OpenClaw Telegram飞书双通道配置指南:一套AI助手同时接入两大平台
从零开始同时配置OpenClaw的Telegram和飞书通道,涵盖BotFather创建、飞书开放平台设置、多Agent路由绑定、定时任务、流式响应和安全加固,实现一个AI大脑服务两个平台。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
一个AI助手,两个沟通平台——这正是越来越多开发者和团队追求的理想工作模式。**OpenClaw**作为拥有272k GitHub Stars的开源AI助手框架,天然支持Telegram和飞书的同时接入,让你的私人AI可以在移动端随时响应个人消息,也能在企业飞书群里处理工作协作。与单独配置每个平台不同,同时接入两个通道的核心挑战在于理解OpenClaw的多渠道架构、正确设置Agent路由、以及确保两个平台的消息互不干扰又共享同一个AI大脑。
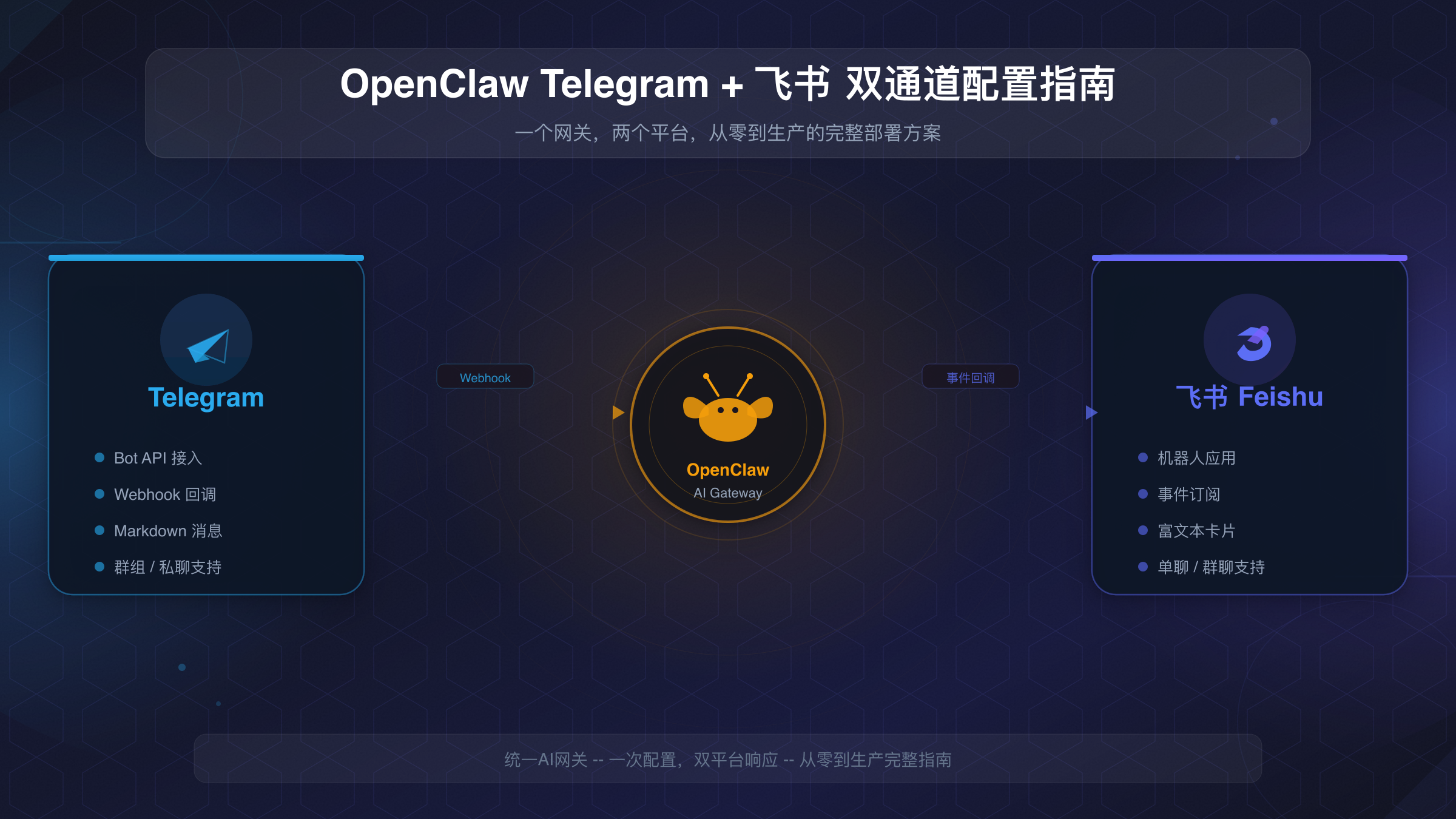
本文将从零开始,手把手带你完成OpenClaw的Telegram和飞书双通道配置。从BotFather创建Telegram机器人到飞书开放平台的应用注册,从基础的单Agent模式到进阶的多Agent路由绑定,从定时任务到流式响应优化,每一步都包含可直接复用的配置代码和经过验证的最佳实践。整个过程大约需要30分钟,完成后你将拥有一个同时服务于Telegram和飞书的AI助手,无论身处何地都能通过最方便的工具获得AI支持。
OpenClaw多渠道架构:理解"一个大脑,多个嘴巴"
在动手配置之前,理解OpenClaw的多渠道架构能帮你避免大量时间浪费在错误的方向上。OpenClaw采用的是本地网关(Gateway)架构——所有的AI推理、对话记忆和技能执行都发生在你自己的服务器上,而Telegram和飞书只是消息的"入口"和"出口"。这种设计意味着你的对话数据永远不会经过第三方服务器,AI模型的API Key也安全地保存在你的设备上。
Gateway是整个系统的核心控制面,默认运行在18789端口。当用户在Telegram发送消息时,Gateway通过Bot API轮询接收消息,经AI模型处理后将回复推回Telegram。飞书的消息流转机制略有不同——Gateway通过WebSocket长连接主动连接飞书服务器,实时接收事件推送,这意味着飞书通道不需要公网IP或域名,即使在NAT环境或企业防火墙后面也能正常工作。
这里有一个关键概念需要理解:Workspace(工作区)。每个OpenClaw实例有一个默认工作区(通常在~/.openclaw/workspace/),它包含了AI助手的指令文件(AGENTS.md)、用户偏好(USER.md)和长期记忆(MEMORY.md)。默认情况下,来自Telegram和飞书的消息共享同一个工作区,这意味着你在Telegram上让AI记住的信息,可以在飞书对话中被自然引用。如果你希望两个平台完全隔离,可以通过创建不同的Agent来实现,这一点我们在多Agent路由部分详细展开。
OpenClaw的通道系统采用插件化设计,每个通道都有独立的认证、权限和消息格式处理逻辑。Telegram通道是内置的,开箱即用;飞书通道同样内置支持,通过domain参数区分国内飞书(feishu)和国际版Lark(lark)。这种统一的通道抽象层让你可以用相同的配置结构管理不同的平台,只是认证方式和消息格式有所差异。
| 对比维度 | Telegram通道 | 飞书通道 |
|---|---|---|
| 连接方式 | Bot API轮询 | WebSocket长连接 |
| 公网IP需求 | 不需要 | 不需要 |
| 认证方式 | Bot Token | App ID + App Secret |
| 流式响应 | sendMessageDraft原生支持 | 交互卡片逐步更新 |
| 群组控制 | 群组ID白名单 | 群组ID + @提及控制 |
| DM策略 | pairing/allowlist/open | pairing/allowlist/open |
| 媒体限制 | 100MB | 30MB |
架构要点:OpenClaw的所有通道共享同一个AI推理引擎和工作区,这是"一套AI服务多个平台"的技术基础。理解这一点后,你会发现双通道配置本质上就是分别完成两个通道的认证设置。
环境准备与安装:10分钟搭建基础设施
硬件与软件要求
OpenClaw对硬件的要求非常友好——纯聊天场景只需要500MB磁盘空间和512MB内存。一台月费$4-6的基础VPS完全够用,国内的轻量应用服务器(如阿里云轻量或腾讯云Lighthouse)同样适合。
硬件最低要求:500MB磁盘 + 512MB内存 + Node.js 22+。推荐配置:2核CPU + 2GB内存的VPS,足以流畅运行双通道+多Agent。操作系统方面,macOS、Linux和Windows都被支持,但Linux是生产环境的推荐选择,因为它对Daemon守护进程的支持最成熟。
软件层面的唯一硬性要求是Node.js 22或更高版本。这是新手最常踩的第一个坑——很多Linux发行版的默认包管理器安装的Node.js版本远低于22。你可以通过node --version检查当前版本。如果版本不够,推荐使用nvm(Node Version Manager)来管理Node.js版本,它能让你在多个版本之间自由切换而不影响系统环境。
bashcurl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.1/install.sh | bash
source ~/.bashrc
nvm install 22
nvm use 22
node --version # 应输出 v22.x.x
安装OpenClaw
环境就绪后,安装OpenClaw只需要两条命令。官方提供了一键安装脚本,它会自动处理依赖检查、全局安装和初始化引导:
bashcurl -fsSL https://openclaw.ai/install.sh | bash openclaw onboard --install-daemon
--install-daemon参数会将OpenClaw注册为系统服务,确保它在后台持续运行,即使SSH连接断开也不会中断。如果你更喜欢手动控制,也可以跳过这个参数,在需要时通过openclaw gateway start手动启动。如果你还需要浏览器自动化能力,可以参考OpenClaw Browser Relay完全指南来配置浏览器控制模块。
安装过程中会出现一个交互式引导(Onboard),它会依次询问你要使用的LLM提供商、通讯渠道和可选技能。在通道选择环节先跳过——我们稍后会手动配置Telegram和飞书,这样可以更精细地控制每个参数。LLM提供商的选择则根据你的实际需求:想要零成本入门可以选Google Gemini(免费层每天约100万Token),追求质量可以选Claude或GPT-4o,完全本地化可以选Ollama。
安装完成后,运行openclaw gateway status确认Gateway正在运行。如果一切正常,你应该能看到Gateway的运行状态、端口号和已加载的通道列表。此时访问http://127.0.0.1:18789/chat可以打开WebChat界面,先测试AI是否能正常对话,再继续配置外部通道。
Telegram机器人完整配置:从BotFather到消息流转
创建Telegram Bot
配置Telegram通道的第一步是在Telegram中创建一个机器人。打开Telegram应用,在搜索栏输入@BotFather,注意认准带有蓝色认证对勾的官方账号。向BotFather发送/newbot命令(详见Telegram Bot API官方文档),它会引导你完成以下两个设置:
显示名称(Display Name)是用户在对话列表中看到的名字,可以包含中文和空格,比如"我的AI助手"或"Team AI"。用户名(Username)是机器人的唯一标识,必须以_bot或Bot结尾,只能包含英文字母、数字和下划线,例如my_ai_assistant_bot。创建成功后,BotFather会返回一个API Token,格式类似123456789:ABCdefGHIjklmnoPQRstuvWXYZ——这是控制机器人的唯一凭证,必须立即复制并安全存储。
安全提醒:Telegram Bot Token是控制机器人的唯一密钥。任何持有Token的人都能以你的机器人名义发送消息,绝对不要将它提交到公开仓库或通过不加密渠道传输。
如果你对Telegram机器人的创建流程还不熟悉,可以参考我们的OpenClaw Telegram配置完全指南获取更详细的步骤说明。创建Bot之后,还有一个容易被忽略但对群组功能至关重要的设置:隐私模式(Privacy Mode)。默认情况下,Telegram机器人在群组中只能接收到直接@提及它的消息。如果你希望机器人能"听到"群组中的所有消息,需要在BotFather中发送/setprivacy,选择你的机器人,然后选择Disable。请注意,修改隐私设置后需要将机器人从群组中移除再重新添加才能生效。
添加Telegram通道
Bot Token到手后,通过OpenClaw CLI将Telegram通道添加到Gateway:
bashopenclaw channels add --channel telegram
系统会提示你输入Bot Token。粘贴后,OpenClaw会自动验证Token的有效性并完成通道注册。你也可以通过环境变量TELEGRAM_BOT_TOKEN来传递Token,这在Docker部署和CI/CD流水线中更加方便。
通道添加成功后,OpenClaw默认启用配对模式(pairing)作为DM策略。这意味着当你第一次向机器人发送消息时,它会返回一个6位数的配对码,你需要在服务器端运行openclaw pairing approve telegram <code>来批准访问。配对码有1小时的有效期,过期需要重新发送消息获取新的配对码。
对于个人使用场景,配对模式是最安全的选择。但如果你希望指定特定用户可以直接使用(无需配对),可以切换到白名单模式,在配置中明确列出允许的Telegram用户ID:
json{
"channels": {
"telegram": {
"enabled": true,
"dmPolicy": "allowlist",
"allowFrom": [123456789, 987654321]
}
}
}
获取自己的Telegram用户ID很简单——向@userinfobot发送任意消息,它会返回你的数字ID。
群组配置与消息路由
如果你想在Telegram群组中使用AI机器人,需要额外配置群组访问策略。首先将机器人添加到目标群组,然后获取群组的Chat ID。最可靠的方法是通过Telegram Bot API:将机器人添加到群组后,访问https://api.telegram.org/bot<YOUR_TOKEN>/getUpdates,在返回的JSON中找到chat.id字段(群组ID通常是负数,如-1001234567890)。
在OpenClaw配置中,群组策略默认为allowlist模式,你需要显式添加群组ID才能启用响应:
json{
"channels": {
"telegram": {
"groups": {
"-1001234567890": {
"systemPrompt": "你是团队的技术助手,专注于回答编程和架构问题。"
}
},
"groupAllowFrom": [123456789]
}
}
}
groupAllowFrom控制哪些用户可以在群组中触发机器人响应。如果设置为["*"],则群组内所有成员都可以与机器人交互。systemPrompt允许你为不同群组定制AI的角色和行为,比如技术群专注于代码问题,运营群专注于数据分析。
消息流式输出是提升Telegram交互体验的关键。OpenClaw支持通过streaming参数控制消息的推送方式。在Telegram私聊中,partial模式(默认)使用原生的sendMessageDraft功能实现打字预览效果,用户可以看到AI正在逐步生成回复。在群组中,流式输出通过发送临时消息+editMessageText来模拟实时生成效果。如果你的网络环境不稳定,可以将streaming设为off,等AI完整生成后再一次性发送。
飞书机器人完整配置:从开放平台到长连接
创建飞书企业应用
飞书通道的配置比Telegram稍复杂,因为它涉及企业应用的注册和权限审批流程。但好消息是,飞书采用的WebSocket长连接模式意味着你不需要公网IP、不需要配置Webhook URL、不需要内网穿透——Gateway会主动向飞书服务器发起出站连接,在NAT和企业防火墙后面都能正常工作。
首先访问飞书开放平台(如果使用国际版Lark,则访问open.larksuite.com/app),用企业管理员账号登录。点击"创建企业自建应用",填写应用名称、描述和图标。创建完成后,进入应用详情页面,在"凭证与基础信息"中找到App ID(格式为cli_xxxxxxxxx)和App Secret,这两个值是OpenClaw连接飞书的唯一凭证,务必安全存储。
接下来需要开通应用的必要权限。进入"权限管理"页面,飞书支持批量导入权限配置。你至少需要以下三个核心权限:
| 权限Scope | 功能说明 |
|---|---|
im:message | 接收用户发送的消息 |
im:message:send_as_bot | 以机器人身份发送回复消息 |
im:chat | 群组相关操作(加群、获取群信息) |
如果你还需要机器人读取用户基本信息(如头像和姓名),可以额外添加contact:user.base:readonly权限。权限添加后需要区分应用权限和用户权限两种类型——上述权限都属于应用权限,通过管理员审批即可生效,不需要用户额外授权。
启用机器人能力与事件订阅
权限配置完成后,进入"应用能力"页面,找到机器人(Bot)能力并启用它。启用后你可以设置机器人的显示名称,这是用户在飞书中看到的机器人头像旁边的名字。
关键步骤:飞书通道必须选择"长连接"模式并添加
im.message.receive_v1事件。缺少任何一项都会导致机器人无法接收消息,这是新手配置飞书最常见的失败原因。
事件订阅是飞书通道正常工作的核心。进入"事件订阅"设置,选择长连接(WebSocket)模式而非传统的Webhook模式——这是OpenClaw与飞书通信的关键机制。然后添加im.message.receive_v1事件,这个事件会在用户向机器人发送消息时触发推送。如果不添加这个事件,机器人能发消息但收不到用户的输入,这是新手最容易遗漏的配置步骤。
所有配置完成后,需要通过飞书的版本管理和发布流程将应用正式上线。创建一个新版本,填写版本说明,提交发布审核。企业版应用通常需要管理员在飞书客户端中审批后才能生效。发布成功后,企业成员就可以在飞书中搜索到你的机器人并开始对话。
添加飞书通道到OpenClaw
回到服务器端,通过CLI将飞书通道添加到Gateway:
bashopenclaw channels add --channel feishu
系统会提示你输入App ID和App Secret。粘贴后,OpenClaw会验证凭证有效性并建立WebSocket连接。你也可以通过配置文件直接设置,推荐使用环境变量来存储敏感信息:
json{
"channels": {
"feishu": {
"enabled": true,
"domain": "feishu",
"dmPolicy": "pairing",
"streaming": true,
"accounts": {
"main": {
"appId": "${FEISHU_APP_ID}",
"appSecret": "${FEISHU_APP_SECRET}",
"botName": "AI助手"
}
}
}
}
}
domain参数决定了API端点的选择——国内用户设为feishu,国际版用户设为lark。streaming设为true后,AI的回复会通过飞书的交互卡片实时更新,提供类似ChatGPT的流式输出体验。如果禁用流式,机器人会等到AI完整生成后才发送一条完整的文本消息。
飞书通道同样支持配对模式作为默认DM策略。新用户第一次给机器人发消息会收到配对码,需要在服务器端运行openclaw pairing approve feishu <code>来批准。如果要切换到白名单模式,需要使用飞书的Open ID(格式为ou_xxx)作为用户标识,可以通过查看Gateway日志或运行openclaw pairing list feishu来获取。
飞书的群组配置相比Telegram有一个显著区别:默认启用了**@提及触发**(requireMention: true)。这意味着在群聊中,用户必须@机器人才会触发AI回复,群组中的普通对话不会被机器人处理。这个设计在高频率群聊场景中非常重要,避免了机器人对每条消息都生成响应导致的干扰。如果你的群组成员较少且希望机器人自动回复所有消息,可以将requireMention设为false。
重启Gateway让配置生效:
bashopenclaw gateway restart
然后在飞书中搜索你的机器人名称,发送一条测试消息。如果一切配置正确,你应该在几秒钟内收到AI的回复。如果没有收到回复,首先检查Gateway日志(openclaw gateway logs)中是否有连接错误,然后确认飞书应用是否已成功发布、事件订阅是否配置了长连接模式。
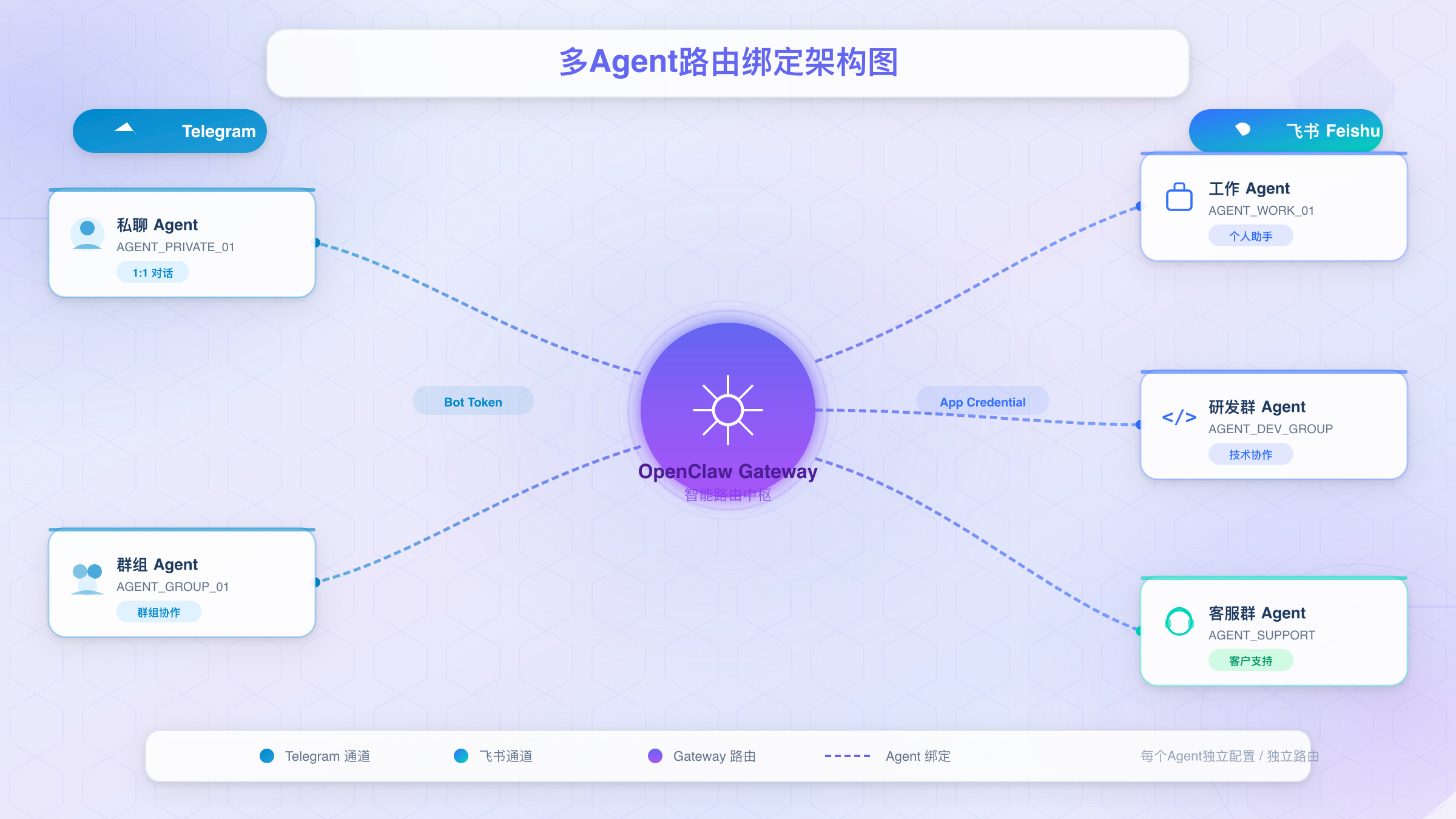
多渠道协同:Agent路由与消息分流策略
当Telegram和飞书两个通道同时运行后,一个自然的问题是:能否让不同的平台使用不同风格的AI?比如Telegram上的机器人偏技术极客风,飞书上的机器人偏职场专业风?OpenClaw的多Agent系统和Bindings路由正是为此设计的。
创建专用Agent
每个Agent拥有独立的身份(指令)、状态(记忆)和工作区,可以使用不同的AI模型。通过CLI快速创建:
bashopenclaw agents add personal --model anthropic/claude-sonnet-4-6 openclaw agents add work --model deepseek/deepseek-chat
这两条命令分别创建了名为personal和work的Agent。personal使用Claude Sonnet处理个人事务,work使用DeepSeek处理工作任务。每个Agent都有独立的工作区目录,你可以分别编辑它们的AGENTS.md文件来定义不同的行为指令——比如personal的指令强调休闲和创意,work的指令强调专业和精确。
配置Bindings路由
Bindings是OpenClaw将消息路由到特定Agent的机制。在openclaw.json配置文件中,你可以通过精确的匹配规则将不同来源的消息分发到不同Agent:
json{
"bindings": [
{
"agentId": "personal",
"match": {
"channel": "telegram"
}
},
{
"agentId": "work",
"match": {
"channel": "feishu"
}
}
]
}
这个配置的含义很直接:所有来自Telegram的消息交给personal Agent处理,所有来自飞书的消息交给work Agent处理。Bindings的匹配采用优先级系统——精确匹配(指定peer ID)优先于通道级匹配,通道级匹配优先于默认匹配。这意味着你可以在通道级路由的基础上,为特定群组设置更精细的Agent分配。
例如,你可能希望飞书的技术群使用编码Agent,而飞书的运营群使用分析Agent:
json{
"bindings": [
{
"agentId": "coder",
"match": {
"channel": "feishu",
"peer": { "kind": "group", "id": "oc_tech_group_id" }
}
},
{
"agentId": "analyst",
"match": {
"channel": "feishu",
"peer": { "kind": "group", "id": "oc_ops_group_id" }
}
},
{
"agentId": "personal",
"match": {
"channel": "telegram"
}
}
]
}
Bindings优先级规则:精确peer匹配 → 父级peer匹配 → 群组+角色 → 群组 → 团队 → 账户 → 通道 → 默认回退。规则越具体,优先级越高。
多Agent路由的一个重要考量是会话隔离。默认情况下,同一个Agent的不同对话会共享工作区和记忆。如果你希望每个Agent的会话完全独立(一个飞书群的对话不影响另一个群),可以为每个Agent设置dmScope: "agent"。这样每个Agent维护独立的会话上下文,避免了信息意外泄露到不相关的对话中。
对于中国开发者来说,多Agent配置还涉及一个实际问题:不同Agent可能需要使用不同的LLM提供商。Telegram上的个人Agent可能使用Claude或GPT-4o获得更好的对话质量,而飞书上的工作Agent可能使用DeepSeek或Qwen来降低成本。如果你在国内网络环境下使用海外模型,需要配置代理或者使用支持国内直连的API服务。通过laozhang.ai这类中转服务,你可以在国内无需VPN直接访问Claude、GPT-4o等模型,延迟低至20ms,同时支持支付宝/微信支付,省去了信用卡和网络代理的麻烦。
高级玩法:定时任务、Skills与流式响应优化
定时任务(Cron):让AI主动推送信息
OpenClaw的定时任务功能让AI从"被动回答"升级为"主动服务"。你可以设定定时触发的任务,让AI在特定时间自动执行操作并将结果推送到Telegram或飞书。
bashopenclaw cron add --name "晨间简报" \
--cron "0 9 * * *" \
--system-event "生成今日天气和待办提醒,保持简洁" \
--deliver telegram
这条命令创建了一个每天早上9点执行的任务,AI会生成晨间简报并通过Telegram推送。--deliver参数指定了推送渠道——你可以设为telegram、feishu或同时推送到两个平台。通过定时任务,飞书群可以每天自动收到项目进度汇总,Telegram可以收到个人日程提醒,实现工作和生活的智能化管理。
定时任务还有一个进阶用法:结合Skills实现自动化工作流。例如,每天凌晨自动检查GitHub仓库的新Issue、每周五生成项目周报并推送到飞书群——这些都可以通过Cron + Skills的组合来实现。
Skills系统:扩展AI能力边界
OpenClaw的Skills系统类似插件市场,官方的ClawHub上已有超过13000个社区贡献的技能。通过简单的命令即可安装:
bashopenclaw skills list # 查看已安装技能
clawhub install github-issues # 安装GitHub Issues管理技能
clawhub install web-search # 安装网页搜索技能
clawhub install aliyun-asr # 安装阿里云语音识别(飞书语音消息转文字)
Skills安装后对所有通道自动生效——这意味着你在Telegram中可以让AI搜索网页,在飞书中可以让AI管理GitHub Issue,两个平台共享同一套能力。对于需要限制特定Agent能力的场景,可以通过allow/deny列表控制:
json{
"agents": {
"work": {
"tools": {
"allow": ["github-issues", "web-search"],
"deny": ["browser"]
}
}
}
}
流式响应优化对比
Telegram和飞书的流式响应在实现机制上有显著差异,理解这些差异有助于你针对性地优化用户体验。Telegram在私聊中使用Bot API 9.5引入的sendMessageDraft功能,这是一种原生的打字预览机制,用户体验接近人类在对话中逐字输入的感觉。飞书则通过交互卡片(Interactive Card)来实现流式输出——AI的回复被包装在一个可更新的卡片中,每生成一段内容就更新一次卡片,视觉效果更加结构化。
| 流式特性 | Telegram | 飞书 |
|---|---|---|
| 实现机制 | sendMessageDraft | 交互卡片更新 |
| 视觉效果 | 类似打字预览 | 结构化卡片 |
| 群组支持 | editMessageText模拟 | 同DM |
| 文本块限制 | 无 | 2000字符/块 |
| 关闭方式 | streaming: "off" | streaming: false |
飞书的textChunkLimit参数(默认2000字符)控制每次卡片更新的最大文本长度。如果AI的回复特别长,飞书会自动分块更新。对于大多数日常对话场景,默认值足够使用,但如果你的AI经常生成长文档或代码,可以适当调大这个值以减少更新次数,降低API调用频率。
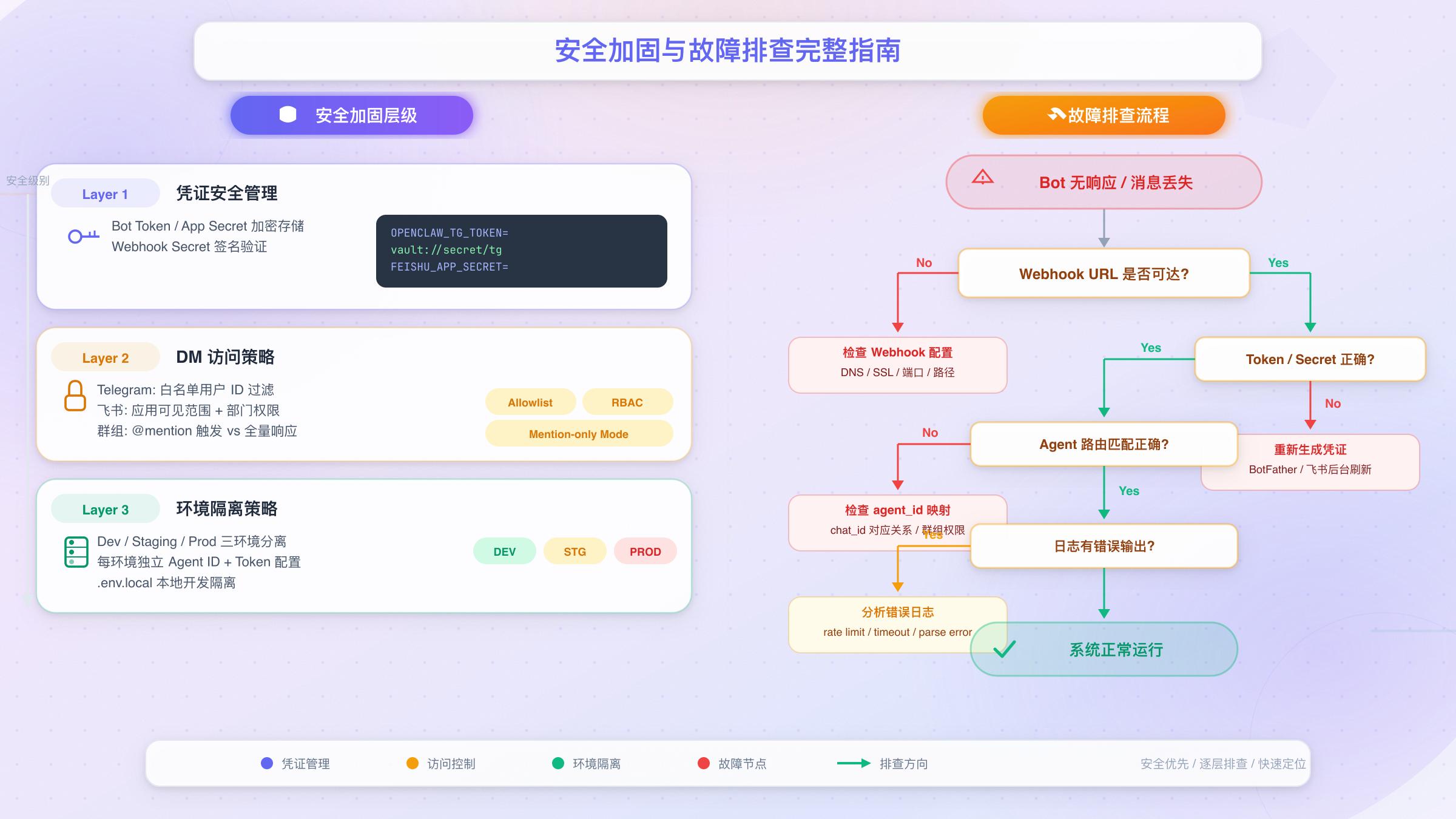
安全加固与故障排查:生产环境最佳实践
凭证安全管理
在双通道配置中,你至少要管理三个敏感凭证:Telegram Bot Token、飞书App ID和App Secret。这些凭证一旦泄露,攻击者就能以你的机器人身份发送消息,在企业场景中可能造成严重的信息安全事故。
安全底线:双通道配置涉及至少3个敏感凭证(Telegram Bot Token、飞书App ID、App Secret)。任何一个泄露都可能导致机器人被冒用发送消息。
最基本的安全原则是永远不要将凭证硬编码到配置文件中,更不要提交到Git仓库。OpenClaw支持通过环境变量传递敏感信息,凭证文件默认存储在~/.openclaw/secrets/目录下并设有访问权限控制。在Docker部署中,使用Docker Secrets或环境变量注入,避免在Dockerfile或docker-compose.yml中明文写入凭证。
如果不幸发现凭证已泄露,需要立即执行以下操作:对于Telegram,在BotFather中使用/revoke命令吊销旧Token并生成新Token;对于飞书,在开放平台的凭证管理页面重置App Secret。然后更新OpenClaw配置并重启Gateway。
DM策略选择指南
选择合适的DM策略是平衡安全性和便利性的关键。OpenClaw为两个平台提供了一致的四种DM策略,但实际场景中的最佳选择不同:
个人使用推荐allowlist模式。你明确知道谁应该有权使用机器人,将自己的用户ID添加到白名单后即可直接对话,无需每次配对。这比配对模式更方便,同时比开放模式更安全。
团队共享推荐pairing模式。新成员通过配对码验证身份,管理员在服务器端审批后永久授权。这在中等规模团队中实现了"一次审批,永久使用"的良好平衡,既不需要维护复杂的白名单,又确保了只有经过认可的成员才能使用。
公开服务推荐open模式并配合速率限制。如果你的机器人面向不特定公众提供服务(如客服机器人),open模式允许任何人直接对话。但务必设置合理的消息频率限制和API用量预算,防止滥用导致的高额API费用。
常见故障排查
双通道配置中最常见的故障集中在连接和权限两个方面。以下是经过实践验证的排查清单:
机器人完全无响应:首先检查Gateway状态(openclaw gateway status),确认它处于运行状态。然后检查通道是否正确加载(openclaw channels status --probe),如果显示某个通道处于断开状态,查看Gateway日志(openclaw gateway logs)中的具体错误信息。Telegram通道的典型连接问题是网络不通(需要确认服务器能访问api.telegram.org),飞书通道的典型问题是WebSocket连接失败(检查App ID/Secret是否正确、应用是否已发布)。如果遇到Gateway启动失败,可以参考OpenClaw Gateway无法启动的排查指南。如果看到401认证错误,OpenClaw HTTP 401错误解决方案中有详细的排查流程。
Telegram能收消息但飞书不行(或反之):这通常是单个通道的配置问题。对于飞书,最常见的原因是事件订阅未配置长连接模式——如果选择了Webhook模式但没有提供回调URL,飞书无法将消息推送给Gateway。另一个常见原因是忘记添加im.message.receive_v1事件,导致飞书不会推送新消息事件。
群组中机器人不回复:Telegram群组需要检查隐私模式是否已关闭(BotFather /setprivacy → Disable),以及群组ID是否已添加到配置中。飞书群组需要确认requireMention设置——如果为true,用户必须@机器人才会触发回复。
API配额意外耗尽:这在飞书通道中尤其常见。如果飞书群里有大量消息且requireMention设为false,机器人会尝试处理每一条消息,快速消耗LLM的API配额。解决方案是重新启用requireMention或设置groupAllowFrom来限制触发用户范围。对于API成本敏感的场景,可以考虑通过laozhang.ai使用按Token计费的方案——充值$100获得$110额度,透明计费让你清楚每条消息的实际成本,避免了按月订阅模式下的"不用白不用"心态导致的资源浪费。
网络环境导致的间歇性故障:在WSL2环境或某些VPS上,IPv6优先的DNS解析可能导致Telegram连接不稳定。通过设置环境变量OPENCLAW_TELEGRAM_DNS_RESULT_ORDER=ipv4first可以强制使用IPv4,通常能解决这类问题。另一个常见的网络问题是服务器同时运行Telegram和飞书通道时的连接竞争——OpenClaw的Gateway默认能处理多通道并发,但如果服务器内存不足(低于512MB),可能会导致其中一个通道的连接被意外断开。
运行诊断工具
当上述排查步骤无法定位问题时,OpenClaw提供了内置的诊断工具:
bashopenclaw doctor --deep
这个命令会检查Node.js版本、网络连通性、通道认证状态、工作区完整性和系统资源使用情况,生成一份详细的诊断报告。报告中会明确标注每个检查项的通过/失败状态,以及失败项的修复建议,是排查复杂问题的最高效工具。
完整配置示例与决策参考
将前面所有章节的配置整合,以下是一个同时运行Telegram和飞书双通道、配合多Agent路由的完整配置示例:
json{
"gateway": {
"port": 18789
},
"channels": {
"telegram": {
"enabled": true,
"dmPolicy": "allowlist",
"allowFrom": [123456789],
"streaming": "partial",
"groups": {
"-1001234567890": {
"systemPrompt": "你是技术助手",
"requireMention": false
}
}
},
"feishu": {
"enabled": true,
"domain": "feishu",
"dmPolicy": "pairing",
"streaming": true,
"requireMention": true,
"accounts": {
"main": {
"appId": "${FEISHU_APP_ID}",
"appSecret": "${FEISHU_APP_SECRET}",
"botName": "工作助手"
}
}
}
},
"bindings": [
{
"agentId": "personal",
"match": { "channel": "telegram" }
},
{
"agentId": "work",
"match": { "channel": "feishu" }
}
]
}
回顾整个配置过程,从安装OpenClaw到双通道上线大约需要30分钟。Telegram通道的配置更简单直接——创建Bot、获取Token、添加通道三步完成;飞书通道涉及企业应用注册和权限审批,流程稍长但WebSocket长连接的设计免去了公网IP的需求。两个平台的核心差异在于认证方式(Token vs App ID/Secret)、消息触发机制(全量接收 vs @提及控制)和流式响应实现(Draft消息 vs 交互卡片),理解这些差异有助于你根据实际场景选择最合适的配置策略。
对于个人开发者,Telegram作为移动端的随身AI入口,飞书作为工作场景的协作助手,两者互补构成了完整的AI服务覆盖。对于小型团队,建议从单Agent共享模式开始,当不同场景的需求差异明显时再引入多Agent路由。无论哪种模式,OpenClaw的本地优先架构确保了你的对话数据始终掌握在自己手中,这在数据安全日益重要的今天是一个不可替代的优势。