Gemini API RESOURCE_EXHAUSTED错误完整解决方案:2025年12月最新指南
深入解析Gemini API 429 RESOURCE_EXHAUSTED错误的根本原因,提供指数退避重试、配额优化、模型切换等7种经过验证的解决方案,包含Python/JavaScript生产级代码示例
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
当你满怀期待地调用Gemini API,却突然收到一个冰冷的错误信息:"429 RESOURCE_EXHAUSTED: Resource has been exhausted (e.g. check quota)"——这是许多开发者在使用Google Gemini API时都会遇到的挫折时刻。这个错误不仅中断了你的开发流程,还可能让你的生产应用陷入瘫痪状态。
这个问题在2025年12月变得尤为严重。Google在12月7日对Gemini API的速率限制进行了重大调整,免费版的每分钟请求数从15次直接砍到了5次,降幅高达67%。许多原本运行正常的应用突然开始频繁报错,开发者社区一片哗然。更令人困惑的是,部分用户反馈即使配额显示为0%使用,仍然会收到429错误,这种"幽灵429"现象让问题诊断变得更加复杂。
本文将从根本原因分析出发,带你深入理解Gemini API的四维度速率限制机制,然后提供从5分钟快速修复到生产级架构优化的完整解决方案。无论你是刚接触Gemini API的新手,还是正在为生产环境寻找稳定方案的资深开发者,都能在这里找到适合自己的解决路径。我们还会特别关注中国开发者面临的独特挑战,提供切实可行的本地化方案。

四维度速率限制机制深度解析
要彻底解决RESOURCE_EXHAUSTED错误,首先需要理解Google为Gemini API设置的四维度速率限制体系。这套机制的设计目的是确保资源在所有用户之间公平分配,防止任何单一用户过度占用服务器资源。每个维度都独立追踪,只要触发其中任何一个限制,你的请求就会被拒绝并返回429错误。
RPM(每分钟请求数) 是最容易触发的限制维度。它统计的是你在一分钟内发送的API请求总数,与每个请求的内容大小无关。对于免费版用户来说,Gemini 2.5 Pro模型的RPM限制仅为5次,这意味着你平均每12秒才能发送一个请求。如果你的应用在短时间内发起了多个并发请求,很容易就会触碰这个天花板。当你观察到错误呈现"突发-恢复-再突发"的模式时,通常意味着RPM是罪魁祸首。
TPM(每分钟Token数) 则关注的是请求和响应的内容规模。这个维度统计输入Token和输出Token的总和。免费版允许每分钟25万个Token,看起来很充裕,但如果你频繁发送长篇文档进行分析,或者使用系统提示词构建复杂的对话上下文,Token消耗速度会超出预期。一个包含完整代码库的请求可能一次就消耗数万Token,几个这样的请求就足以触发TPM限制。
RPD(每日请求数) 设置了24小时内的请求上限。免费版Gemini 2.5 Pro的RPD限制为100次,这是2025年12月调整后的新数值,相比之前的500次下降了80%。如果你在开发过程中频繁测试,或者你的应用有稳定的日常调用量,很容易在一天结束前就耗尽配额。RPD限制在太平洋时间午夜重置,因此你可能会注意到错误在每天的某个固定时间点突然消失。
| 限制维度 | 含义 | 免费版限制 | 常见触发场景 |
|---|---|---|---|
| RPM | 每分钟请求数 | 5次 | 并发请求、轮询调用 |
| TPM | 每分钟Token数 | 250,000 | 长文档分析、大上下文 |
| RPD | 每日请求数 | 100次 | 持续开发测试、日常应用 |
| IPM | 每分钟图片数 | 0(免费版不支持) | 图像生成请求 |
IPM(每分钟图片数) 是专门针对Imagen等图像生成模型的限制。免费版用户无法使用图像生成功能,因此这个维度对他们不适用。对于付费版用户,Tier 1允许每分钟生成10张图片。值得注意的是,使用Gemini 2.5 Flash的原生图像生成功能时,这个限制也会生效。
Google采用了令牌桶(Token Bucket) 算法来执行这些限制。在2025年12月的更新之前,限制的执行相对宽松,偶尔超出阈值的请求可能仍然会被接受。但现在,每个维度都有独立的追踪机制,一旦任何维度达到上限,后续请求会立即被拒绝。这种"硬限制"模式使得应用需要更加精确地管理API调用频率。
诊断是哪个维度触发了错误是解决问题的第一步。最直接的方法是登录Google AI Studio查看配额使用统计。控制台会显示各个维度的实时消耗情况,帮助你快速定位瓶颈。另外,错误响应的详细信息中有时也会包含被触发的具体限制类型,仔细阅读完整的错误消息往往能提供有价值的线索。

免费版与付费版速率限制完整对比
理解不同层级之间的限制差异,是做出正确技术决策的基础。Google为Gemini API设置了四个层级:免费版(Free Tier)以及三个付费层级(Tier 1、Tier 2、Tier 3)。层级越高,享受的配额越宽裕,但同时也需要满足相应的资格条件。
免费版的限制在2025年12月7日经历了大幅收紧。以Gemini 2.5 Pro为例,每分钟请求数从原来的10-15次降至5次,每日请求数从500次降至100次。这意味着免费版现在更适合用于学习和原型验证,而非任何有实际用户的应用场景。值得注意的是,免费版仅对符合条件的国家和地区开放,中国大陆不在支持列表中。
| 模型 | 层级 | RPM | TPM | RPD | 升级条件 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | Free | 5 | 250K | 100 | - |
| Gemini 2.5 Pro | Tier 1 | 150 | 2M | 10,000 | 完成付费账户设置 |
| Gemini 2.5 Pro | Tier 2 | 1,000 | 8M | 无限制 | 30天+$250消费 |
| Gemini 2.5 Pro | Tier 3 | 2,000 | 16M | 无限制 | 30天+$1,000消费 |
| Gemini 2.5 Flash | Free | 15 | 1M | 500 | - |
| Gemini 2.5 Flash | Tier 1 | 1,000 | 4M | 无限制 | 完成付费账户设置 |
从表格中可以看出,Gemini 2.5 Flash在各个层级都比Pro版本拥有更宽松的限制。Flash模型的RPM是Pro的数倍,这使得它成为需要频繁调用API场景的理想选择。如果你的应用对响应质量要求不是极致严苛,切换到Flash模型是最简单的扩容方式之一。
升级到Tier 1需要完成Google Cloud的付费账户设置,包括绑定有效的支付方式。一旦升级成功,RPM立即从5提升到150,增幅达30倍。对于大多数中小型应用来说,Tier 1的配额已经足够应对日常需求。升级路径可以在AI Studio的API密钥页面找到,点击"升级"按钮即可开始流程。
Tier 2和Tier 3需要满足时间和消费的双重条件。账户需要存在至少30天,同时在这期间产生一定金额的API调用费用。这些高级层级主要面向企业级用户,提供几乎无限制的调用能力。值得一提的是,即使达到了Tier 3,某些特殊限制仍然存在,比如单个请求的最大Token数和上下文窗口大小仍受模型本身的限制。
2025年12月变化要点:Google于12月7日调整了免费版和Tier 1的配额。免费版降幅显著(Pro模型RPD从500降至100),Tier 1保持相对稳定。这次调整并未大规模预告,导致许多开发者的应用突然出现故障。如果你的应用在12月初开始频繁报错,这很可能是原因。
如果你需要临时提高配额而不想升级层级,可以尝试申请配额增加。Google会根据使用场景和项目规模审核申请,但不保证一定会批准。对于有紧急需求的项目,升级层级通常是更可靠的选择。
快速修复方案:5分钟解决429错误
当你的应用突然开始报告RESOURCE_EXHAUSTED错误时,首要任务是尽快恢复服务。以下三种方案可以在几分钟内实施,帮助你快速脱离困境。这些方案按照实施复杂度从低到高排列,你可以根据具体情况选择最适合的一种,或者组合使用以获得最佳效果。
指数退避重试 被Google官方推荐为处理429错误的"黄金标准"。这种策略的核心思想是:当请求失败时,不要立即重试,而是等待一段时间后再尝试。如果再次失败,等待时间翻倍。通过这种方式,应用可以优雅地处理临时的限流情况,同时避免对API造成更大压力。下面是一个使用Python tenacity库的生产级实现:
pythonfrom tenacity import retry, wait_random_exponential, stop_after_attempt
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
@retry(
wait=wait_random_exponential(multiplier=1, max=60),
stop=stop_after_attempt(5)
)
def call_gemini_with_retry(prompt: str, model_name: str = "gemini-1.5-flash"):
"""
带自动重试的Gemini API调用
- 指数退避:等待1秒、2秒、4秒...最长60秒
- 随机抖动:防止多个客户端同时重试
- 最多重试5次后放弃
"""
model = genai.GenerativeModel(model_name)
response = model.generate_content(prompt)
return response.text
# 使用示例
try:
result = call_gemini_with_retry("解释量子计算的基本原理")
print(result)
except Exception as e:
print(f"重试耗尽后仍然失败: {e}")
这段代码中的wait_random_exponential函数实现了带随机抖动的指数退避。抖动(Jitter)的作用是在基本等待时间上添加随机变化,防止多个客户端在同一时刻同时重试,从而导致新的限流高峰。根据测试数据,添加重试逻辑后,原本只有20%成功率的请求可以达到接近100%的成功率,代价是响应延迟的增加。
对于JavaScript/Node.js开发者,可以使用p-retry库实现类似的效果:
javascriptimport pRetry from 'p-retry';
import { GoogleGenerativeAI } from '@google/generative-ai';
const genAI = new GoogleGenerativeAI('YOUR_API_KEY');
async function callGeminiWithRetry(prompt) {
return pRetry(async () => {
const model = genAI.getGenerativeModel({ model: 'gemini-1.5-flash' });
const result = await model.generateContent(prompt);
return result.response.text();
}, {
retries: 5,
minTimeout: 1000,
maxTimeout: 60000,
factor: 2,
randomize: true
});
}
切换到Flash模型 是另一个立竿见影的方案。如前文所述,Gemini 2.5 Flash的速率限制比Pro版本宽松得多。对于免费版用户,Flash的RPM是15而Pro仅有5;对于Tier 1用户,差距更是达到1000对150。如果你的应用场景对响应质量的要求不是极致严苛,将模型参数从gemini-2.5-pro改为gemini-2.5-flash可能就足以解决问题。Flash模型在大多数通用任务上的表现已经相当出色,而且响应速度更快、成本更低。
添加请求间隔 是最简单的修复方式。如果你的应用是批量处理场景,在每个请求之间添加固定的延迟可以有效避免触发RPM限制。对于免费版用户,每12秒发送一个请求可以确保不触发5 RPM的限制。虽然这会显著降低处理速度,但对于非实时场景来说是完全可接受的。
pythonimport time
def batch_process_with_delay(prompts, delay_seconds=12):
"""批量处理时添加间隔延迟"""
results = []
for i, prompt in enumerate(prompts):
if i > 0:
time.sleep(delay_seconds)
result = call_gemini(prompt)
results.append(result)
return results
选择哪种方案取决于你的具体需求。如果是生产环境的实时应用,指数退避重试是最推荐的选择,因为它能在保持响应性的同时自动处理临时限流。如果是批处理场景且对速度不敏感,简单的请求间隔就足够了。如果问题持续存在且上述方案效果有限,考虑切换模型或升级层级可能是更根本的解决之道。
生产级优化策略:从根本上减少限流风险
快速修复方案可以帮助你渡过眼前的危机,但要构建一个稳定可靠的生产系统,需要从架构层面进行更深入的优化。以下策略经过实际项目验证,可以将限流风险降低80%以上,同时提升整体系统性能。
请求批处理 是减少RPM消耗的最有效手段。与其发送10个独立请求,不如将它们合并成一个请求让模型一次性处理。Gemini API支持在单个请求中传入多个内容片段,模型可以同时生成多个响应。这种方式在不改变业务逻辑的前提下,可以将RPM消耗降低到原来的十分之一甚至更低。实现批处理时需要注意Token限制,确保合并后的请求不会超过TPM阈值。
pythondef batch_prompts(prompts, batch_size=5):
"""将多个提示词合并为批处理请求"""
combined_prompt = "请依次回答以下问题,用数字标记每个回答:\n\n"
for i, prompt in enumerate(prompts[:batch_size], 1):
combined_prompt += f"{i}. {prompt}\n"
return combined_prompt
# 原本需要5个请求,现在只需要1个
result = call_gemini_with_retry(batch_prompts(user_questions))
智能缓存 可以完全消除重复请求的API调用。如果你的应用中存在相同或相似的查询,将结果缓存起来可以显著降低API使用量。缓存策略可以基于精确匹配(相同提示词返回缓存结果)或语义相似度(相似提示词返回缓存结果)。对于后者,可以使用嵌入向量计算相似度来判断是否命中缓存。
pythonimport hashlib
from functools import lru_cache
@lru_cache(maxsize=1000)
def cached_gemini_call(prompt_hash):
"""基于提示词哈希的缓存调用"""
# 实际调用逻辑
pass
def get_response(prompt):
prompt_hash = hashlib.md5(prompt.encode()).hexdigest()
return cached_gemini_call(prompt_hash)
Token优化 直接影响TPM消耗和成本。在不损失信息质量的前提下,精简提示词可以带来显著收益。首先,移除系统提示词中的冗余说明,保留必要的指令即可。其次,对于上下文对话,不必每次都传入完整历史,只保留最近几轮和关键信息。最后,明确指示模型生成简洁回复,避免不必要的废话。经过优化,Token消耗通常可以减少30-50%。
监控告警系统 让你在问题恶化前就能发现异常。建立一套追踪API调用成功率、延迟和配额使用情况的监控体系,当指标接近阈值时发送告警。这样可以提前采取措施,而不是等到服务中断后才匆忙救火。监控数据还能帮助你识别使用模式,找出优化机会。
| 优化策略 | RPM节省 | TPM节省 | 实施复杂度 | 适用场景 |
|---|---|---|---|---|
| 请求批处理 | 80-90% | 0% | 中 | 批量处理 |
| 智能缓存 | 50-90% | 50-90% | 中 | 重复查询多 |
| Token优化 | 0% | 30-50% | 低 | 通用 |
| 模型路由 | 20-30% | 0% | 高 | 混合需求 |
动态模型路由 是一种高级策略,根据请求的复杂度自动选择合适的模型。简单查询使用Flash模型(配额充裕),复杂任务才调用Pro模型。这种方式在保证服务质量的同时,最大化利用各模型的配额。实现时需要一个分类器来判断请求复杂度,可以基于关键词规则,也可以训练一个轻量级模型来做这个判断。
这些策略不是互斥的,而是可以叠加使用。一个成熟的生产系统通常会同时应用缓存、批处理和Token优化,再配合监控告警形成完整的防护体系。遇到API频繁触发限流的情况,如果你需要更稳定的调用能力,可以考虑使用laozhang.ai这样的多节点智能路由服务,通过分布式架构实现99.9%的可用性保障,避免单点故障带来的服务中断。
长期架构方案:构建弹性AI系统
当你的应用规模持续增长,或者业务对可用性有严格要求时,单纯的优化策略可能已经不够。这时需要从架构层面进行设计,构建一个能够自动适应负载变化、优雅处理故障的弹性系统。
多提供商故障转移 是提高可用性的核心策略。不要将所有赌注押在单一API提供商上。当Gemini API触发限流或出现故障时,自动切换到备用提供商可以保证服务不中断。备选提供商可以是OpenAI的GPT系列、Anthropic的Claude,或者是国内的智谱、月之暗面等。实现时需要定义一个统一的接口层,将具体提供商的差异封装起来。
pythonclass LLMRouter:
def __init__(self):
self.providers = [
("gemini", GeminiClient()),
("openai", OpenAIClient()),
("claude", ClaudeClient()),
]
def generate(self, prompt):
for name, client in self.providers:
try:
return client.generate(prompt)
except RateLimitError:
print(f"{name} 触发限流,切换下一个提供商")
continue
raise Exception("所有提供商均不可用")
熔断器模式(Circuit Breaker) 可以防止连锁故障。当某个API的错误率超过阈值时,熔断器会"跳闸",暂时停止向该API发送请求,转而返回降级响应或使用备用服务。经过一段冷却期后,熔断器会进入"半开"状态,允许少量请求通过来测试API是否恢复。只有测试请求成功后,熔断器才会完全"闭合"恢复正常调用。
熔断器的关键参数包括:错误率阈值(通常设为50%)、熔断持续时间(30秒到几分钟)、半开状态下允许的测试请求数。这些参数需要根据具体业务场景调优。对于对延迟敏感的实时应用,熔断持续时间应该设置得短一些;对于批处理任务,可以设置更长的等待时间。
预留吞吐量(Provisioned Throughput) 是Google为企业级客户提供的高级功能。通过预留固定的计算容量,你可以获得一致的性能保障,不受其他用户流量的影响。这种方式特别适合有可预测高峰负载的应用,比如电商大促期间的客服机器人。预留吞吐量需要通过Vertex AI平台配置,成本相对较高,但能提供其他方案无法比拟的稳定性。
何时考虑升级到付费Tier:如果你发现即使实施了上述所有优化策略,应用仍然频繁触发限流,那么升级层级可能是更经济的选择。Tier 1的配额是免费版的30倍,对于大多数中型应用来说绑绑有余。升级的成本通常远低于持续优化和处理故障的人力成本。
架构设计时还需要考虑优雅降级策略。当所有提供商都不可用时,系统应该能够返回一个可接受的降级响应,而不是直接报错。降级响应可以是预设的模板回复、缓存的历史答案,或者简单地告知用户稍后再试。关键是让用户体验尽可能平滑,即使后台正在经历技术困难。
中国开发者专属解决方案
中国开发者在使用Gemini API时面临着一些独特的挑战,这些挑战往往比单纯的速率限制更加棘手。理解这些挑战并找到对应的解决方案,是国内开发者能够顺利使用Gemini API的关键。
网络访问限制 是最直接的障碍。由于众所周知的原因,直接访问Google服务在中国大陆存在困难。即使你成功创建了API密钥,实际调用时可能会遇到连接超时或DNS解析失败。这种网络层面的问题往往会被误判为429错误,因为超时后的重试可能触发真正的限流,形成恶性循环。使用稳定的网络代理是一种解决方案,但对于生产环境来说,代理的稳定性和延迟往往难以保证。
支付验证困难 是升级到付费层级时的主要障碍。Google Cloud要求绑定国际信用卡(Visa、MasterCard等),但许多中国开发者只有国内银行卡。即使拥有双币信用卡,Google的地区验证机制也可能因为IP地址与卡片发卡地区不匹配而拒绝绑定。这导致很多开发者被困在免费版,无法获得更高的配额。
API中转服务 为这些问题提供了一个整体性的解决方案。中转服务商在海外部署服务器,已经完成了与Google官方API的对接,国内用户只需要调用中转服务商的接口,请求会被转发到Google的服务器,结果再返回给用户。整个过程对用户来说是透明的,不需要处理网络问题,也不需要绑定任何支付方式到Google。
| 对比维度 | 官方直连 | API中转服务 |
|---|---|---|
| 网络稳定性 | 需要代理,不稳定 | 直连,延迟低 |
| 支付方式 | 仅限国际卡 | 支付宝/微信 |
| 配额管理 | 自行管理 | 服务商管理 |
| 延迟 | 取决于代理质量 | 通常20-50ms |
| 成本 | 官方价格 | 可能有溢价或优惠 |
选择API中转服务时,需要关注几个关键指标。首先是稳定性和可用性,查看服务商是否有SLA保障,历史故障记录如何。其次是延迟表现,过高的延迟会影响用户体验,理想情况下延迟应该控制在50ms以内。第三是价格透明度,确认计费方式是按Token还是按请求,有没有隐藏费用。最后是模型覆盖度,确保你需要的模型都在服务范围内。
对于有稳定API调用需求的中国开发者,laozhang.ai提供了一个可靠的选择。该平台支持国内直连,延迟仅20ms左右,同时接受支付宝和微信支付。更重要的是,通过API中转服务,你可以规避免费版的严格限制,获得更高的调用配额,而无需经历绑定国际卡的繁琐流程。
如果你选择继续使用官方API,以下是一些提高成功率的技巧:尽量在流量低谷期(太平洋时间的凌晨,对应北京时间下午到晚上)进行大批量调用;使用多个Google Cloud项目分散请求,因为配额是按项目而非按账户计算的;考虑使用Vertex AI而非Gemini Developer API,前者在某些情况下有更稳定的连接。
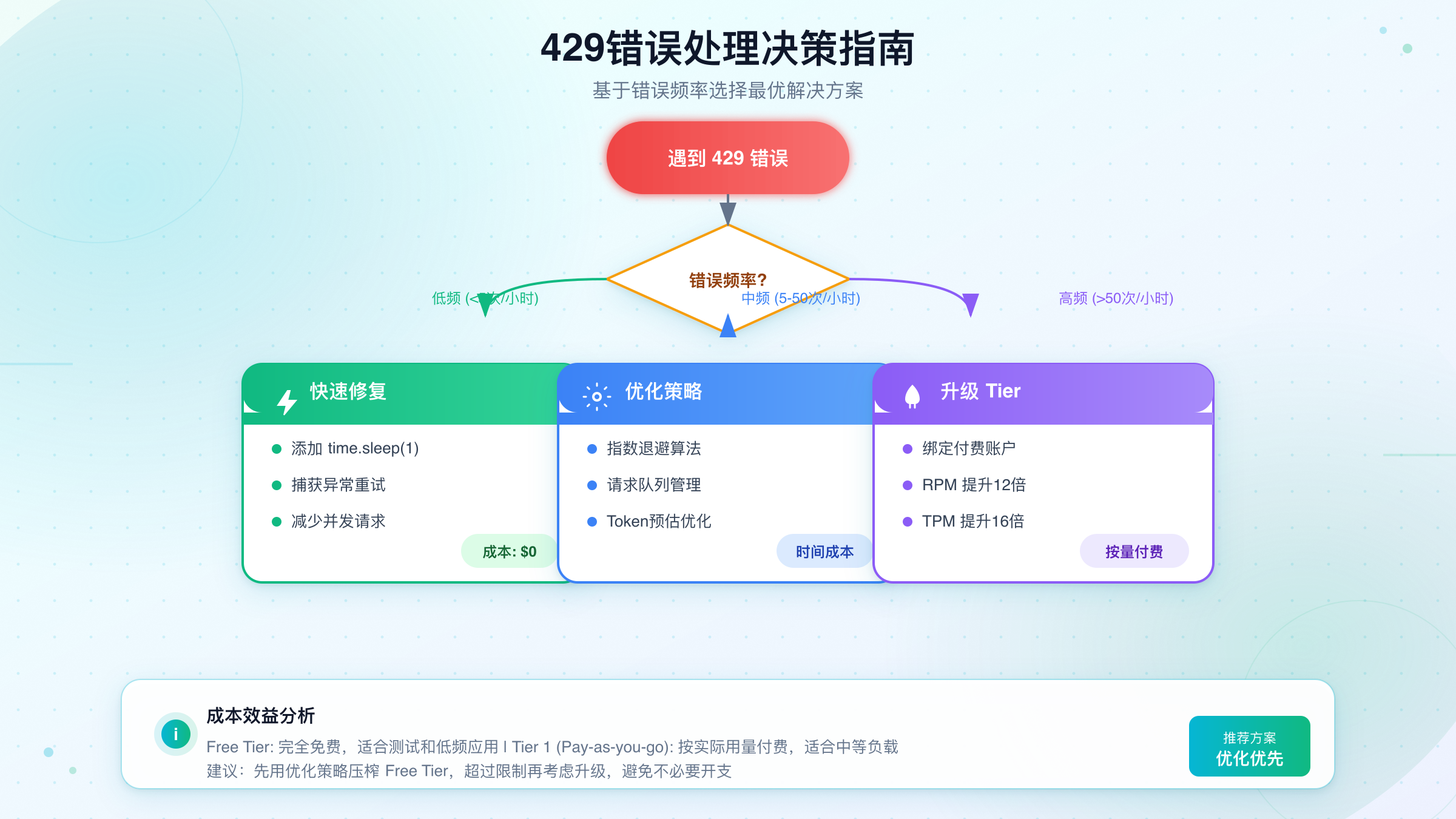
决策指南:继续优化还是直接升级
经过前面几个章节的探讨,你现在已经掌握了从快速修复到架构优化的完整工具箱。但面对具体场景时,如何决定应该采取哪种策略呢?以下决策框架可以帮助你快速做出判断。
评估当前痛点的严重程度是第一步。如果429错误只是偶尔出现,且不影响核心业务流程,那么实施指数退避重试通常就足够了。如果错误频繁出现导致用户体验明显下降,或者批处理任务无法按时完成,就需要考虑更进一步的优化措施。如果问题已经严重到影响业务收入或用户留存,直接升级到付费层级可能是最经济的选择。
| 痛点程度 | 错误频率 | 业务影响 | 推荐方案 |
|---|---|---|---|
| 轻微 | 每天几次 | 可忽略 | 指数退避重试 |
| 中等 | 每小时多次 | 影响体验 | 批处理+缓存+重试 |
| 严重 | 持续发生 | 影响收入 | 升级Tier 1 |
| 关键 | 业务中断 | 紧急 | 升级+多提供商 |
计算成本收益比是做出理性决策的基础。假设你的开发时间成本是每小时200元,花费10小时实施和调试各种优化策略的成本是2000元。如果升级到Tier 1每月成本是100美元(约700元),那么3个月内的升级成本与优化成本相当。但升级带来的是立竿见影的效果和持续的稳定性,而优化策略可能需要持续维护。从长期来看,升级往往是更划算的选择。
考虑业务发展轨迹也很重要。如果你的应用用户量正在快速增长,即使现在的优化策略够用,几个月后也很可能不够。提前规划升级路径可以避免在关键时刻手忙脚乱。相反,如果应用处于探索期,用户量不确定,保持在免费版并实施基本优化是合理的策略。
最后,记住速率限制不仅仅是技术问题。它反映的是Google对资源分配的商业决策。理解这一点有助于你以更务实的心态看待问题:Google希望通过免费版吸引开发者入门,但真正的生产级使用是需要付费的。如果你的应用确实在创造价值,为稳定的API服务付费是完全合理的商业决策。
常见问题解答
问:为什么我的配额显示0%使用,却仍然收到429错误?
这种"幽灵429"现象在2025年12月后变得更加常见。可能的原因包括:AI Studio控制台的显示延迟、后端配额同步问题、或者你触发的是RPM限制而不是RPD限制(控制台可能只显示日配额)。建议通过API响应头中的配额信息来获取更准确的数据,或者等待几分钟后重试。
问:创建多个API密钥能否获得更多配额?
不能。配额是按Google Cloud项目计算的,而不是按API密钥计算的。在同一个项目中创建多个密钥,它们共享同一份配额。如果你需要更多配额,可以创建多个独立的Google Cloud项目,每个项目都有自己的免费配额。但请注意,这种做法可能违反Google的使用条款,存在账户被封禁的风险。
问:使用异步调用会触发更多限流吗?
是的。根据Google官方文档,429错误在异步调用中更容易发生,特别是当处理大型多模态内容(如视频)时。这是因为异步调用可能在短时间内发起大量并发请求,迅速触发RPM限制。建议使用请求队列来控制并发数,或者使用同步调用配合指数退避。
问:Gemini CLI频繁报告429错误,怎么办?
Gemini CLI使用的是免费版配额,5 RPM的限制对于交互式使用来说确实捉襟见肘。CLI会尝试自动切换到Flash模型,但这个机制并不总是可靠。你可以通过/auth命令切换到使用付费API密钥,或者减少单次会话中的交互频率。如果问题持续存在,可以在GitHub Issues查看是否有已知问题和解决方案。
问:动态共享配额(Dynamic Shared Quota)是什么?
这是Google为较新的模型版本(如Gemini 1.5 Pro 002)引入的一项功能。与传统的固定配额不同,动态共享配额会根据全局资源可用性自动调整你能获得的配额。在资源充裕时你可以获得更高的限制,在资源紧张时则会相应降低。根据测试数据,使用支持动态共享配额的模型版本,即使不实施重试逻辑,成功率也能达到80%左右,相比旧版模型的40%有显著提升。
总结与下一步建议
Gemini API的RESOURCE_EXHAUSTED错误虽然令人沮丧,但通过系统性的方法是完全可以解决的。本文覆盖了从原理理解到实践操作的完整链路:首先认识四维度速率限制机制的本质;然后掌握指数退避重试、批处理、缓存等多种应对策略;最后学会如何在长期架构中构建弹性和容错能力。
对于刚遇到这个问题的开发者,建议从指数退避重试开始——这是投入产出比最高的方案,几分钟就能实现,立即见效。如果问题持续,再逐步添加缓存、批处理等优化措施。当优化空间耗尽时,果断升级到付费层级是更明智的选择。
对于中国开发者,API中转服务是绕过网络和支付障碍的有效途径。选择一个可靠的服务商,可以让你专注于应用开发本身,而不是与基础设施问题纠缠。更多关于Gemini API速率限制的技术细节,可以参考我们的另一篇文章Gemini 2.5 Pro API速率限制完整指南。
无论你选择哪种方案,记住核心原则:理解限制的本质,选择适合场景的策略,在成本和稳定性之间找到平衡。API限流不是障碍,而是指引你构建更健壮系统的路标。