategy()
# 策略1:切换到更便宜的模型
degradation.add_strategy(
condition=lambda ctx: ctx.get("error_type") == "rate_limit" and ctx.get("model") == "gpt-4o",
action=lambda p, ctx: call_chatgpt_api(p, model="gpt-3.5-turbo")
)
# 策略2:使用缓存的类似回答
degradation.add_strategy(
condition=lambda ctx: ctx.get("error_type") == "rate_limit",
action=lambda p, ctx: cache.get_similar(p, threshold=0.8)
)
# 策略3:使用本地小模型
degradation.add_strategy(
condition=lambda ctx: ctx.get("consecutive_failures") > 3,
action=lambda p, ctx: local_llm_fallback(p)
)
性能监控Dashboard
实时监控ChatGPT API速率限制使用情况对企业应用至关重要。完善的监控系统是管理ChatGPT API速率限制的基础设施,能够及时发现和预防问题:
pythonfrom prometheus_client import Counter, Gauge, Histogram, start_http_server
import time
# Prometheus指标定义
request_count = Counter('chatgpt_requests_total', 'Total API requests', ['model', 'status'])
request_duration = Histogram('chatgpt_request_duration_seconds', 'Request duration', ['model'])
rate_limit_gauge = Gauge('chatgpt_rate_limit_usage', 'Rate limit usage percentage', ['model', 'limit_type'])
token_usage = Counter('chatgpt_tokens_total', 'Total tokens used', ['model', 'type'])
cost_counter = Counter('chatgpt_cost_dollars', 'API cost in dollars', ['model'])
class MetricsCollector:
"""
指标收集器:监控ChatGPT API速率限制和使用情况
"""
def __init__(self):
# 启动Prometheus HTTP服务器
start_http_server(8000)
self.current_usage = {}
def record_request(self, model: str, duration: float, success: bool, tokens_used: dict):
"""记录API请求指标"""
# 请求计数
status = 'success' if success else 'failure'
request_count.labels(model=model, status=status).inc()
# 请求时长
request_duration.labels(model=model).observe(duration)
# Token使用
token_usage.labels(model=model, type='prompt').inc(tokens_used.get('prompt_tokens', 0))
token_usage.labels(model=model, type='completion').inc(tokens_used.get('completion_tokens', 0))
# 成本计算
cost = self._calculate_cost(model, tokens_used)
cost_counter.labels(model=model).inc(cost)
def update_rate_limit_usage(self, model: str, rpm_used: int, rpm_limit: int,
tpm_used: int, tpm_limit: int):
"""更新速率限制使用率"""
rpm_percentage = (rpm_used / rpm_limit) * 100 if rpm_limit > 0 else 0
tpm_percentage = (tpm_used / tpm_limit) * 100 if tpm_limit > 0 else 0
rate_limit_gauge.labels(model=model, limit_type='rpm').set(rpm_percentage)
rate_limit_gauge.labels(model=model, limit_type='tpm').set(tpm_percentage)
def _calculate_cost(self, model: str, tokens: dict) -> float:
"""计算API调用成本"""
pricing = {
"gpt-4o": {"input": 0.005, "output": 0.015}, # per 1K tokens
"gpt-3.5-turbo": {"input": 0.0005, "output": 0.0015},
"gpt-4o-mini": {"input": 0.00015, "output": 0.0006}
}
if model not in pricing:
return 0
input_cost = (tokens.get('prompt_tokens', 0) / 1000) * pricing[model]["input"]
output_cost = (tokens.get('completion_tokens', 0) / 1000) * pricing[model]["output"]
return input_cost + output_cost
# 集成到API调用
metrics = MetricsCollector()
async def monitored_api_call(prompt: str, model: str = "gpt-3.5-turbo"):
"""带监控的API调用"""
start_time = time.time()
success = False
tokens_used = {}
try:
response = await call_chatgpt_api(prompt, model)
success = True
tokens_used = response.get('usage', {})
return response
finally:
duration = time.time() - start_time
metrics.record_request(model, duration, success, tokens_used)
成本控制与监控方案
有效的成本控制是管理ChatGPT API速率限制的重要组成部分。本章将介绍如何建立完善的成本监控体系,避免意外的高额账单。
API使用成本计算模型
理解ChatGPT API速率限制下的成本结构是控制开支的第一步。最新的定价信息可以在OpenAI官方定价页面查看。
| 模型 | 输入价格($/1K tokens) | 输出价格($/1K tokens) | 平均请求成本 |
|---|---|---|---|
| GPT-4o | $0.005 | $0.015 | ~$0.02 |
| GPT-4o-mini | $0.00015 | $0.0006 | ~$0.001 |
| GPT-4-turbo | $0.01 | $0.03 | ~$0.04 |
| GPT-3.5-turbo | $0.0005 | $0.0015 | ~$0.002 |
成本计算公式:
总成本 = (输入tokens/1000 × 输入价格) + (输出tokens/1000 × 输出价格)
实时成本监控系统
建立实时监控系统,追踪ChatGPT API速率限制下的花费:
pythonimport datetime
from decimal import Decimal
from collections import defaultdict
class CostMonitor:
"""
成本监控器:实时跟踪ChatGPT API使用成本
"""
def __init__(self, daily_budget: float, monthly_budget: float):
self.daily_budget = Decimal(str(daily_budget))
self.monthly_budget = Decimal(str(monthly_budget))
self.daily_costs = defaultdict(Decimal)
self.monthly_cost = Decimal('0')
self.alerts_sent = set()
def track_cost(self, model: str, input_tokens: int, output_tokens: int):
"""追踪单次API调用成本"""
# 价格表(美元/1K tokens)
pricing = {
"gpt-4o": {"input": Decimal('0.005'), "output": Decimal('0.015')},
"gpt-4o-mini": {"input": Decimal('0.00015'), "output": Decimal('0.0006')},
"gpt-3.5-turbo": {"input": Decimal('0.0005'), "output": Decimal('0.0015')}
}
if model not in pricing:
return
# 计算成本
cost = (Decimal(input_tokens) / 1000 * pricing[model]["input"] +
Decimal(output_tokens) / 1000 * pricing[model]["output"])
# 更新统计
today = datetime.date.today()
self.daily_costs[today] += cost
self.monthly_cost += cost
# 检查预算
self._check_budget_alerts(today)
return float(cost)
def _check_budget_alerts(self, today):
"""检查并发送预算告警"""
daily_usage = self.daily_costs[today]
daily_percentage = (daily_usage / self.daily_budget) * 100
# 日预算告警
if daily_percentage >= 80 and f"daily_80_{today}" not in self.alerts_sent:
self._send_alert(f"⚠️ 日预算使用已达 {daily_percentage:.1f}%")
self.alerts_sent.add(f"daily_80_{today}")
if daily_percentage >= 100 and f"daily_100_{today}" not in self.alerts_sent:
self._send_alert(f"🚨 日预算已超支!当前: ${daily_usage:.2f}")
self.alerts_sent.add(f"daily_100_{today}")
# 月预算告警
monthly_percentage = (self.monthly_cost / self.monthly_budget) * 100
if monthly_percentage >= 70 and "monthly_70" not in self.alerts_sent:
self._send_alert(f"⚠️ 月预算使用已达 {monthly_percentage:.1f}%")
self.alerts_sent.add("monthly_70")
if monthly_percentage >= 90 and "monthly_90" not in self.alerts_sent:
self._send_alert(f"🚨 月预算即将耗尽!剩余: ${self.monthly_budget - self.monthly_cost:.2f}")
self.alerts_sent.add("monthly_90")
def get_cost_report(self) -> dict:
"""生成成本报告"""
today = datetime.date.today()
return {
"today_cost": float(self.daily_costs[today]),
"today_budget_usage": float((self.daily_costs[today] / self.daily_budget) * 100),
"month_cost": float(self.monthly_cost),
"month_budget_usage": float((self.monthly_cost / self.monthly_budget) * 100),
"remaining_daily": float(self.daily_budget - self.daily_costs[today]),
"remaining_monthly": float(self.monthly_budget - self.monthly_cost),
"cost_by_day": {str(k): float(v) for k, v in self.daily_costs.items()}
}
def _send_alert(self, message: str):
"""发送告警(可接入邮件、短信、Slack等)"""
print(f"[COST ALERT] {message}")
# 实际应用中,这里应该发送到监控系统
预算控制策略
设置多层次的预算控制,防止ChatGPT API速率限制带来的意外开支:
pythonclass BudgetController:
"""
预算控制器:自动管理API使用以控制成本
"""
def __init__(self, cost_monitor: CostMonitor):
self.cost_monitor = cost_monitor
self.throttle_level = 0 # 0=正常, 1=轻度限流, 2=严重限流, 3=停止
async def check_budget_before_call(self, model: str, estimated_cost: float) -> bool:
"""
调用前检查预算
返回是否允许调用
"""
report = self.cost_monitor.get_cost_report()
# 更新限流级别
if report['month_budget_usage'] >= 95:
self.throttle_level = 3 # 停止所有非关键调用
elif report['month_budget_usage'] >= 85:
self.throttle_level = 2 # 严重限流
elif report['today_budget_usage'] >= 90:
self.throttle_level = 1 # 轻度限流
else:
self.throttle_level = 0 # 正常
# 根据限流级别决定是否允许调用
if self.throttle_level == 3:
return False # 完全停止
if self.throttle_level == 2 and model == "gpt-4o":
return False # 停止昂贵模型
if self.throttle_level == 1 and estimated_cost > 0.01:
return False # 停止大额请求
return True
def get_alternative_model(self, preferred_model: str) -> str:
"""根据预算情况推荐替代模型"""
if self.throttle_level == 0:
return preferred_model
# 降级映射
downgrade_map = {
"gpt-4o": "gpt-4o-mini" if self.throttle_level == 1 else "gpt-3.5-turbo",
"gpt-4o-mini": "gpt-3.5-turbo",
"gpt-3.5-turbo": "gpt-3.5-turbo" # 已是最便宜
}
return downgrade_map.get(preferred_model, "gpt-3.5-turbo")
使用量优化建议
基于ChatGPT API速率限制和成本分析,提供优化建议:
pythonclass UsageOptimizer:
"""
使用优化器:分析使用模式并提供优化建议
"""
def __init__(self):
self.usage_patterns = defaultdict(list)
self.recommendations = []
def analyze_usage(self, logs: List[Dict]) -> List[str]:
"""分析使用日志,生成优化建议"""
self.recommendations = []
# 分析1:识别重复请求
prompt_counts = defaultdict(int)
for log in logs:
prompt_hash = hashlib.md5(log['prompt'].encode()).hexdigest()[:8]
prompt_counts[prompt_hash] += 1
duplicate_rate = sum(1 for c in prompt_counts.values() if c > 1) / len(prompt_counts)
if duplicate_rate > 0.2:
self.recommendations.append(
f"📊 发现{duplicate_rate*100:.1f}%的请求是重复的,建议实施缓存策略"
)
# 分析2:模型使用分布
model_costs = defaultdict(float)
model_counts = defaultdict(int)
for log in logs:
model_costs[log['model']] += log['cost']
model_counts[log['model']] += 1
for model, cost in model_costs.items():
if model == "gpt-4o" and cost > sum(model_costs.values()) * 0.7:
self.recommendations.append(
f"💰 GPT-4o占总成本的{cost/sum(model_costs.values())*100:.1f}%,"
f"考虑将部分请求降级到GPT-3.5-turbo"
)
# 分析3:请求时间分布
hour_counts = defaultdict(int)
for log in logs:
hour = datetime.datetime.fromisoformat(log['timestamp']).hour
hour_counts[hour] += 1
peak_hour = max(hour_counts, key=hour_counts.get)
peak_percentage = hour_counts[peak_hour] / sum(hour_counts.values())
if peak_percentage > 0.3:
self.recommendations.append(
f"⏰ {peak_percentage*100:.1f}%的请求集中在{peak_hour}点,"
f"建议实施请求平滑策略"
)
# 分析4:Token效率
avg_input_tokens = sum(log['input_tokens'] for log in logs) / len(logs)
avg_output_tokens = sum(log['output_tokens'] for log in logs) / len(logs)
if avg_input_tokens > 1000:
self.recommendations.append(
f"📝 平均输入{avg_input_tokens:.0f} tokens较高,考虑优化prompt"
)
if avg_output_tokens > 500:
self.recommendations.append(
f"📤 平均输出{avg_output_tokens:.0f} tokens,可以通过max_tokens参数限制"
)
return self.recommendations
告警和通知配置
建立完善的告警体系,及时发现ChatGPT API速率限制相关问题:
pythonclass AlertManager:
"""
告警管理器:统一管理各类告警
"""
def __init__(self, config: Dict):
self.config = config
self.alert_history = []
async def send_alert(self, alert_type: str, severity: str, message: str, data: Dict = None):
"""发送告警"""
alert = {
"timestamp": datetime.datetime.now().isoformat(),
"type": alert_type,
"severity": severity, # info, warning, critical
"message": message,
"data": data or {}
}
self.alert_history.append(alert)
# 根据严重程度选择通知渠道
if severity == "critical":
await self._send_to_all_channels(alert)
elif severity == "warning":
await self._send_to_monitoring(alert)
else:
await self._log_only(alert)
async def _send_to_all_channels(self, alert: Dict):
"""发送到所有渠道(邮件、短信、Slack)"""
# 邮件
if self.config.get('email_enabled'):
await self._send_email(alert)
# Slack
if self.config.get('slack_enabled'):
await self._send_slack(alert)
# 短信(仅关键告警)
if self.config.get('sms_enabled'):
await self._send_sms(alert)
async def _send_slack(self, alert: Dict):
"""发送Slack通知"""
import aiohttp
webhook_url = self.config['slack_webhook']
payload = {
"text": f"🚨 {alert['severity'].upper()}: {alert['message']}",
"attachments": [{
"color": "danger" if alert['severity'] == "critical" else "warning",
"fields": [
{"title": k, "value": str(v), "short": True}
for k, v in alert['data'].items()
]
}]
}
async with aiohttp.ClientSession() as session:
await session.post(webhook_url, json=payload)
常见问题与故障排除
在使用ChatGPT API的过程中,除了ChatGPT API速率限制,还会遇到各种问题。本章汇总了最常见的ChatGPT API速率限制相关问题及其解决方案,帮助你快速诊断和解决问题。
速率限制相关FAQ
Q1: 为什么我明明没有达到RPM限制,还是收到429错误?
这是ChatGPT API速率限制的常见误解。记住,限制是多维度的:
- 检查TPM限制:可能是token数超限
- 检查组织级限制:同组织其他成员的使用也计算在内
- 检查并发限制:某些端点有并发请求限制
- 检查短时间突发:OpenAI可能有未公开的突发限制
Q2: 如何准确计算token数量?
Token计算对管理ChatGPT API速率限制至关重要:
pythonimport tiktoken
def count_tokens(text: str, model: str = "gpt-3.5-turbo") -> int:
"""准确计算token数量"""
# 获取模型对应的编码器
encoding = tiktoken.encoding_for_model(model)
# 计算tokens
tokens = encoding.encode(text)
return len(tokens)
# 经验法则(粗略估算)
# 英文:1 token ≈ 4个字符 ≈ 0.75个单词
# 中文:1 token ≈ 0.5-0.7个汉字
Q3: 多个API Key可以突破速率限制吗?
可以,但要注意:
- 每个API Key需要独立的付费账户
- OpenAI可能检测并限制明显的规避行为
- 建议使用合法的多账户架构,而非恶意规避
- 考虑申请企业账户获得更高限制
Q4: 为什么同样的请求,有时快有时慢?
这涉及ChatGPT API速率限制之外的因素:
- 服务器负载:高峰期响应较慢(可查看OpenAI状态页面了解实时状态)
- 请求复杂度:复杂推理需要更多时间
- 地理位置:距离数据中心远近影响延迟
- 模型差异:GPT-4比GPT-3.5慢3-5倍
常见错误代码及处理
除了429(速率限制),还有其他常见错误:
| 错误代码 | 含义 | 处理方法 |
|---|---|---|
| 400 | 请求格式错误 | 检查参数格式、JSON语法 |
| 401 | 认证失败 | 检查API Key是否正确 |
| 403 | 权限不足 | 确认账户状态和模型权限 |
| 404 | 端点不存在 | 检查API版本和路径 |
| 429 | 速率限制 | 实施重试和限流策略 |
| 500 | 服务器错误 | 等待后重试,考虑降级 |
| 503 | 服务不可用 | 检查OpenAI状态页,等待恢复 |
性能优化技巧
提升在ChatGPT API速率限制下的性能是每个开发者的必备技能。以下技巧能够帮助你在ChatGPT API速率限制约束下,最大化应用性能:
1. 优化Prompt长度
pythondef optimize_prompt(prompt: str, max_length: int = 1000) -> str:
"""优化prompt长度,减少token消耗"""
# 移除多余空白
prompt = " ".join(prompt.split())
# 如果太长,智能截取
if len(prompt) > max_length:
# 保留开头和结尾,中间用省略号
start = prompt[:max_length//2]
end = prompt[-(max_length//2):]
prompt = f"{start}... [内容已省略] ...{end}"
return prompt
2. 批处理小请求
pythonasync def batch_small_requests(requests: List[str]) -> List[str]:
"""将多个小请求合并为一个,减少RPM消耗"""
if len(requests) == 1:
return [await call_api(requests[0])]
# 合并请求
combined = "\n\n---\n\n".join([
f"请求{i+1}: {req}" for i, req in enumerate(requests)
])
prompt = f"请分别回答以下{len(requests)}个问题:\n\n{combined}"
# 一次调用
response = await call_api(prompt)
# 分割响应
return response.split("---")
3. 实施智能重试
pythonclass SmartRetry:
"""智能重试策略"""
def __init__(self):
self.failure_history = defaultdict(list)
async def execute(self, func, *args, **kwargs):
"""执行带智能重试的函数"""
key = f"{func.__name__}:{str(args)[:50]}"
failures = self.failure_history[key]
# 如果最近失败太多次,直接返回缓存或降级
if len(failures) >= 3 and time.time() - failures[-1] < 300:
return await self.get_fallback_response(*args)
try:
result = await func(*args, **kwargs)
# 成功后清除失败记录
self.failure_history[key] = []
return result
except Exception as e:
self.failure_history[key].append(time.time())
# 根据失败次数决定等待时间
wait_time = min(2 ** len(failures), 60)
await asyncio.sleep(wait_time)
# 递归重试
return await self.execute(func, *args, **kwargs)
故障诊断检查清单
遇到问题时的系统化排查流程:
pythonclass DiagnosticTool:
"""
诊断工具:快速定位ChatGPT API问题
"""
async def run_diagnostics(self) -> Dict:
"""运行完整诊断"""
results = {
"timestamp": datetime.datetime.now().isoformat(),
"checks": {}
}
# 1. 检查API Key
results["checks"]["api_key"] = await self._check_api_key()
# 2. 检查网络连接
results["checks"]["network"] = await self._check_network()
# 3. 检查速率限制状态
results["checks"]["rate_limits"] = await self._check_rate_limits()
# 4. 检查账户状态
results["checks"]["account"] = await self._check_account_status()
# 5. 测试各模型可用性
results["checks"]["models"] = await self._test_models()
# 生成诊断报告
results["summary"] = self._generate_summary(results["checks"])
return results
async def _check_api_key(self) -> Dict:
"""检查API Key有效性"""
try:
# 尝试一个最小请求
response = await openai.ChatCompletion.acreate(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "test"}],
max_tokens=1
)
return {"status": "OK", "message": "API Key有效"}
except openai.AuthenticationError:
return {"status": "ERROR", "message": "API Key无效或已过期"}
except Exception as e:
return {"status": "WARNING", "message": str(e)}
未来趋势预测
基于当前发展,ChatGPT API速率限制的未来趋势:
2025年预期变化:
- 更细粒度的限制控制:可能引入基于功能的限制(如图像生成单独计算)
- 动态定价模型:根据使用时段和负载动态调整价格
- 区域化限制:不同地区可能有不同的限制策略
- 智能限流:AI自动识别并限制滥用行为
应对策略建议:
- 建立灵活的架构,便于适应变化
- 保持多供应商策略,降低依赖风险
- 持续优化使用效率,降低成本
- 关注官方更新,及时调整策略
总结与最佳实践
管理ChatGPT API速率限制的核心原则:
💡 核心原则总结:
- ✅ 预防优于治疗:提前规划,避免触及限制
- ✅ 监控是关键:实时了解使用状况
- ✅ 优雅降级:准备好备选方案
- ✅ 持续优化:定期审查和改进使用模式
- ✅ 成本意识:平衡性能与开支
- ✅ 文档记录:详细记录问题和解决方案
通过本指南介绍的策略和工具,你应该能够有效管理ChatGPT API速率限制,构建稳定、高效、经济的AI应用。记住,速率限制不是障碍,而是确保服务质量的必要机制。合理利用这些限制,反而能帮助你优化应用架构,提升整体性能。
随着AI技术的快速发展,ChatGPT API速率限制策略也在不断演进。保持学习,关注社区最佳实践,你的应用将能够在AI时代蓬勃发展。