免费使用GPT/Claude/Gemini全系列AI模型:API中转服务完整接入指南
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
TL;DR — AI模型免费接入核心要点
- 免费起步:通过API中转服务注册即送免费额度,无需国际信用卡,支持支付宝/微信支付
- 全模型覆盖:一个API Key同时接入GPT-5.4、Claude Opus 4.6、Gemini、DeepSeek等200+模型
- 成本优势:中转服务价格通常为官方定价的70%,配合Prompt Caching和智能路由可再降50%以上
- 零迁移成本:完全兼容OpenAI SDK格式,修改base_url即可从官方API无缝切换
对于中国开发者来说,直接使用OpenAI、Anthropic或Google的官方API面临三重门槛:国际信用卡支付要求、网络访问不稳定和英文技术支持效率低。API中转服务的核心价值正是解决这些痛点——通过在国内部署的代理节点转发请求,开发者可以用支付宝充值、享受国内直连的低延迟,同时获得中文技术支持。更重要的是,优质中转平台通常覆盖GPT、Claude、Gemini、DeepSeek等全系列模型,开发者无需分别注册多个服务商账户,一个API Key就能调用所有主流AI模型。
本文将系统介绍如何通过API中转服务免费或低成本使用当前最强大的AI模型,从模型定价对比到具体接入代码,帮助你在30分钟内完成从零到生产的全流程。如果你对Claude API的免费使用方法或API中转服务的详细选型有兴趣,也可以参考我们的专题文章。
主流AI模型最新定价全面对比
在选择API中转服务之前,首先需要了解当前主流AI模型的官方定价格局。AI模型的定价在过去一年经历了剧烈变化——OpenAI的旗舰模型从GPT-4o迭代到了GPT-5.4,Anthropic推出了性价比大幅提升的Claude Opus 4.6和Sonnet 4.6,而DeepSeek V3.2则以极低价格搅动了整个市场。理解这些变化,有助于你做出更精准的模型选择和成本规划。
根据各厂商官方定价页面的最新数据,当前主流AI模型的API价格如下:
| 模型 | 厂商 | 输入(/MTok) | 输出(/MTok) | 上下文 | 核心优势 |
|---|---|---|---|---|---|
| GPT-5.4 | OpenAI | $1.75 | $14.00 | 128K | 最强综合推理 |
| GPT-4o | OpenAI | $2.50 | $10.00 | 128K | 多模态能力 |
| Claude Opus 4.6 | Anthropic | $5.00 | $25.00 | 200K/1M | 深度推理编码 |
| Claude Sonnet 4.6 | Anthropic | $3.00 | $15.00 | 200K/1M | 性价比之王 |
| Claude Haiku 4.5 | Anthropic | $1.00 | $5.00 | 200K | 高速轻量 |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M | 超长上下文 | |
| DeepSeek V3.2 | DeepSeek | $0.28 | $0.42 | 128K | 极致性价比 |
从这张表可以清楚看到,不同模型之间的价格差异巨大——GPT-5.4的输出价格是DeepSeek V3.2的33倍,Claude Opus 4.6更是达到60倍。这意味着在实际应用中,选对模型和接入方式可以带来数量级的成本差异。而通过API中转服务,你不仅可以以官方价格的70%左右使用这些模型,还能在一个平台上灵活切换,根据任务复杂度选择最合适的模型。
值得注意的是,几乎所有厂商都提供了成本优化机制。OpenAI的Batch API提供50%折扣,Anthropic的Prompt Caching将重复内容的输入成本降低90%,DeepSeek的自动缓存命中价格仅为标准价的十分之一。这些优化手段在中转服务中同样适用,开发者可以叠加"中转折扣+官方优化"实现综合成本最小化。
从应用场景的角度来看,不同模型有着各自明确的定位。GPT-5.4凭借最新的训练数据和强大的综合推理能力,在需要创意思维、复杂分析和高质量长文本生成的任务中表现最为出色,适合作为"关键任务"的首选模型。Claude Opus 4.6则是当前最强的编码和深度推理模型之一,其128K Token的最大输出长度和自适应思考能力让它在代码审查、架构设计和技术文档生成等场景中无可替代。Claude Sonnet 4.6是大多数开发者的"日常主力"——以Opus 40%的成本提供80%以上的能力水平,在编码、写作、数据分析等常规任务中的性价比最高。DeepSeek V3.2则是成本敏感场景的不二之选,以不到Sonnet十分之一的价格覆盖了大部分基础编程和文本处理需求。
选择模型时还需要考虑上下文窗口这一关键参数。Gemini 2.5 Pro拥有高达1M Token的上下文窗口,非常适合需要一次性处理大量文档的场景(如整个代码库分析或长篇论文审阅)。Claude Opus 4.6和Sonnet 4.5也支持1M上下文(beta阶段,超200K有长上下文溢价)。GPT系列和DeepSeek的128K上下文对于大多数应用场景已经足够——128K Token大约相当于10万字中文或40万字英文。
注册与免费额度获取教程
通过API中转服务接入AI模型的第一步是注册账户并获取免费额度。以laozhang.ai为例,整个流程只需要几分钟,注册完成后即可获得免费试用额度用于功能验证。
注册流程非常简单:访问平台注册页面,使用邮箱或手机号完成注册,无需提供国际信用卡或进行复杂的身份验证。注册成功后,在个人中心的API管理页面可以创建API Key——这个Key是后续所有API调用的身份凭证,需要妥善保管。平台支持创建多个API Key并设置独立的使用限额,方便开发者按项目或团队成员分别管理用量和成本。
充值方面,中转平台通常支持支付宝、微信支付等国内主流支付方式,最低充值门槛很低(通常10元起),按实际API调用量计费。相比OpenAI和Anthropic要求国际信用卡充值且最低$5起步,这对个人开发者和学生群体来说友好得多。部分平台还提供充值优惠活动,比如充$100送$10等,可以关注官方公告获取最新优惠信息。
获取API Key后,你需要记录两个关键信息用于后续配置:API Key(以sk-开头的密钥字符串)和Base URL(中转服务的API端点地址,如https://api.laozhang.ai/v1)。有了这两个参数,就可以在任何支持OpenAI SDK格式的平台和应用中使用全系列AI模型。
在使用管理方面,建议从一开始就养成良好的习惯。在平台控制台中设置余额预警(如低于$1时邮件通知),避免在不知情的情况下耗尽额度导致服务中断。同时开启API调用日志功能,可以清楚地看到每次请求使用了哪个模型、消耗了多少Token、花费了多少金额——这些数据对后续的成本优化至关重要。如果你的团队有多个开发者共同使用,建议为每人创建独立的API Key并设置单独的使用限额,这样既便于追踪各自的用量,也能防止单个成员的误操作消耗过多额度。
多平台接入实战指南
API中转服务的一大优势是完全兼容OpenAI SDK的请求格式,这意味着几乎所有支持自定义API的开发工具和客户端都可以无缝接入。以下分别介绍Python SDK、cURL命令行和Cursor IDE三种最常用的接入方式。
Python SDK接入(推荐)
使用OpenAI官方Python SDK是最推荐的接入方式,代码简洁且功能完整。注意当前版本的SDK使用client.chat.completions.create方法(旧版的openai.ChatCompletion.create已弃用)。
pythonfrom openai import OpenAI
# 初始化客户端,指向中转服务
client = OpenAI(
api_key="sk-your-api-key-here",
base_url="https://api.laozhang.ai/v1"
)
# 调用GPT-5.4模型
response = client.chat.completions.create(
model="gpt-5.4-0314",
messages=[
{"role": "system", "content": "你是一位专业的技术顾问。"},
{"role": "user", "content": "请解释微服务架构的核心设计原则。"}
],
max_tokens=2048,
temperature=0.7
)
print(response.choices[0].message.content)
print(f"Token消耗:输入{response.usage.prompt_tokens},输出{response.usage.completion_tokens}")
通过修改model参数,可以在同一个客户端实例中切换不同厂商的模型。例如将model改为claude-sonnet-4-6即可调用Claude Sonnet 4.6,改为deepseek-chat即可调用DeepSeek V3.2——无需修改任何其他代码。
python# 同一个客户端,切换不同模型
# Claude Sonnet 4.6
claude_response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "用Go实现一个并发安全的LRU缓存"}],
max_tokens=4096
)
# DeepSeek V3.2(成本最低)
deepseek_response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "写一个Python装饰器实现函数重试"}],
max_tokens=1024
)
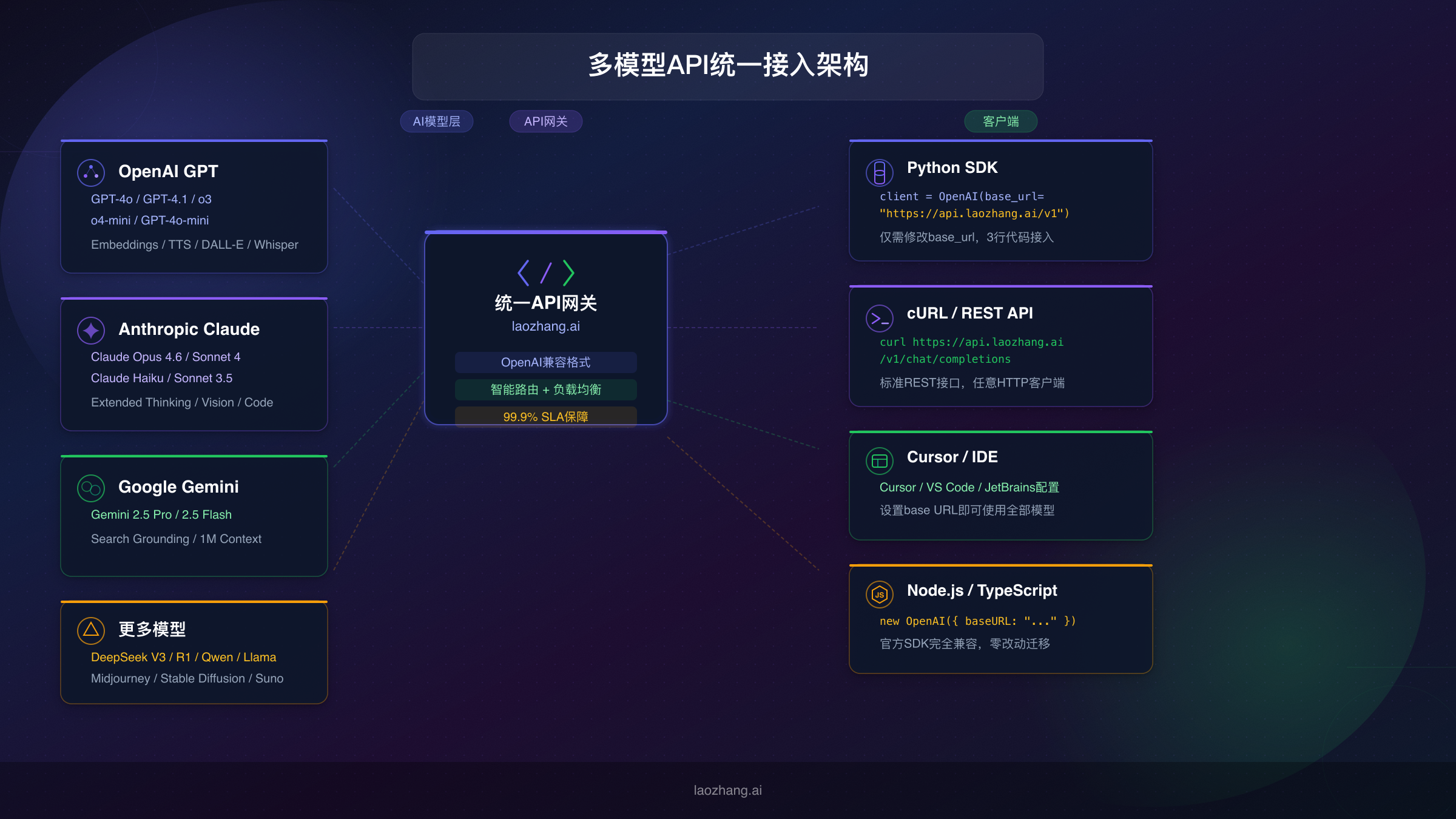
cURL命令行接入
对于快速测试或在Shell脚本中集成AI能力,cURL是最直接的方式。
bash# 调用Claude Sonnet 4.6
curl -X POST "https://api.laozhang.ai/v1/chat/completions" \
-H "Authorization: Bearer sk-your-api-key-here" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"messages": [{"role": "user", "content": "解释RESTful API设计的最佳实践"}],
"max_tokens": 2048,
"stream": true
}' --no-buffer
Cursor IDE接入
在Cursor中使用中转服务接入多模型,可以同时获得GPT、Claude和DeepSeek的能力。打开Settings > Models > Add Model,在Base URL字段填入中转服务的API端点地址,API Key填入你的密钥,然后在Model Name中填写需要的模型名称。你可以添加多个模型条目(如claude-sonnet-4-6、deepseek-chat、gpt-5.4-0314),在Chat面板中根据任务需要随时切换。
流式输出与异步调用
在生产环境中,建议使用流式输出(Streaming)来改善用户体验——这样可以让AI的回答像打字一样逐字显示,而不是等待完整响应后才呈现。流式模式还有一个实用的好处:它可以降低请求超时的概率,因为服务器会在生成第一个Token后立即开始返回数据,而不是等待整个响应生成完毕。
python# 流式输出示例
stream = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "详细解释Docker容器网络模型"}],
max_tokens=4096,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
对于需要处理大量请求的场景,Python的asyncio配合httpx可以实现高效的异步并发调用。以下是一个实用的异步批量处理示例,支持并发控制和错误重试:
pythonimport asyncio
from openai import AsyncOpenAI
async_client = AsyncOpenAI(
api_key="sk-your-api-key-here",
base_url="https://api.laozhang.ai/v1"
)
async def process_query(query: str, semaphore: asyncio.Semaphore):
"""带并发控制的异步请求"""
async with semaphore:
response = await async_client.chat.completions.create(
model="deepseek-chat", # 批量任务用低成本模型
messages=[{"role": "user", "content": query}],
max_tokens=512
)
return response.choices[0].message.content
async def batch_process(queries: list, max_concurrent: int = 10):
"""批量处理多个查询"""
semaphore = asyncio.Semaphore(max_concurrent)
tasks = [process_query(q, semaphore) for q in queries]
return await asyncio.gather(*tasks, return_exceptions=True)
# 使用示例:同时处理100个查询,最多10个并发
queries = [f"用一句话解释{topic}" for topic in ["TCP三次握手", "B+树", "CAP定理"]]
results = asyncio.run(batch_process(queries))
这种异步批量处理方式特别适合数据标注、内容批量生成、批量翻译等场景。配合DeepSeek V3.2的低价模型,100个请求的成本通常不到$0.01。
Node.js/TypeScript接入
对于前端和全栈开发者,使用OpenAI的Node.js SDK同样简单。以下是TypeScript的接入示例,展示了如何在一个Express应用中集成AI聊天功能:
typescriptimport OpenAI from 'openai';
import express from 'express';
const client = new OpenAI({
apiKey: process.env.API_KEY,
baseURL: 'https://api.laozhang.ai/v1',
});
const app = express();
app.use(express.json());
app.post('/api/chat', async (req, res) => {
const { message, model = 'claude-sonnet-4-6' } = req.body;
// 设置SSE流式响应
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
const stream = await client.chat.completions.create({
model,
messages: [
{ role: 'system', content: '你是一位专业的技术助手。' },
{ role: 'user', content: message },
],
max_tokens: 4096,
stream: true,
});
for await (const chunk of stream) {
const content = chunk.choices[0]?.delta?.content;
if (content) {
res.write(`data: ${JSON.stringify({ content })}\n\n`);
}
}
res.write('data: [DONE]\n\n');
res.end();
});
app.listen(3000, () => console.log('AI Chat服务已启动'));
这段代码实现了一个完整的SSE流式AI聊天后端,前端可以通过EventSource或fetch API接收实时响应。将model参数暴露为请求参数,让前端可以动态切换GPT、Claude或DeepSeek等不同模型。在生产环境中,建议添加请求频率限制、身份验证和Token用量监控等中间件。
多模型对比测试脚本
在正式选定主力模型之前,建议用同一组测试任务分别调用多个模型,对比输出质量和响应速度。以下脚本可以自动完成这个对比过程:
pythonimport time
from openai import OpenAI
client = OpenAI(
api_key="sk-your-api-key",
base_url="https://api.laozhang.ai/v1"
)
models = [
("DeepSeek V3.2", "deepseek-chat"),
("Claude Sonnet 4.6", "claude-sonnet-4-6"),
("GPT-5.4", "gpt-5.4-0314"),
]
test_prompt = "用Python实现一个线程安全的单例模式,并编写测试用例。"
for name, model_id in models:
start = time.time()
response = client.chat.completions.create(
model=model_id,
messages=[{"role": "user", "content": test_prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
content = response.choices[0].message.content
print(f"\n{'='*50}")
print(f"模型: {name} ({model_id})")
print(f"耗时: {elapsed:.1f}秒 | Token: {tokens}")
print(f"输出预览: {content[:200]}...")
通过这个脚本,你可以在几分钟内直观对比不同模型在同一任务上的输出质量、响应速度和Token消耗。建议准备5-10个覆盖不同场景的测试提示(编码、写作、分析、翻译等),全面评估后再做出模型选择决策。
成本优化高级策略
获得免费额度后,如何最大化每一分钱的使用价值?这个问题对于长期使用AI API的开发者来说至关重要。根据经验,一个未经优化的AI应用与精心优化后的版本,在同等功能下的API成本可以相差5-10倍。以下几个经过实践验证的策略,可以帮助你系统性地将AI API的实际使用成本压缩到最低水平。
策略一:智能模型路由。根据任务复杂度自动选择最经济的模型是成本优化的第一步。简单的文本格式化、分类和摘要任务交给DeepSeek V3.2($0.28/$0.42/MTok),常规的编码、写作和分析任务使用Claude Sonnet 4.6($3/$15/MTok),仅在需要最强推理能力时才调用GPT-5.4或Claude Opus 4.6。在实际使用中,70%以上的日常任务可以由低成本模型胜任,仅靠这一策略就能降低50-60%的总支出。
策略二:充分利用Prompt Caching。当你的应用场景包含重复的系统提示、知识库或长文档上下文时,Prompt Caching可以将这部分输入Token的成本降低90%。以Anthropic的Claude为例,缓存读取价格仅为标准输入价格的十分之一(据Anthropic官方定价页面)。在中转服务中,这些官方优化机制同样适用——你只需要在API请求中正确配置缓存参数,就能自动享受折扣。
策略三:善用Batch API。对于不需要实时响应的任务——如批量内容生成、数据标注、邮件模板生成等——使用Batch API可以获得50%的折扣。OpenAI和Anthropic都提供了Batch处理接口,提交任务后通常在24小时内返回结果。将非紧急任务集中到Batch处理,是降低成本的又一有效手段。
策略四:控制输出长度。在API请求中合理设置max_tokens参数可以避免不必要的输出成本。如果你只需要一个简短的答案,将max_tokens设为256或512而不是默认的4096,可以显著减少输出Token的消耗。同时,在system prompt中明确要求"简洁回答"也能引导模型生成更精练的输出。
成本优化效果参考
以月均10000次API请求为例,全部使用Claude Sonnet 4.6标准调用的成本约为$150/月。通过组合应用上述四项策略(70%任务用DeepSeek + Prompt Caching + 部分Batch + 控制输出长度),实际成本可压缩至$30-50/月,综合节省60-80%。

实际应用场景与效果展示
了解了接入方法和成本优化策略之后,让我们看看AI API在几个典型场景中的实际应用效果,帮助你判断哪些场景值得优先投入。
场景一:日常编程辅助。对于开发者来说,AI API最直接的价值是提升编码效率。通过中转服务接入Claude Sonnet 4.6或DeepSeek V3.2,你可以在VS Code、Cursor等IDE中获得智能代码补全、函数生成、单元测试编写和代码审查等能力。实际测试显示,AI辅助编码可以将常规开发任务的完成速度提升30-50%,尤其是在编写重复性代码、处理标准化接口和生成测试用例等场景中效果显著。按照日均50次API调用、每次平均800输入+400输出Token计算,使用DeepSeek V3.2的月成本不到$1,使用Claude Sonnet 4.6也仅约$5。
场景二:内容创作与翻译。AI模型在文章撰写、营销文案、产品描述和多语言翻译等内容生产场景中同样表现出色。GPT-5.4在创意写作和长文本生成方面的质量最高,Claude Sonnet 4.6在结构化内容和技术文档写作上更为擅长,而DeepSeek V3.2则可以胜任大部分基础翻译和摘要任务。对于月产出数万字内容的创作团队,通过混合模型方案可以将AI辅助成本控制在每月$20-50之间,同时获得远超人工效率的产出速度。
场景三:数据分析与处理。将结构化或半结构化数据通过API发送给AI模型进行分析、分类、提取和总结,是企业级应用中越来越常见的模式。例如,电商平台可以用AI批量生成商品描述、客服系统可以用AI自动分类和回复工单、金融行业可以用AI辅助研报分析和风险评估。这类场景通常涉及大量小型请求,非常适合使用DeepSeek V3.2的低价模型配合异步批量处理来实现成本最优。
总结与快速开始
API中转服务为中国开发者提供了一条低门槛、低成本、高灵活性的AI模型接入路径。通过本文介绍的方法,你可以在30分钟内完成从注册到调用的全流程,用免费额度充分验证各模型的能力表现,然后根据实际需求选择最适合的长期方案。
核心要点回顾:选择覆盖多模型的中转平台(一个Key用所有模型)、使用现代OpenAI SDK格式编写代码(兼容所有模型)、根据任务复杂度智能切换模型(控制成本)、善用Prompt Caching和Batch API(叠加折扣)。对于刚入门的开发者,建议从Claude Sonnet 4.6作为主力模型开始——它在性价比和综合能力上的平衡是当前市场中最优的选择之一。
从实际行动层面来看,建议按以下顺序推进:第一步用10分钟完成中转平台注册和API Key获取,第二步用本文提供的Python代码示例验证接入是否成功,第三步分别测试2-3个不同模型在你实际业务场景中的表现,第四步根据测试结果确定模型分配策略并设置成本预警。整个过程不需要任何特殊技术背景,Python初学者也可以在半小时内完成全流程。
常见问题
API中转服务和直接使用官方API有什么区别?
API中转服务本质上是官方API的代理层,它将你的请求转发到各厂商的官方服务器并返回结果。在功能上,中转服务完全兼容官方API的所有能力(Chat、Streaming、Function Calling、Vision等),开发者只需修改base_url和api_key两个参数即可从官方API无缝迁移。中转服务的核心附加价值在于:支持国内支付方式(支付宝/微信)、提供国内直连低延迟访问、一个Key覆盖多厂商模型、以及中文技术支持。在定价方面,优质中转服务通常为官方价格的70%左右。
免费额度用完后的费用是多少?
不同中转平台的定价策略有所不同,但通常以官方价格的70-80%为基准。以Claude Sonnet 4.6为例,官方价格为$3/$15每百万Token,中转服务的实际使用价格通常在$2-2.5/$10-12之间。充值支持支付宝和微信支付,最低充值门槛通常在10元左右,按实际调用量计费,没有月费或包年强制要求。对于个人开发者来说,每月$10-20的预算已经可以覆盖相当可观的API使用量。
数据安全性如何保障?
优质中转服务通常承诺不存储用户的对话内容,请求处理完成后立即清除所有中间数据。传输层采用TLS 1.3加密,API Key采用加密存储并支持定期轮换。在选择中转服务商时,建议优先考虑具有完整安全认证(如等保三级)和透明安全政策的平台。作为最佳实践,仍然建议不要通过API传输高度敏感的个人隐私信息或核心商业机密。
可以在哪些客户端和工具中使用?
由于中转服务完全兼容OpenAI SDK格式,几乎所有支持自定义API的工具都可以接入。常用的开发类工具包括Cursor IDE、VS Code(通过Continue等插件)、JetBrains IDE等;对话类客户端包括ChatBox、BotGem、LobeChat等;移动端App包括各类支持自定义API的ChatGPT替代客户端。在你自己的应用中集成也非常简单,Python、Node.js、Go等主流语言都有成熟的OpenAI SDK库可以直接使用。
如何选择最适合自己的AI模型?
模型选择取决于你的具体使用场景和预算。如果你的主要需求是日常编码和内容创作,Claude Sonnet 4.6是当前综合性价比最高的选择($3/$15/MTok)。需要最强推理和分析能力时,GPT-5.4($1.75/$14/MTok)或Claude Opus 4.6($5/$25/MTok)是首选。对于大量简单任务(分类、格式化、摘要),DeepSeek V3.2以$0.28/$0.42/MTok的极低价格提供了90%以上的质量水准。建议先用免费额度分别测试几个模型在你实际任务上的表现,再根据质量和成本的平衡做出长期选择。
中转服务支持Function Calling和Tool Use吗?
是的,优质的API中转服务完全支持Function Calling(函数调用)和Tool Use(工具使用)能力。这意味着你可以通过中转服务构建具备外部工具调用能力的AI Agent——比如让AI模型调用天气查询API、执行数据库查询或触发自动化工作流。中转服务在转发请求时会完整保留所有参数(包括tools定义和tool_choice设置),模型返回的tool_use响应也会原样传递给客户端。对于需要构建复杂AI应用的开发者来说,这一点非常重要,因为它确保了中转服务不会成为功能上的瓶颈。
如何处理API调用中的错误和限流?
在使用API中转服务时,最常见的错误是429(限流)和超时。处理429错误的最佳实践是实现指数退避重试——第一次等待1秒、第二次等待2秒、第三次等待4秒,以此类推。大多数中转平台在返回429时会附带Retry-After头部,告诉你应该等待多久后重试。对于超时问题,建议启用流式输出模式(stream=true),因为流式模式在生成第一个Token后就开始返回数据,大幅降低了超时概率。如果错误持续出现,检查你的API Key是否有效、余额是否充足,并联系平台技术支持获取帮助。
本指南基于各厂商官方最新定价数据整理,持续更新中。