Claude API中转服务指南:官方、Bedrock/Vertex 与聚合接入怎么选
面向国内开发者的 Claude API 中转服务最新指南:解释什么时候该选 Anthropic 官方、什么时候该选 AWS Bedrock 或 Google Vertex AI、什么时候第三方聚合层更省事,并给出上线前必须完成的兼容性验收清单。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
如果你现在还在搜“Claude API中转服务”,通常不是还缺一篇“什么是中转”的科普,而是已经准备把 Claude 接进产品、内部工具或自动化流程里,却卡在一个更现实的问题上:这条链路到底该走 Anthropic 官方,还是云平台托管,还是第三方聚合层。这个选择会直接影响采购门槛、上线速度、原生能力完整度、团队治理方式,以及后面每一次排障的成本。
更麻烦的是,中文互联网上不少文章仍停留在 Claude 3.5 或 Claude 3.7 的旧语境里,把“能调通”写成“适合上线”,把“OpenAI-compatible”写成“完全等价”。如果你继续用这种旧判断来选路,最容易踩的坑不是首日接不上,而是项目已经准备交付时,才发现某个关键能力、计费逻辑或回退路径根本没验过。
TL;DR
- 如果你最在意官方采购关系、原生 Claude 能力完整度,以及长期维护时的供应商边界,优先选
Anthropic 官方。 - 如果你需要企业级云治理、区域化基础设施、统一云账单或把模型接入纳入现有 AWS / GCP 体系,优先看
AWS Bedrock或Google Vertex AI;但别忽略当前 endpoint tradeoff:从Claude Sonnet 4.5/Claude Haiku 4.5及后续模型开始,regional endpoint比global endpoint多10%成本,而 Anthropic 官方1P API仍是global-only(AnthropicPricing,2026-03-19 验证)。 - 如果你当前最现实的目标是让国内团队更快接入、用统一余额管理多模型、减少支付和账号前置条件,第三方聚合层通常最省事;但上线前必须先验 API feature、账单模式、密钥治理和回退路径,而且第一轮 smoke test 最好先按
官方 deprecations / model docs > live catalog / console > quick-start / SDK > 场景页 / 定价页的顺序确认 model ID,再用和当前文档对得上的名字来做,不要直接把官方 alias 套到所有路径。如果某个聚合页现在还把Claude 3.5或Claude 3.7当默认首测模型,也不要只把它当成“旧教程”:Anthropic 当前Model deprecations页面已经把Claude Sonnet 3.5写进2025-10-28的退役表,也把Claude Sonnet 3.7写进2026-02-19的退役记录(AnthropicModel deprecations/Models overview,2026-03-19 验证)。这时正确动作不是继续赌示例名还能跑,而是先回官方 deprecations 和 live catalog 重新选当前可用 ID。 - 这篇文章最重要的两个交付物是一张
Claude API 三路决策矩阵,以及一份上线前 6 项兼容性验收清单。如果这两项对不上你的场景,就不要只因为“能跑通”就把某条路径放进生产。
为什么今天再搜 Claude API 中转,判断标准已经变了
先把旧语境拿掉。Anthropic 最近公开的发布与产品语境已经进入 Claude Opus 4.6、Claude Sonnet 4.6、Claude Haiku 4.5 这一代;其中当前公开价格表述仍落在输入/输出 $5/$25、$3/$15、$1/$5 每百万 token 这三个主档位上(Anthropic Claude Opus 4.6 / Claude Sonnet 4.6 / Claude Haiku 4.5 / Pricing,2026-03-19 验证)。更关键的是,Anthropic 当前 Model deprecations 页面已经把 Claude Sonnet 3.5 写进 2025-10-28 的退役表,也把 Claude Sonnet 3.7 写进 2026-02-19 的退役记录(Anthropic Model deprecations / Models overview,2026-03-19 验证)。这意味着很多仍然把 Claude 3.5 或 Claude 3.7 写成“最新”“主流首选”“默认首测”的文章,已经不只是过时,而是会直接误导你的第一轮验证动作。
接入路径也不是“官方 API 或中转”这么简单。Anthropic 官方定价页明确写明,Claude 模型不仅能通过 Anthropic API 使用,也可以通过 AWS Bedrock 和 Google Vertex AI 获取(Anthropic Pricing;Claude on Vertex AI,2026-03-19 验证)。如果你的组织已经有成熟的 AWS 或 GCP 治理体系,这两条路径往往比“先上中转再说”更贴近长期答案。更关键的是,Anthropic 的模型文档长期把 Claude API、AWS Bedrock 和 GCP Vertex AI 当成不同的 model-ID surface 处理;即使你今天准备测的是 Claude Sonnet 4.6,也应该以各自 provider 当前 console / catalog 里能看到的 exact ID 为准,而不是假设三条路径共用同一个字符串(Anthropic Models overview / Claude on Vertex AI,2026-03-19 验证)。这就是为什么今天做第一轮验证时,不能假设所有路径都吃同一套模型名。
地区与计费规则同样不能继续用旧印象替代。Anthropic 当前帮助中心里关于 Where is the Claude API supported? 的回答只保留了“supported in a number of locations”这层泛化提示;如果你要看精确名单,更稳的页面是 Claude Docs 里的 Supported regions,它当前仍明确列出日本和台湾,但未列出中国大陆(Anthropic Supported regions;Claude Help Center Where is the Claude API supported?,2026-03-19 验证)。在计费上,Anthropic 现在把 Claude API、Workbench 与 Claude Code 的开发者使用统一放在 prepaid usage credits 体系里,而不是很多旧文章里笼统描述的“开通官方后按月自然扣费”(Claude Help Center How do I pay for my Claude API usage?,2026-03-19 验证)。
还有一个现在很容易把人带偏的细节:Anthropic 在 2025-09-16 统一了开发者品牌,旧教程里常见的 console.anthropic.com 现在会跳到 platform.claude.com,帮助中心则以 support.claude.com 为准。如果你排查接入时还在旧域名、旧截图和新文档之间来回切换,不要先把这种入口迁移误判成平台失效(Claude Developer Platform Release notes overview,2026-03-19 验证)。
如果你明确在比较 Bedrock / Vertex,还有一条现在不能忽略:云路径当前存在 global endpoints 与 regional endpoints 的差异化语境,而且从 Claude Sonnet 4.5 / Claude Haiku 4.5 及后续模型开始,regional endpoints 比 global endpoints 多 10% 成本,而 Claude API 1P 当前仍是 global-only(Anthropic Pricing;Claude on Vertex AI;Google Vertex AI 当前文档,2026-03-19 验证)。这不是云文档里的枝节,而是你做合规、区域路由和上线预案时必须先确认的条件。
还有一个最容易被忽略的变化:Anthropic 自己提供了 OpenAI SDK compatibility,但官方文档仍把它呈现为带 feature-gap 的兼容层,而不是可以默认视为原生 Claude API 等价面的接口;例如当前文档仍明确有部分能力或参数只在原生 Claude API surface 上可用(Anthropic OpenAI SDK compatibility / Data residency,2026-03-19 验证)。这就是为什么今天判断“中转是否可用”,已经不能只看它能不能把 chat.completions 跑起来。
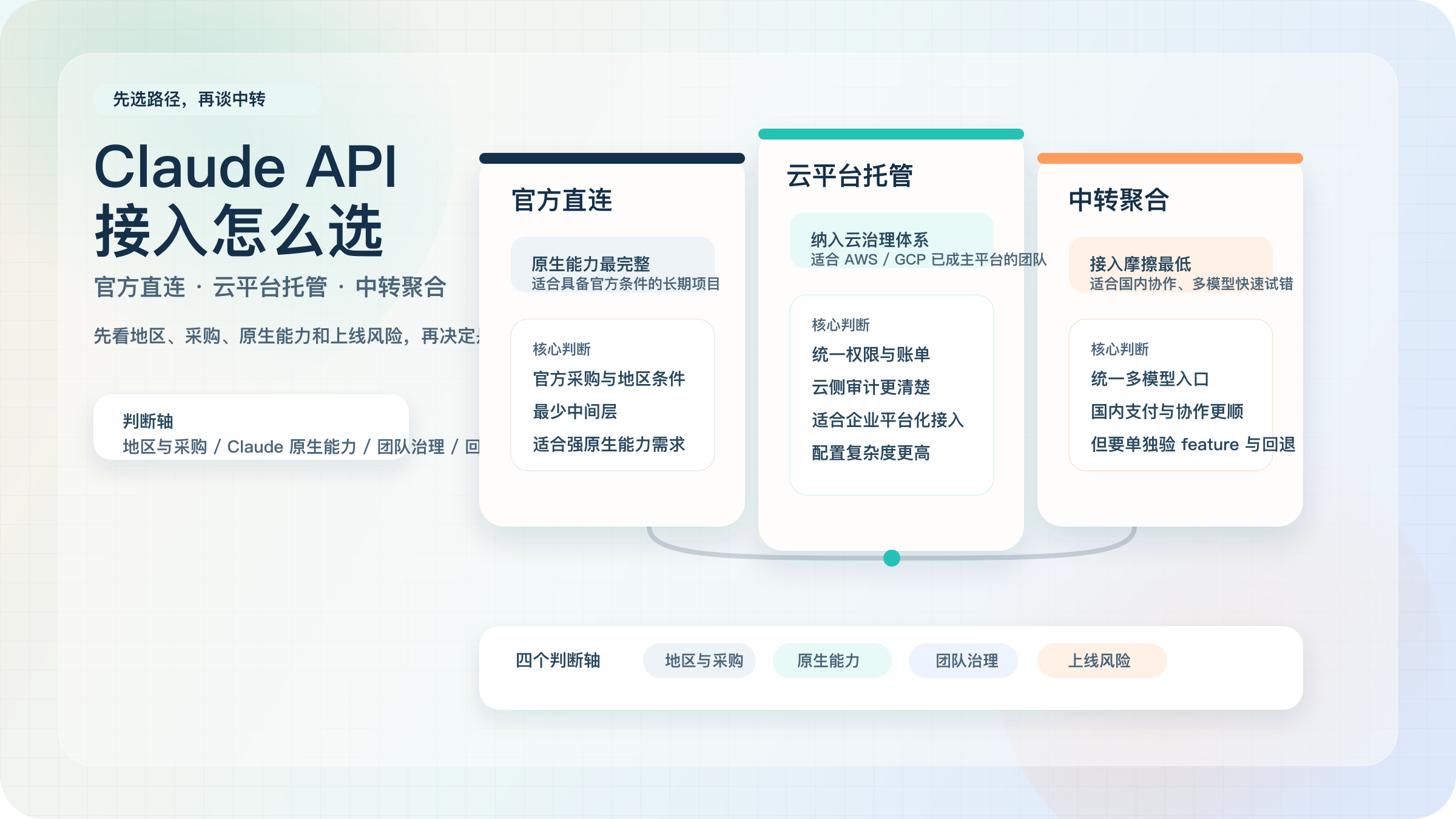
官方直连、云平台托管、中转聚合,到底怎么选
真正有用的判断方式,不是问“哪条路最先进”,而是先问“哪条路最符合我的组织约束”。如果你的团队已经具备可用地区条件、能够直接管理 Anthropic Console、并且最在意 Claude 原生能力完整度,官方直连仍然是最干净的路径。它的优势不在于“更神秘”,而在于当你以后要用更原生的 Claude feature 时,不需要再猜中间层到底支持到哪一层。
如果你的团队本来就在 AWS 或 GCP 上运行核心业务,那么 Bedrock 或 Vertex AI 的价值也不是“多绕一层”,而是把安全、审计、权限和账单都留在已有云体系里。官方文档也明确把 Bedrock 和 Vertex AI列为 Claude 的正式可用平台(Anthropic Pricing;Claude on Vertex AI,2026-03-19 验证)。这种路径对大公司或已经深度云化的团队尤其合理,因为它让 Claude 接入变成现有平台治理的一部分,而不是一条新的外部采购链路。
第三方聚合层则更像一种工程效率工具。它对国内团队最大的价值,通常不在于“替代网络”本身,而在于把统一余额、多模型接入、中文文档、国内支付和更低的试接入门槛收束到一个入口里。只要你接受多一层供应商,并愿意把关键 feature 与稳定性再验一遍,这条路经常是最快落地的方案。

下面这张矩阵可以直接拿来做第一轮判断:
| 路径 | 更适合你,如果你最在意 | 主要优势 | 主要风险 | 我的建议 |
|---|---|---|---|---|
| Anthropic 官方 | 原生 Claude 能力、官方采购边界、最少中间环节 | 能力最完整,文档与 feature 节奏最直接,排障边界清晰 | 可用地区和 Console 前置条件更严格,国内团队落地摩擦更高 | 只要你具备官方条件,并且项目会长期依赖 Claude 原生能力,优先保留 |
| AWS Bedrock / Google Vertex AI | 云治理、权限审计、账单统一、企业合规 | 更容易纳入既有云体系,便于权限和成本治理 | 平台配置与云侧概念更多;从 Claude 4.5 系列起 regional endpoint 比 global endpoint 多 10% 成本 | 已有 AWS / GCP 体系的团队,认真优先看这一条 |
| 第三方聚合 / 中转 | 快速接入、国内支付、统一多模型、团队试错效率 | 上手快,统一余额和 key 管理,多模型切换成本低 | 需要单独验证功能覆盖、计费口径、稳定性和回退路径 | 对 MVP、国内团队协作、快速验证很友好,但别跳过上线验收 |
如果你还是拿不准,可以直接套一个简化判断。你有官方采购和地区条件,而且预计会长期吃到 Claude 原生能力,就先走官方;你已经深度云化,希望把模型接入放进云治理体系,就优先看 Bedrock 或 Vertex;你更关心本周把项目跑起来、让国内团队低摩擦协作、多模型一起评估,那么聚合层通常更现实。真正要避免的,是明明在做长期生产项目,却因为一时省事,把 feature gap 和供应商锁定风险全都留到后面。
云路径还有一个更细的判断:如果你的重点是最高可用性和最少配置,global endpoint 通常更符合“先接入再评估”的节奏;如果你的重点是把数据路由边界明确锁进某个区域,那么 regional endpoint 才值得优先考虑,但前提是你先核对该模型当前是否真的在目标区域可用、以及这 10% premium 是否值得你为区域约束付出。反过来,如果你的目标只是尽快拿到官方原生能力而不是做区域隔离,Anthropic 官方 1P API 当前仍是 global-only,这反而让它在第一轮试通里更少一个端点层面的成本变量(Anthropic Pricing;Claude on Vertex AI;云平台当前控制台/定价页,2026-03-19 验证)。很多团队真正该问的不是“要不要上云”,而是“这个项目值不值得为区域约束增加额外配置与成本复杂度”。
如果你还需要单独核对 Claude 当前价格和不同模型档位,可以顺手参考这篇 Claude API 价格指南;如果你明确会走云路径,再补这篇 AWS Claude 定价指南 会更顺。
什么情况下第三方聚合最省事,什么情况下反而会放大风险
第三方聚合最适合的,不是“永远替代官方”,而是那些目标明确、组织约束清晰的场景。比如你正在做 MVP,团队成员主要在国内协作,研发需要快速试不同模型,又不想先把 Anthropic Console、外币支付、云平台路由这些前置条件全部解决完。这种时候,聚合层的价值非常直接:它把“拿到一个可测的 API 入口”这件事大幅简化了。
以 LaoZhang 当前公开文档为例,它现在把自己定位为面向企业与开发者的统一 AI 接口平台,支持 200+ AI models、按量计费、无月费,并提供 $0.05 的测试额度用于接口连通性验证;文档也给出了 OpenAI 官方 SDK 通过 base_url="https://api.laozhang.ai/v1" 接入的方式(LaoZhang Docs 首页,2026-03-19 验证)。这类聚合层对团队最现实的帮助,不在于“更先进”,而在于少折腾一套接入条件。
但今天再往前走一步,你还得多看一眼它的实时模型列表,而不是只记住某一个教程页的示例名。LaoZhang 当前公开资料本身就存在多层漂移:文档首页仍突出 Claude 3.5 Sonnet、Claude 3 Opus、Claude 3 Haiku,Getting Started / OpenAI SDK 页可见 claude-sonnet-4-20250514,而 API Developer Manual、企业定价页、OpenClaw 等其他页面又还能看到 claude-sonnet-4、claude-sonnet-4-5、claude-sonnet-4-6 这类写法;与此同时,它自己的 Models API 文档公开了 GET https://api.laozhang.ai/v1/models 作为实时模型列表入口(LaoZhang Docs 首页 / Getting Started / OpenAI SDK / Models API / API Developer Manual / Enterprise Pricing / OpenClaw,2026-03-19 验证)。这说明聚合层第一步不该是死记某一个 model ID,而该是先看官方 deprecations 与 live catalog,再决定 smoke test 用哪一个名字。
但聚合层同样最容易被写成“万能捷径”,这正是中文搜索结果里最常见的误导。如果你的项目强依赖 Claude 原生能力,或者你必须向安全、采购、法务明确交代供应商边界,那么多一层中间平台就不是纯收益。你要额外确认模型更新是否跟得上、关键 feature 是否真的可用、rate limit 和账单口径是否稳定、以及出问题时能不能快速回退到官方或云平台。
还有一种场景也不适合把聚合层当默认答案:你已经在线上用 Anthropic 官方或云平台跑核心链路,而且团队对这条链路很熟。这时候聚合层更适合作为辅链路、国内团队入口或备用入口,而不是为了“统一一下看起来更方便”就把所有流量一次性切过去。中转本来是为降低摩擦服务的,不该反过来制造新的架构不确定性。
别把 OpenAI-compatible 当成原生等价:真正要验什么
这里是当前大多数中文文章最欠缺、但最值得补的一节。很多供应商会把“OpenAI-compatible”“只改 base URL”写成核心卖点,这句话本身没有错,但它只回答了“是不是更容易接”,没有回答“是不是原生等价”。而在 Claude 这件事上,两者差别很大。
Anthropic 官方文档当前明确提醒,OpenAI SDK compatibility 更适合测试和模型能力比较,不是大多数场景的长期 production-ready 方案;同时也点出了几个关键边界,比如部分参数或能力只在原生 Claude API surface 上可用,system 与 developer message 的处理方式也和 OpenAI 不完全相同(Anthropic OpenAI SDK compatibility / Data residency,2026-03-19 验证)。这意味着“把请求打通”只是起点,不是终点。
所以判断一条聚合路径时,别只验“有没有返回内容”,而要验“我真正依赖的能力有没有被保持”。如果你的项目只做基础文本生成,这个问题可能没那么尖锐;但如果你要用 prompt caching、extended thinking、citations、复杂工具调用、细粒度权限或更严格的结构化输出约束,兼容层和原生路径之间的差异就会直接变成生产问题。
把这件事讲透之后,很多选择会自然变得清楚。官方直连适合那些必须把 Claude feature 用完整的团队;云平台适合那些希望把治理能力和模型接入统一到现有云基础设施里的团队;聚合层适合那些愿意接受“有一层兼容抽象”,但会认真做 feature 验收、并为回退留路的团队。真正危险的不是用聚合层,而是把聚合层误认为原生 Claude API 的无损镜像。
如果你后续需要补 429、配额和稳定性这类问题,可以再看这篇 Claude API Rate Limit 指南。这类问题放在上线前验,比上线后被动补救便宜得多。
5 分钟接入示例:如何用当前写法快速试通
如果你只是先验证“这条路径能不能工作”,不要一上来就把同一个模型名硬套到所有 provider。Anthropic 当前文档仍把官方、Bedrock、Vertex 视作不同的 model-ID surface,而聚合层更适合先看官方 deprecations、再看 live catalog、最后再看 quick-start 文档,因为同一平台的不同页面也可能处在不同更新节奏(Anthropic Model deprecations / Models overview / Claude on Vertex AI;LaoZhang Models API / OpenAI SDK,2026-03-19 验证)。这里说的 live catalog,指的是你带着自己的 key 实际调用 GET /v1/models 拿到的响应,而不是文档页里写死的示例块、模型列表示意或营销页截图,因为这些公开页面本身也可能比真实目录慢一步。最稳的做法,是先按 provider 当前实时可见的模型列表做第一轮 smoke test,再决定要不要额外验证 alias 兼容。
你可以先记一句规则:官方 deprecations / model docs > live catalog / console > quick-start / SDK > 场景页 / 定价页。如果你现在只做一件事,就先确认官方 deprecations 没有把你准备测的旧模型判进退役区,再打一次 /v1/models,把返回里的 exact Claude model ID 记下来,然后再用同一个 ID 做第一轮 chat.completions,不要在不同文档页之间盲目来回换名字。反过来,如果某个聚合页还把 Claude 3.5 或 Claude 3.7 当默认首测模型,就不要只把它降级成旧教程参考;更稳的动作,是先回官方 Model deprecations 确认 3.5 已写入 2025-10-28 的退役表、3.7 已写入 2026-02-19 的退役表,然后直接改用当前 live catalog 里仍可见的 exact Claude model ID。
下面这张表可以直接拿来做第一轮试通:
| 路径 | 第一个 endpoint / base_url | 首测 model ID | 先验证什么 | 什么现象说明先别继续加功能 |
|---|---|---|---|---|
| Anthropic 官方 | Anthropic SDK / /v1/messages | claude-sonnet-4-6 | messages.create 能稳定返回文本与 usage | 如果你后面依赖原生 Claude feature,就继续保留原生路径,不要先降到 compatibility 层 |
| AWS Bedrock | Bedrock Claude endpoint(global 或 regional) | 以当前 Bedrock console / model access 页面可见的 exact Claude Sonnet 4.6 ID 为准 | 账号是否已开通模型访问、endpoint type 是否选对 | 如果一开始就卡在区域、权限或 endpoint type,不要先怀疑提示词,先回头核对云侧配置 |
| Google Vertex AI | Vertex AI Claude endpoint(global 或 regional) | 以当前 Vertex Model Garden / endpoint 配置里可见的 exact Claude Sonnet 4.6 ID 为准 | 项目、区域和模型可见性是否一致 | 如果模型可见性和区域设定不一致,先修正平台配置,再判断是否是模型问题 |
| 第三方聚合层 | https://api.laozhang.ai/v1 | 先以 live catalog 返回的 exact Claude model ID 为准;claude-sonnet-4-20250514 这类 quick-start 示例只能当候选值 | 先查 /v1/models 是否列出目标 Claude 系列,再测 chat.completions 是否稳定回字 | 如果 quick-start、场景页、定价页和 /v1/models 给出的名字对不上,先以 live catalog 为准并记录 exact ID,不要先假设“完全兼容” |
这张表的意义不是替你一次性选完,而是把最容易混淆的第一步先分开。只要首测 model ID、endpoint type 和 provider 文档没对齐,后面所有关于价格、限流和 feature 的判断都容易跑偏。对聚合层来说,最值得先补的一步不是“多换几个 model name 试试”,而是先让 /v1/models、当前 SDK 页和你准备跑的 endpoint 对齐。
原生 Claude API 用 Anthropic 官方 SDK 时,可以直接这样试:
pythonfrom anthropic import Anthropic
client = Anthropic(api_key="YOUR_ANTHROPIC_API_KEY")
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=512,
messages=[
{
"role": "user",
"content": "请用三句话说明,什么情况下应该优先选择 Claude API 中转层。",
}
],
)
print(message.content[0].text)
如果你要先验证聚合层是否能快速接上 OpenAI 官方 SDK,最稳的一步是先列模型,而不是先写死一个教程页里的名字。LaoZhang 当前 Models API 文档公开了 GET https://api.laozhang.ai/v1/models,这条接口就是你确认 live catalog 的最快入口(LaoZhang Models API,2026-03-19 验证):
bashcurl https://api.laozhang.ai/v1/models \
-H "Authorization: Bearer YOUR_LAOZHANG_API_KEY"
确认 live catalog 里已经能看到你要测的 Claude 系列之后,再去跑 chat.completions。如果你当前参考的是 LaoZhang 快速接入或 OpenAI SDK 页面,那么可以先把这些页面里常见的 claude-sonnet-4-20250514 当成候选值;但只有在 /v1/models 也返回这个 exact ID 时,才值得直接拿它做第一轮验证。反过来,如果你在 API Developer Manual、企业定价页、OpenClaw 或其他场景页里看到的是 claude-sonnet-4、claude-sonnet-4-5、claude-sonnet-4-6 等名字,优先以 live catalog 里真实返回的那个 ID 为准(LaoZhang Getting Started / OpenAI SDK / API Developer Manual / Enterprise Pricing / OpenClaw / Models API,2026-03-19 验证):
pythonfrom openai import OpenAI
client = OpenAI(
api_key="YOUR_LAOZHANG_API_KEY",
base_url="https://api.laozhang.ai/v1",
)
response = client.chat.completions.create(
model="YOUR_LIVE_CATALOG_MODEL_ID",
messages=[
{
"role": "user",
"content": "给我一份 Claude API 接入路径选择建议。",
}
],
)
print(response.choices[0].message.content)
这里故意不把聚合层示例写死成某一个当前页面上的名字,不是因为所有聚合层都绝对不支持官方 alias,而是因为第一轮 smoke test 的目标应该是“先让 live catalog、当前文档和实际调用用同一个名字对齐”,而不是先赌 alias 会自动兼容(Anthropic Pricing / Claude on Vertex AI;LaoZhang Getting Started / OpenAI SDK / Models API,2026-03-19 验证)。model 这一行最稳的做法,就是直接填你刚从 /v1/models 记下来的 exact Claude model ID。后面你一旦开始验 rate limit、结构化输出、工具调用或计费统计,这个 provider-specific 对照关系会帮你少走很多弯路。
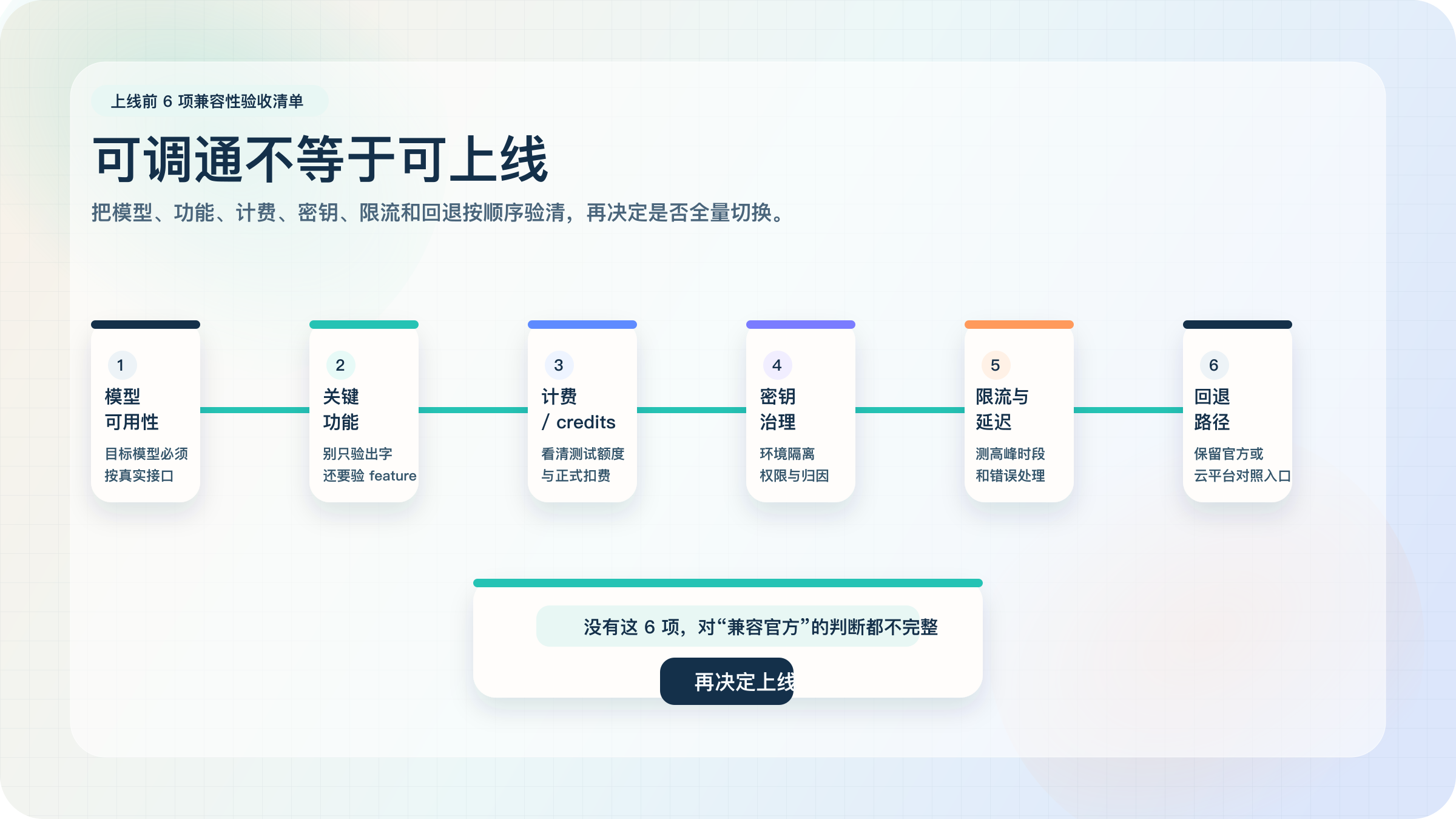
上线前 6 项兼容性验收清单
演示环境能返回一段文字,不等于生产就能稳。真正的分水岭,是你有没有把下面 6 项按顺序验掉。它们看起来像常识,但中文搜索结果里最常见的问题,恰恰就是把这些步骤用一句“兼容官方 API”带过去。
-
先验模型可用性。你计划在线上跑哪个模型,就直接用那个模型做烟雾测试,而不是只看文档首页有没有名字。Anthropic 当前公开模型主语境已经是
Claude Opus 4.6、Claude Sonnet 4.6、Claude Haiku 4.5(AnthropicClaude Opus 4.6/Claude Sonnet 4.6/Claude Haiku 4.5,2026-03-19 验证),所以别再用一组旧模型名试通后,就默认你的真实目标模型也没问题。 -
再验关键 feature。你的项目到底依赖哪些能力,就验哪些能力。最典型的误判是:文本输出正常,就以为 prompt caching、structured output、工具调用、message handling 也一定正常。Anthropic 官方已经明确提醒 OpenAI SDK compatibility 不是所有 feature 的长期等价入口(Anthropic
OpenAI SDK compatibility,2026-03-19 验证),这一步不能省。 -
把计费方式和 credits 规则搞清楚。Anthropic 当前把 Claude API、Workbench 与 Claude Code 使用放在 prepaid usage credits 下,credits 用完后会影响继续调用(Claude Help Center
How do I pay for my Claude API usage?,2026-03-19 验证)。如果你走聚合层,也要单独核实它是预充值、统一余额、自动续费,还是别的 billing mode。不要把“注册赠送测试额度”和“正式上线的支付路径”混成一件事。
-
检查密钥治理。一个人调 demo 可以只要一把 key,但团队上线至少要确认环境隔离、权限收敛、费用归因和泄漏后的撤换方案。尤其是聚合层,如果你是因为“统一多模型接口”而选它,就更应该把密钥管理和模型权限拆开确认,不要让便利性反过来变成治理黑箱。
-
评估限流、延迟和错误处理。很多文章把“国内可直连”当成稳定性的同义词,其实远远不够。你要测的是峰值时段延迟、请求失败后的重试策略、限流提示是否清晰、账单是否只统计成功调用,以及回源异常时你的应用有没有降级方案。真正的线上事故,往往不是完全调用不了,而是高峰期表现不稳定。
-
最后保留回退路径。即使你最终决定走聚合层,也应该保留一条最小化的官方或云平台对照路径;如果你走官方或云平台,也应该明确哪些场景可以暂时切到备用入口。验收的目标不是证明某个平台完美,而是证明你的业务不会被单一路径绑死。
如果你真的把这 6 项做完,再回头看“官方、云平台、聚合层”三条路径,结论通常会比看十篇供应商文章更稳。因为这时候你判断的不是营销口号,而是自己的业务约束。
常见问题
Claude 这类聊天订阅,能直接拿来调用 Claude API 吗?
至少按 Anthropic 当前可直接核实的帮助页,不能把聊天订阅和 Claude API 计费混成一件事。更直接地说,Anthropic 已单独写明 Claude paid plans and the Claude Console are separate products,聊天订阅不会自动包含 Console/API 权限(Claude Help Center I have a paid Claude subscription (Pro, Max, Team, or Enterprise plans). Why do I have to pay separately to use the Claude API and Console?,2026-03-19 验证)。在这个前提下,What is the Pro plan? 明确说 Pro plan 不包含通过 Claude Console 使用 API;What is the Max plan? 当前仍是聊天订阅说明页;Can I have a Claude account and a Console account? 则说明 Claude 账户和 Console 账户可以用同一邮箱,但会独立运作(Claude Help Center What is the Pro plan? / What is the Max plan? / Can I have a Claude account and a Console account?,2026-03-19 验证)。所以如果你团队里有人说“我已经买了 Claude Pro 或 Max,API 应该也能直接用”,更稳的动作仍然是先去 Console 侧单独确认 credits、组织权限和 API 计费设置。
中国团队是不是只能选第三方聚合层?
也不是。更稳的判断方式,是先把两个问题拆开:第一,Anthropic 当前 Supported regions 文档仍列出日本和台湾,但未列出中国大陆,这只能回答“官方当前 support list 里有没有对应 location”;第二,你的组织是否已经满足登录、采购、支付、云治理和原生 feature 需求,这决定了你到底该先走官方、云平台还是聚合层(Anthropic Supported regions;Claude Help Center Where is the Claude API supported?,2026-03-19 验证)。所以对很多中国团队而言,第三方聚合层通常是最快落地路径,但不是唯一答案。
第三方聚合层最值得验的不是价格,而是什么?
不是单次 token 价格,而是你依赖的 API feature 是否真的保留。价格可以晚一点再比,但如果上线后才发现关键 feature 不可用、message 处理行为不同、账单和限流口径不清,那切换成本会比多花一点 token 费用更高。很多团队真正亏的不是“买贵了”,而是“判断错了”。
如果聚合层不同文档页面给出的 Claude 模型名不一致,我该信谁?
先信官方 deprecations 和官方模型页,再信 live catalog 或 console 里的实时模型列表,然后才参考当前 quick-start / SDK 页面,最后才看场景页、定价页或旧教程页。原因很简单:这些页面往往不是同一时刻更新的,Getting Started、模型列表、定价页、工具场景页经常各自维护自己的 Claude model IDs,而营销首页甚至可能还保留旧代际模型(Anthropic Model deprecations / Models overview / Claude on Vertex AI;LaoZhang Docs 首页 / Models API / Getting Started / OpenAI SDK / API Developer Manual / Enterprise Pricing / OpenClaw,2026-03-19 验证)。所以第一轮 smoke test 的原则不该是“记一个最新模型名到处试”,而该是“先排除官方已经写进退役表的旧模型,再让 live catalog 和你准备调用的 endpoint 对齐,最后才决定要不要验证 alias 兼容”。否则你很容易把文档漂移误判成平台不稳定,或者把暂时能回字误判成完全原生等价。
如果我只是做一个内部工具或 MVP,还需要这么认真验吗?
需要,但可以把验收做轻一点。你不一定要把所有性能压测和复杂治理一次性做满,但至少要完成模型 availability、关键 feature、计费方式和回退路径这四项最小验证。因为 MVP 最大的风险,不是做不出来,而是做出来后被团队很快当成正式工具用,结果前面没验过的坑在流量起来后一起爆。
什么时候我应该先用聚合层,后面再考虑回切官方或云平台?
当你的首要目标是快速验证产品、让国内团队低摩擦协作、并同时评估多模型时,这种顺序通常是合理的。前提是你从第一天就把聚合层当作一条“可能升级、可能回切”的工程路径,而不是永久不变的黑箱依赖。只要你的代码层、计费监控和关键 feature 验收都留好了对照接口,后续迁移会轻很多。
真正值得记住的结论很简单:别把“Claude API 中转服务”理解成一个供应商关键词,而要把它理解成一条接入路径的组织选择。你不是在选谁的宣传页写得更热闹,而是在选未来几个月团队要共同维护的一条 API 入口。路径选对了,接入会很快;路径选错了,后面的每一步都会变贵。