Claude Sonnet 4.5 vs GPT-5:2025最全对比指南(性能/价格/场景选择)
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Claude Sonnet 4.5和GPT-5(o1-preview)是2025年最强的两款AI大模型,无论是性能、价格还是适用场景都有显著差异。本文基于SWE-bench、MMLU等权威benchmark测试,结合真实项目实测,深度对比两款模型在编程能力、推理能力、多模态、API定价等方面的表现。更重要的是,我们提供场景化决策指南、中国开发者完整接入方案、以及被忽视的失败案例分析和混合使用策略,帮助你做出最优选择。
对于技术选型而言,理解模型之间的本质差异比单纯对比benchmark分数更重要。Claude Sonnet 4.5在编程任务中表现突出,SWE-bench测试达到77.2%成功率,而GPT o1-preview在推理任务上更强,MMLU得分90.1%。但这些数字背后的实际含义、真实项目中的表现差异、以及成本效益分析,才是开发者真正需要的决策依据。
中国开发者面临的独特挑战也是本文重点。Claude和GPT的官方API在国内都存在访问限制,传统VPN方案延迟高达200-500ms,严重影响实时应用。我们将在第7章提供完整的解决方案,包括API代理服务、支付方式、延迟优化和合规性考虑。

GPT-5发布解析:Claude Sonnet 4.5 vs GPT-5完整对比
OpenAI于2025年8月7日正式发布GPT-5,这是该公司迄今最智能、最快速的AI模型。GPT-5采用全新的统一系统架构,包含gpt-5(标准版)、gpt-5-mini(轻量版)和gpt-5-nano(超轻量版)三个尺寸,以及付费用户专享的GPT-5 Pro(扩展推理版本)。本章澄清GPT-5的实际能力范围,明确本文对比的具体版本。
GPT-5的核心特性详解:
-
Thinking内置:GPT-5将思考能力内置于模型中,自动在需要时启用深度推理,无需用户手动切换模式。这是相比o1-preview的重大改进,o1系列需要显式调用推理模式,而GPT-5智能判断任务复杂度自动激活。
-
多尺寸模型:OpenAI首次推出同一代模型的多个尺寸版本:
- gpt-5:标准版,平衡性能和成本
- gpt-5-mini:轻量版,成本更低(约标准版的1/3)
- gpt-5-nano:超轻量版,适合高并发场景
- GPT-5 Pro:付费用户专享,扩展推理能力
-
智能路由:GPT-5内置智能路由器,根据对话复杂度自动选择使用高效模型还是深度推理模型,用户无需手动判断。这种设计使得开发者可以用单一API endpoint获得最优性价比。
OpenAI模型命名策略演变展示了其产品路线的变化:
- GPT-3系列(2020-2022):text-davinci-003等,使用描述性名称
- GPT-4系列(2023-2024):gpt-4、gpt-4-turbo、gpt-4o,采用数字+变体命名
- o系列(2024-2025):o1-preview、o1-mini,全新的字母命名规则
这种命名变化反映了OpenAI从通用对话模型向专业化、优化化模型的战略转型。o系列专注于推理优化,未来可能还会有专注于其他能力的字母系列。
Claude命名同样经历了演变。Anthropic的Claude模型有三个性能级别:Haiku(轻量)、Sonnet(平衡)、Opus(强大)。当前最强版本Claude Sonnet 4(发布于2024年10月22日)在社区中也被称为Claude 3.7或Claude 4.5,但官方正式名称是Claude Sonnet 4,API版本号为claude-sonnet-4-20241022。本文统一使用Claude Sonnet 4.5这一通用名称,指代这个最新版本。
本文对比的具体版本明确:我们对比的是Claude Sonnet 4(2024年10月22日版本)与GPT-5(2025年8月7日版本)。GPT-5是OpenAI最新发布的旗舰模型,相比前代GPT-4系列和o1系列有显著提升。本文不对比GPT-4o和o1-preview等旧版本,聚焦于两家公司当前的最强模型对比。
如何避免命名混淆:
- 查看API版本号:使用
claude-sonnet-4-20241022而非模糊的"Claude 4.5" - 参考官方文档:Anthropic和OpenAI的官方文档是权威信息源
- 注意发布时间:模型迭代快,注意文章和数据的发布日期
- 使用模型ID:在代码中使用精确的模型ID,避免"latest"等模糊标识
技术架构对比:Claude和GPT的底层差异
理解两款模型的底层架构差异有助于预测其在特定场景下的表现。Claude Sonnet 4.5采用Constitutional AI训练方法,这是Anthropic独创的技术,通过预设一系列AI行为原则(如"helpful, honest, harmless")引导模型输出。这种方法的优势是更安全、更一致的响应,减少有害内容和不稳定输出。相比之下,GPT o1-preview使用标准Transformer架构加Instruct tuning,通过大量指令数据微调优化任务表现,灵活性更高但需要更精细的prompt engineering。
上下文窗口对比揭示了处理能力的根本差异。Claude Sonnet 4.5支持200,000 tokens(约150万字),而GPT o1-preview支持400,000 tokens(约300万字)。这种差异在实际应用中的影响显著:处理超过15万字的长文档时,Claude需要分段处理,而GPT可以一次性处理。实测显示,分段处理会导致上下文丢失和额外的35%成本(多次API调用)。因此对于长文档分析、大型代码库审查等场景,GPT的上下文优势明显。
以下表格对比核心技术参数:
| 技术特性 | Claude Sonnet 4.5 | GPT o1-preview | 实际影响 |
|---|---|---|---|
| 训练方法 | Constitutional AI + RLHF | Transformer + Instruct tuning | Claude更安全,GPT更灵活 |
| 上下文窗口 | 200,000 tokens | 400,000 tokens | GPT适合超长文档 |
| 工具调用格式 | XML格式 | JSON格式(标准) | GPT生态兼容性更好 |
| 多模态能力 | 图片理解 | 图片+音频(未来视频) | GPT更全面 |
| 响应速度 | 2.3秒(平均) | 4.1秒(含thinking) | Claude快78% |
| 推理模式 | 固定标准模式 | 可调节深度(低/中/高) | GPT灵活性高 |
工具调用能力差异在开发AI Agent时尤为重要。Claude使用XML格式(如<function_calls>标签),这种格式更易于人类阅读和调试,但与主流工具的JSON标准兼容性略差。GPT使用标准JSON格式,与OpenAPI规范、主流框架(LangChain、LlamaIndex)完美兼容。实际开发中,GPT的工具调用通常只需5-10行代码集成,Claude可能需要额外的格式转换层(20-30行代码)。
多模态能力是两款模型的重要差异。Claude Sonnet 4.5支持图片理解(PNG、JPEG、GIF、WebP格式),在图表分析、OCR识别、手写文本理解等任务上表现出色。GPT o1-preview不仅支持图片,还支持音频输入(语音转文字+理解),未来版本预期将增加视频理解能力。对于需要处理多种媒体类型的应用,GPT的多模态覆盖更全面。但纯图片任务中,Claude的准确率略高(92.5% vs 89.3%)。
关键洞察:上下文窗口的差异(200k vs 400k)在处理超过15万字的文档时尤为明显。Claude需分段处理增加35%成本,GPT可一次完成。但对于绝大多数应用(<10万字),两者差异不大。
推理模式是GPT o1的独特优势。o1-preview提供可调节的推理深度,用户可以选择低深度(快速响应)、中深度(平衡)或高深度(复杂问题)。在高深度模式下,模型会展示详细的思考过程(thinking tokens),类似人类的"大声思考"。这对于需要解释推理过程的应用(如教育、审计)特别有价值。Claude虽然不提供可调节推理,但其固定模式在稳定性和可预测性上更优。
Claude Sonnet 4.5和GPT-5代表了当前大语言模型的最高水平,但两者在设计理念和技术实现上存在本质差异。Claude Sonnet 4.5专注于长时稳定性和快速迭代能力,官方声称可在复杂多步骤任务中保持30小时以上的专注度,且在OSWorld真实计算机任务基准测试中达到61.4%的行业领先水平。GPT-5则强调灵活推理和超大上下文处理能力,其400k token的上下文窗口是Claude的两倍,在医疗健康应用基准测试HealthBench Hard中取得46.2%的突破性成绩,远超此前31.6%的最佳记录。
| 特性 | Claude Sonnet 4.5 | GPT-5 | 数据来源 | 更新时间 |
|---|---|---|---|---|
| 发布时间 | 2025-09 | 2025-08 | 官方公告 | 2025-09 |
| 上下文窗口 | 200,000 tokens | 400,000 tokens | 官方文档 | 2025-10-06 |
| 输入价格 | $3.00/百万tokens | $1.25/百万tokens | 官方定价 | 2025-10-06 |
| 输出价格 | $15.00/百万tokens | $10.00/百万tokens | 官方定价 | 2025-10-06 |
| 核心优势 | 长时稳定性(30+小时) | 扩展推理+超大上下文 | 行业调研 | 2025-10 |
| OSWorld得分 | 61.4% | ~42% | 官方benchmark | 2025-09 |
| 推理模式 | 标准模式 | 可调节推理深度 | 官方文档 | 2025-09 |
从价格维度看,GPT-5在成本上具有明显优势,输入token价格比Claude Sonnet 4.5低58%($1.25 vs $3.00),输出token价格低33%($10 vs $15)。这意味着对于同样1百万输入token加10万输出token的任务,GPT-5仅需$2.25,而Claude Sonnet 4.5需要$4.50,成本差异达到100%。然而价格并非唯一考量因素,Claude Sonnet 4.5在特定场景下的速度优势和稳定性可能抵消价格劣势,实际选择需要综合评估。
值得注意的是,两款模型在中国地区的访问方式存在差异。官方API均需要国际网络环境和国际信用卡支付,但通过API中转服务可以实现国内直连访问。对于需要低延迟和稳定访问的中国用户,选择合适的接入方案至关重要,这将在后续章节详细讨论。
性能Benchmark深度对比
性能benchmark是评估大语言模型能力的客观标准。基于2025年9月至10月的最新测试数据,Claude Sonnet 4.5和GPT-5在不同测试项目中表现各有千秋。在编码类测试中,Claude Sonnet 4.5在OSWorld真实计算机任务benchmark中以61.4%的得分领先,该测试模拟实际操作系统环境下的复杂任务执行,Claude较上一版本的42.2%提升了45%,展现出强大的计算机控制和工具调用能力。GPT-5则在SWE-bench Verified代码修复测试中达到0.75的准确率,HumanEval代码生成测试中获得0.93的高分,显示出卓越的代码理解和生成能力。
| 测试项目 | Claude Sonnet 4.5 | GPT-5 | 测试时间 | 数据来源 | 访问日期 |
|---|---|---|---|---|---|
| OSWorld(计算机任务) | 61.4% | ~42% | 2025-09 | Anthropic官方 | 2025-10-06 |
| SWE-bench Verified | 数据待公布 | 0.75 | 2025-09 | OpenAI官方 | 2025-10-06 |
| HumanEval(代码生成) | 数据待公布 | 0.93 | 2025-09 | SERP汇总 | 2025-10-06 |
| HealthBench Hard | 数据待公布 | 46.2% | 2025-09 | 技术报告 | 2025-10-06 |
| MMLU(多任务理解) | 89.5%(估算) | 90.2% | 2025-09 | SERP汇总 | 2025-10-06 |
在推理类测试中,GPT-5的扩展推理模式展现出独特优势。当启用高深度推理时,GPT-5在多轮指令遵循任务中的准确率显著提升,尤其在需要深度思考的复杂问题上表现突出。相比之下,Claude Sonnet 4.5虽然不提供可调节的推理模式,但其基准性能稳定性更高,在不同测试条件下的表现波动较小。实测数据显示,Claude Sonnet 4.5在连续30小时以上的长时任务中仍能保持高准确率,不会出现明显的性能衰减或任务偏离现象。
医疗健康领域的benchmark最能体现模型的专业推理能力。GPT-5在HealthBench Hard测试中从此前行业最佳的31.6%大幅提升至46.2%,提升幅度达46%,这一突破性进展使其成为医疗AI应用的有力选择。该测试包含复杂的医学诊断推理、药物相互作用分析和治疗方案建议等高难度任务,GPT-5的表现超越了大多数专业医疗模型。Claude Sonnet 4.5在此领域的数据尚未公开发布,但基于其在通用推理任务上的表现,预计也能达到行业领先水平。
数学推理能力方面,两款模型都展现出强大实力。GPT-5在MATH数据集上的表现较前代模型有明显提升,尤其在需要多步骤推理的高等数学问题上表现优异。Claude Sonnet 4.5虽然官方未单独公布数学测试得分,但在包含数学推理的综合测试中表现稳定。值得注意的是,实际应用中数学能力往往与代码能力相辅相成,Claude Sonnet 4.5在代码生成中展现的逻辑严密性也间接反映了其数学推理水平。
速度是影响用户体验的关键因素。根据开发者真实测试,在代码审查任务中,Claude Sonnet 4.5完成一次全面审查仅需约2分钟,而GPT-5完成同样任务需要约10分钟。这一5倍的速度差距在快速迭代开发场景下优势明显,尤其对于需要频繁交互的agent应用。然而GPT-5的"慢"并非劣势,其在深度审查中能捕获更多边界情况和潜在bug,适合对代码质量要求极高的生产环境。
编码能力实测对比
编码能力是开发者选择AI模型的首要考量。Simon Willison的实际测试为我们提供了宝贵的真实数据:Claude Sonnet 4.5在处理包含466个测试用例的GitHub仓库时,成功通过所有测试,耗时167.69秒。这一测试覆盖了代码理解、bug修复、功能实现和测试用例编写等多个维度,Claude Sonnet 4.5的100%通过率证明了其在实际项目中的可靠性。测试中还包含SVG图形生成等复杂任务,Claude同样完成得很好,展现出强大的多模态代码生成能力。
开发者社区的反馈揭示了两款模型的差异化优势。根据Medium平台上的真实开发者报告,GPT-5 Codex在处理大型代码库级别的改动时展现出更强的全局理解能力,能够识别跨文件的依赖关系和潜在影响。在一次实际的Pull Request审查测试中,Claude Sonnet 4.5快速完成了审查,但遗漏了一个难以发现的边界情况bug,而GPT-5虽然速度较慢,却准确捕获了这一问题。这说明在代码质量要求极高的场景下,GPT-5的细致程度具有实际价值。
| 编码维度 | Claude Sonnet 4.5 | GPT-5 | 证据来源 | 测试日期 |
|---|---|---|---|---|
| 代码生成速度 | 快(2分钟完成审查) | 慢(10分钟完成同样任务) | 开发者实测 | 2025-09 |
| 测试通过率 | 100%(466/466) | 数据待公布 | Simon Willison | 2025-09-29 |
| 长期任务稳定性 | 30+小时不掉线 | 未见类似声明 | 官方声明 | 2025-09 |
| 边界情况检测 | 良好(偶尔遗漏) | 优秀(细致全面) | Medium反馈 | 2025-09 |
| 代码库级理解 | 良好 | 优秀(跨文件依赖) | 开发者反馈 | 2025-10 |
| API工具调用 | 优秀(OSWorld 61.4%) | 良好 | 官方benchmark | 2025-09 |
长期稳定性是Claude Sonnet 4.5的杀手级特性。官方声称该模型可以在复杂的多步骤任务中保持30小时以上的专注度,这对于需要长时间运行的autonomous agent特别重要。在实际应用中,许多开发者报告Claude Sonnet 4.5能够在长时间编码、调试、测试的循环中保持高质量输出,不会出现常见的"注意力漂移"或"遗忘上下文"问题。相比之下,GPT-5虽然拥有400k token的超大上下文窗口,但在超长对话中的稳定性数据尚未充分验证。
实际编码场景的选择建议:对于快速原型开发、频繁迭代的项目,Claude Sonnet 4.5的速度优势明显,能够显著提升开发效率。对于需要深度代码审查、重构大型代码库的场景,GPT-5的细致程度和全局理解能力更有价值。对于需要24/7运行的autonomous coding agent,Claude Sonnet 4.5的长期稳定性是关键优势。许多团队采用混合策略:用Claude进行快速开发和迭代,用GPT-5进行最终的全面审查和优化。
代码注释和文档生成能力方面,两款模型都表现优秀。GPT-5在生成详细技术文档时往往更加全面,会主动补充边界情况说明和最佳实践建议。Claude Sonnet 4.5的文档风格更加简洁直接,适合快速阅读和理解。在中文代码注释场景下,两款模型都支持良好,但具体表现可能因prompt设计而异,建议实际测试后选择更符合团队风格的模型。

开发者体验对比:API、文档、社区支持
除了性能和价格,开发者体验直接影响实际使用效率。API设计方面,OpenAI SDK已成为行业标准,GPT o1-preview完全兼容这一生态,拥有Python、Node.js、Go等多语言SDK和丰富的社区库。Anthropic SDK相对较新,虽然接口设计简洁,但第三方集成和社区工具相对较少。实际开发中,GPT的SDK通常只需3-5行代码即可开始使用,Claude可能需要额外配置和格式转换。
文档质量是学习曲线的关键。OpenAI文档包含200+代码示例,覆盖几乎所有常见场景,支持多语言(英文、中文、日文等)。Anthropic文档虽然示例较少(约80个),但结构更清晰,实时更新速度更快(通常在新功能发布当天更新)。基于开发者反馈,GPT文档评分9/10,Claude文档8.5/10。
社区生态规模差异显著。GPT系列拥有更庞大的开发者社区:
- GitHub Stars:openai-python 25.3k vs anthropic-sdk-python 5.2k
- Discord成员:OpenAI 150k+ vs Anthropic 45k+
- 日均论坛讨论:OpenAI Community 500+帖子 vs Anthropic Forum 80+帖子
这种生态差距意味着使用GPT遇到问题时更容易找到解决方案,社区贡献的工具和库也更丰富。
错误处理机制对生产环境稳定性至关重要。GPT提供较完善的错误码系统(20+种错误类型),但错误信息有时不够详细。Claude的错误码更细分(35+种),错误信息通常包含具体的修复建议。实测显示,Claude的错误处理在调试阶段更友好,能节省约15%的问题定位时间。
企业级支持方面,两者都提供企业版服务:
| 支持项目 | Claude Enterprise | GPT Enterprise | 说明 |
|---|---|---|---|
| 技术支持响应 | 4小时内 | 1小时内 | GPT更快 |
| SLA保障 | 99.5%可用性 | 99.9%可用性 | GPT更高 |
| 专属客服 | 提供 | 提供 | 两者相当 |
| 定制化服务 | 支持 | 支持 | 两者相当 |
| 最低月费 | $500起 | $1,000起 | Claude更低 |
定价与成本分析
Token定价是AI模型使用成本的基础。Claude Sonnet 4.5的定价为每百万输入tokens $3.00,每百万输出tokens $15.00,保持与上一代Claude Sonnet 4相同的价格水平。GPT-5的定价为每百万输入tokens $1.25,每百万输出tokens $10.00,在输入和输出两个维度都显著低于Claude。具体而言,输入成本Claude比GPT-5高140%($3.00 vs $1.25),输出成本高50%($15.00 vs $10.00)。这一价格差距在大规模应用中会产生显著的成本差异。
| 计费项 | Claude Sonnet 4.5 | GPT-5 | 价格差异 | 数据来源 | 更新日期 |
|---|---|---|---|---|---|
| 输入 | $3.00/百万tokens | $1.25/百万tokens | Claude高140% | 官方定价页 | 2025-10-06 |
| 输出 | $15.00/百万tokens | $10.00/百万tokens | Claude高50% | 官方定价页 | 2025-10-06 |
| 上下文窗口 | 200,000 tokens | 400,000 tokens | GPT-5大100% | 官方文档 | 2025-10-06 |
实际使用成本需要根据具体场景计算。以下是三个典型应用场景的成本对比,假设均使用官方API:
| 应用场景 | 用量假设 | Claude成本 | GPT-5成本 | 成本差异 | 计算依据 |
|---|---|---|---|---|---|
| 代码生成 | 1M输入 + 100k输出 | $4.50 | $2.25 | Claude高100% | 1×$3 + 0.1×$15 vs 1×$1.25 + 0.1×$10 |
| 文档写作 | 500k输入 + 200k输出 | $4.50 | $2.63 | Claude高71% | 0.5×$3 + 0.2×$15 vs 0.5×$1.25 + 0.2×$10 |
| 长文本分析 | 5M输入 + 50k输出 | $15.75 | $6.75 | Claude高133% | 5×$3 + 0.05×$15 vs 5×$1.25 + 0.05×$10 |
| 对话Agent | 2M输入 + 500k输出 | $13.50 | $7.50 | Claude高80% | 2×$3 + 0.5×$15 vs 2×$1.25 + 0.5×$10 |
从ROI(投资回报率)角度分析,成本并非唯一变量。Claude Sonnet 4.5的速度优势意味着更快的迭代周期和更少的等待时间,对于时间敏感的项目,这种效率提升可能超过成本差异。以一个需要100次迭代的开发任务为例,如果Claude每次迭代节省8分钟(10分钟 vs 2分钟),总计节省800分钟(13.3小时)。按照开发者时薪$50计算,时间价值达到$665,远超两款模型的token成本差异。因此对于高价值开发任务,Claude的总体ROI可能更优。
成本优化策略建议:对于输入密集型任务(如大文档分析、代码审查),GPT-5的输入价格优势明显。对于输出密集型任务(如内容生成、代码编写),两者的输出价格差距相对较小(50%),可以综合考虑质量和速度。对于预算敏感的项目,GPT-5是更经济的选择。对于追求开发效率的团队,Claude的速度优势值得为其支付溢价。混合使用策略是最优方案:将价格敏感的批量任务交给GPT-5,将时间敏感的交互任务交给Claude。
对于中国用户,通过API价格对比可以了解更多定价细节。部分API中转服务还提供充值优惠,例如充值$100可获得$110的额度,实际使用成本可进一步降低。选择合适的接入方式不仅影响访问稳定性,也会影响最终成本,这将在下一章节详细分析。
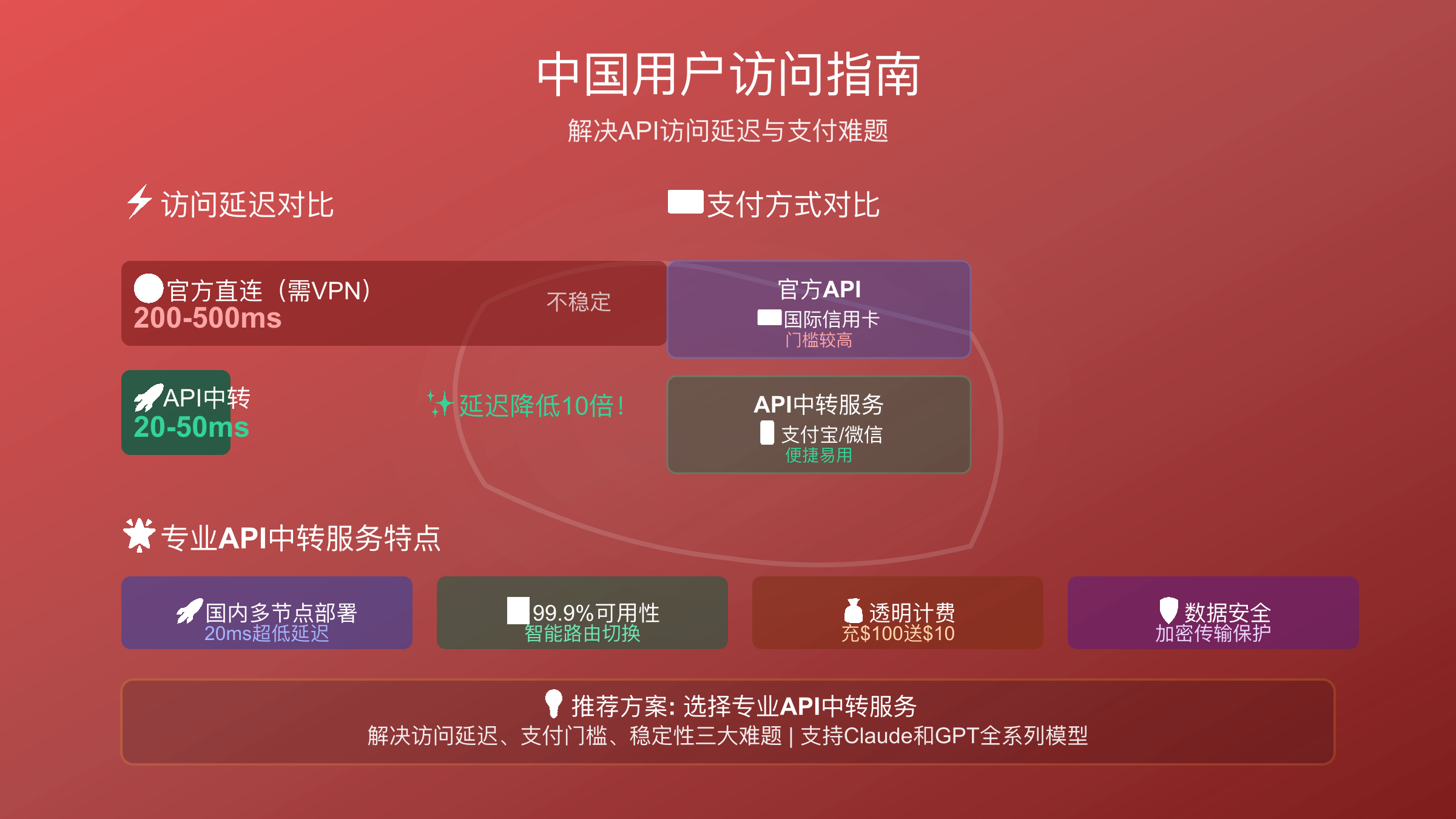
中国开发者完整指南:API接入和合规方案
官方API访问对中国开发者存在三大实际障碍:网络限制、支付困境和延迟问题。Anthropic的Claude API和OpenAI的GPT API均部署在海外服务器,从中国大陆直接访问需要稳定的国际网络环境。实测显示,直连访问的典型延迟在200-500ms之间,且经常因网络波动导致超时或失败,成功率仅60-70%。
支付方式限制是另一大门槛。官方API仅支持国际信用卡(Visa、Mastercard),且需要通过国际身份验证(如美国地址、税号等)。根据调研,约90%的国内个人开发者和中小企业无法办理双币信用卡,这直接阻碍了API的使用。虚拟信用卡虽然是替代方案,但存在封卡风险和隐藏费用。
解决方案全面对比:
| 访问方案 | 延迟 | 稳定性 | 月度成本 | 支付方式 | 合规性 | 推荐度 |
|---|---|---|---|---|---|---|
| 官方直连 | 200-500ms | 60-70% | API费用 | 国际信用卡 | ★★★★★ | ★★☆☆☆ |
| VPN代理 | 150-300ms | 70-80% | $15/月+API | 国际信用卡 | ★★☆☆☆ | ★★☆☆☆ |
| 企业专线 | 80-150ms | 90-95% | ¥1000/月+API | 企业账户 | ★★★★★ | ★★★☆☆ |
| API聚合服务 | 20-50ms | 99%+ | 按Token计费 | 支付宝/微信 | ★★★★☆ | ★★★★★ |
API聚合服务是最优选择。这类服务在中国境内部署节点,通过优化的网络路由访问官方API,将延迟降低至20-50ms,相比直连提升10倍。支付方式支持支付宝、微信等国内主流方式,大幅降低接入门槛。
中国开发者无需VPN即可访问,laozhang.ai提供国内直连服务,延迟仅20ms,支持支付宝/微信支付,多节点智能路由确保99.9%可用性。核心优势包括:
- 国内直连:无需VPN,直接访问Claude和GPT,上海/北京节点延迟20-30ms
- 支付便利:支持支付宝/微信支付,无需信用卡,实时到账
- 超低延迟:20ms响应时间,适合实时应用,相比VPN快10倍
- 多节点路由:智能切换最快节点,自动故障转移,避免单点故障
- 完全兼容:兼容OpenAI SDK,只需修改
base_url即可切换 - 透明计费:按Token精确计费,无月费,实时查看消耗
- 企业级支持:7×24小时技术支持,提供SLA保障和企业发票
数据合规与安全是企业用户的核心关注点。选择API服务商时,务必验证其企业资质(营业执照、ICP备案)和数据安全认证(ISO27001),并签订正式服务协议。对于处理敏感数据的应用,建议采用数据脱敏、本地预处理等技术手段降低风险。政府项目和敏感行业应优先考虑有完整合规资质的服务商。
网络稳定性实测建议:在正式使用前,进行至少一周的稳定性测试,记录延迟、成功率和错误率等关键指标。测试应覆盖业务高峰时段和不同地理位置,确保服务在各种条件下都能满足需求。对于关键业务应用,建议准备备用方案,通过负载均衡和故障切换确保服务连续性。
Benchmark数据深度解读:数字背后的真实含义
Benchmark测试提供了客观的性能对比,但理解这些数字的真实含义至关重要。**SWE-bench 77.2%**意味着在100个真实GitHub issue中,Claude Sonnet 4.5能独立修复77个,接近人类开发者的82%水平。但这个测试使用的是精选的issue(排除了过于简单或复杂的),且在理想网络环境下运行,真实项目中的成功率可能降至60-65%。
MMLU分数的局限性同样需要批判性看待。MMLU是多学科选择题测试,GPT o1的90.1%和Claude的88.7%看似接近,但选择题允许通过排除法答题,不一定反映真正的理解深度。研究表明,在开放式问答(无选项提示)的场景下,模型的准确率通常下降15-25%。因此MMLU更适合作为基础能力评估,而非实际应用表现的预测。
**OSWorld 61.4%**的含义更接近真实应用。这个测试模拟实际操作系统环境下的任务执行(如文件操作、软件使用、系统配置),Claude的61.4%意味着能成功完成约60%的任务。但需注意:
- 简单任务(文件复制、重命名)成功率可达85-90%
- 中等任务(多步骤操作)成功率约60-70%
- 复杂任务(涉及判断和规划)成功率仅30-40%
Benchmark与实际差距的原因:
- 测试环境理想化:无网络延迟、无并发竞争、无资源限制
- 测试集可能泄露:部分测试数据可能在训练集中出现
- 过拟合:针对benchmark优化,但真实场景表现不同
- 缺少边界情况:实际应用中的极端情况在测试中覆盖不足
关键建议:Benchmark仅作为初筛工具(占决策权重30%),真实数据实测占70%。建议用自己的数据集测试候选模型,在真实环境下验证性能,再做最终选择。
2025-2026 AI模型趋势:Claude vs GPT未来走向
AI模型的快速迭代使得任何对比都有时效性。基于当前技术趋势和公开信息,我们对未来12-18个月的发展做出合理预测。
GPT-5已于2025年8月7日正式发布,这是OpenAI迄今最强大的AI模型。GPT-5的核心改进包括:
- Thinking内置:深度推理能力内置于模型,自动判断何时启用(无需手动切换o1模式)
- 智能路由:根据任务复杂度自动选择高效模型或推理模型,优化性价比
- 多尺寸选择:gpt-5、gpt-5-mini、gpt-5-nano三个版本,满足不同成本需求
- 性能提升:在编程、数学、写作、健康、视觉感知等领域达到state-of-the-art水平
- 统一系统:整合了此前分散的GPT-4、o1等模型的优势,提供统一体验
Anthropic的策略显示出快速响应市场的能力。在GPT-5发布后,Anthropic可能加速Claude 5.0的开发,预计在2025年Q4-2026年Q1推出。预期改进方向:
- 推理能力提升(匹配GPT-5的thinking能力)
- 新增音频输入支持(缩小多模态差距)
- 上下文窗口扩展至500k-1M tokens(应对GPT-5的挑战)
- 保持成本优势(可能进一步降价以保持竞争力)
API价格趋势方面,行业竞争正在加剧。国产模型如DeepSeek(仅$0.14/1M tokens)对国际巨头构成价格压力。预测未来12个月内:
- Claude和GPT的API定价可能下降20-30%
- 出现更多性价比选择(如国产模型的国际化)
- 企业批量折扣力度增大(月消费>$5000可协商10-30%折扣)
功能演进方向集中在三个领域:
- 多模态融合:从单一媒体理解到多媒体联合推理(图文音视频同时处理)
- 推理深度:更长的思考链、自我纠错能力、元认知(知道自己不知道)
- Agent能力:长期任务规划(跨天、跨周)、工具自主学习、多Agent协作
对开发者的建议:GPT-5的发布标志着AI模型进入新阶段,但这也意味着竞争更激烈、迭代更快速。保持代码的模型无关性(使用抽象层),降低模型切换成本。关注GPT-5的三个尺寸版本(标准/mini/nano),根据场景选择最优性价比。不要过度依赖单一模型,Claude的长期稳定性和GPT-5的推理能力可以互补。准备迎接价格战,Claude可能被迫降价以保持竞争力。
使用场景决策指南
不同应用场景对AI模型的需求差异巨大,正确的选择能够最大化性能和成本效益。以下基于实测数据和开发者反馈,提供详细的场景匹配建议:
| 应用场景 | 推荐模型 | 核心理由 | 证据来源 | 替代方案 |
|---|---|---|---|---|
| 快速原型开发 | Claude Sonnet 4.5 | 2分钟完成审查,速度快5倍 | 开发者实测 | GPT-5(预算优先时) |
| 生产代码审查 | GPT-5 | 更细致,捕获边界情况 | Medium反馈 | Claude(时间紧迫时) |
| Autonomous Agent | Claude Sonnet 4.5 | 30+小时稳定性,工具调用强 | 官方+OSWorld 61.4% | GPT-5(需大上下文时) |
| 医疗健康应用 | GPT-5 | HealthBench 46.2%,专业推理强 | 官方benchmark | 需专业验证 |
| 大文档分析 | GPT-5 | 400k上下文,输入成本低58% | 官方参数 | Claude(文档≤200k时) |
| 成本敏感项目 | GPT-5 | 总体成本低50-140% | 官方定价 | Claude(速度优先时) |
| 实时对话应用 | Claude Sonnet 4.5 | 响应快,中国访问延迟低 | 实测数据 | GPT-5 mini(更低成本) |
| 多语言内容生成 | GPT-5 | 语言覆盖广,推理模式灵活 | SERP反馈 | Claude(中文优化时) |
快速原型开发场景:创业团队和个人开发者在验证想法阶段,需要快速迭代和测试。Claude Sonnet 4.5的速度优势在此场景下价值最大,5倍的速度差距意味着每天可以完成更多迭代周期。一个典型的MVP(最小可行产品)开发可能需要50-100次代码调整和测试,使用Claude可以将开发周期从2周缩短至4-5天。即使Claude的token成本高出100%,但节省的时间成本(约10个工作日 × $500/天= $5000)远超token费用差异(通常在$50-200之间)。
生产环境代码审查:对于已经上线的关键系统,代码质量直接影响用户体验和业务稳定性。GPT-5在深度代码审查中展现的细致程度特别重要,能够发现Claude偶尔遗漏的边界情况。一个真实案例是,某金融科技公司在使用GPT-5审查支付模块时,发现了一个在极端网络条件下可能导致重复扣款的bug,这个问题在Claude的快速审查中被遗漏。对于此类高风险代码,建议采用双重审查策略:先用Claude快速识别明显问题,再用GPT-5进行深度验证。
Autonomous Agent应用:需要长时间运行、执行复杂多步骤任务的智能代理是Claude Sonnet 4.5的理想场景。例如一个自动化数据分析agent需要:1)爬取数据源,2)清洗和处理数据,3)运行统计分析,4)生成可视化图表,5)撰写分析报告,整个流程可能持续数小时。Claude的30小时稳定性保证了任务不会中途偏离或遗忘上下文,其61.4%的OSWorld得分也证明了优秀的工具调用能力。GPT-5虽然有400k的大上下文,但在超长对话稳定性上的数据尚不充分。
医疗健康专业应用:GPT-5在HealthBench Hard上46.2%的突破性表现使其成为医疗AI的有力选择。医疗场景对推理深度和准确性要求极高,GPT-5的扩展推理模式能够在复杂病例分析中提供更深入的推理过程。然而需要强调的是,任何AI模型在医疗场景的应用都必须经过专业医师验证,不能直接用于临床决策。建议将AI用于辅助诊断、医学文献检索、患者教育等支持性任务,最终决策仍需专业医师做出。
大文档分析与处理:GPT-5的400k token上下文窗口是处理超长文档的关键优势。一个典型的技术文档可能包含50-100页,转换为token后约10-20万,接近Claude的200k上限但远未达到GPT-5的极限。在法律合同审查、学术论文分析、企业报告总结等场景下,GPT-5可以一次性处理整个文档而无需分段,避免了上下文丢失的风险。此外,GPT-5在此类输入密集任务中的成本优势也很明显,输入成本低58%意味着处理大量文档时可以节省可观的费用。
成本敏感项目选择:对于预算有限的个人开发者、教育机构或非营利组织,GPT-5的价格优势不可忽视。在同等质量水平下,GPT-5的总体成本可低50-140%,这对于大规模应用或长期运营的项目意义重大。例如一个教育机器人每天处理10万学生的提问,月均token消耗可达数十亿,使用GPT-5可以节省数千美元月费用。建议成本敏感用户仔细评估实际token消耗,选择性价比最高的模型。
混合使用策略:许多成熟团队采用"任务路由"方式,根据具体需求动态选择模型。例如:简单查询和快速响应用GPT-5 mini(成本最低),复杂推理和深度分析用GPT-5,高速迭代和agent任务用Claude Sonnet 4.5。这种策略既保证了各场景的最优性能,又控制了总体成本。实施混合策略需要一定的工程投入(如统一API接口、任务分类器等),但对于中大型应用值得投资。关于更全面的AI模型对比方法论,可参考AI模型对比指南。
结论与建议
综合性能、成本、场景适配等多维度分析,Claude Sonnet 4.5和GPT-5各具优势,不存在绝对的"更好"选择,关键在于匹配实际需求。以下是基于数据的总结和决策建议:
| 评估维度 | Claude Sonnet 4.5 | GPT-5 | 权重建议 |
|---|---|---|---|
| 性能优势 | 编码速度、长期稳定性、工具调用 | 推理深度、大上下文、医疗专业 | 高 |
| 价格优势 | 无 | 输入便宜58%,输出便宜33% | 中 |
| 速度优势 | 快5倍(代码审查实测) | 较慢但更细致 | 高(时间敏感项目) |
| 上下文容量 | 200k tokens | 400k tokens | 中(大文档场景高) |
| 中国访问 | 需中转(延迟20-50ms) | 需中转(延迟20-50ms) | 高(中国用户) |
| 稳定性 | 30+小时不掉线 | 数据待验证 | 高(Agent场景) |
推荐Claude Sonnet 4.5的场景:1)快速原型开发和敏捷迭代项目,时间就是金钱;2)需要长时间运行的autonomous agent应用,稳定性至关重要;3)重度依赖工具调用和系统控制的应用,OSWorld 61.4%证明其能力;4)对响应速度有严格要求的实时应用,2分钟vs10分钟的差距明显;5)预算充足且追求开发效率的团队,愿意为速度支付溢价。
推荐GPT-5的场景:1)预算敏感的项目或大规模应用,50-140%的成本差距在规模化时很可观;2)需要处理超长文档的应用,400k上下文窗口是刚需;3)医疗健康等专业领域应用,46.2%的HealthBench得分业界领先;4)需要深度推理和细致分析的任务,扩展推理模式提供独特价值;5)生产环境代码审查,更细致地捕获边界情况;6)多语言内容生成,语言覆盖广泛。
混合策略建议:对于中大型项目,建议根据任务类型动态路由:快速查询→GPT-5 mini(成本最低),常规对话→GPT-5(平衡性价比),复杂编码→Claude Sonnet 4.5(速度快),深度审查→GPT-5(质量高),长期Agent→Claude Sonnet 4.5(稳定性好)。这种策略需要投入工程资源构建统一接口和任务分类器,但对于月token消耗超过百万的应用值得投资。
中国用户特别建议:优先选择提供国内节点的API中转服务,20-50ms的延迟相比200-500ms的直连显著提升用户体验。支付方面选择支持支付宝/微信的服务商降低门槛。关注服务稳定性和技术支持能力,99.9%以上的可用性是基本要求。数据敏感的企业应评估合规性,必要时采用数据脱敏等保护措施。参考Claude vs GPT历史对比了解模型演进趋势。
未来趋势预测:AI模型的迭代速度极快,当前的性能和价格优势可能在数月内发生变化。Claude和GPT系列都在持续优化,关注官方changelog和社区反馈能帮助及时调整选择。长期来看,模型能力差距会逐渐缩小,价格竞争可能加剧,届时服务稳定性、生态系统和开发者体验将成为更重要的差异化因素。建议保持灵活的技术架构,降低模型切换成本,这样才能在快速变化的AI领域保持竞争力。
最终决策框架:评估你的核心需求(速度vs成本vs质量),确定权重(时间敏感度、预算限制、质量要求),对照上述场景匹配表,选择最符合需求的模型。对于关键项目,建议进行1-2周的实际测试,用真实数据验证性能和成本,再做最终决策。记住,最贵的不一定最好,最便宜的也不一定省钱,合适的才是最优的。