Claude RAG 指南:什么时候直接用长上下文,什么时候上向量检索
面向中文开发者的 Claude RAG 最新指南:解释什么时候可以直接用长上下文、Prompt Caching、PDF support 和 Citations,什么时候才值得做基础向量 RAG,什么时候需要升级到 Contextual Retrieval + reranking。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
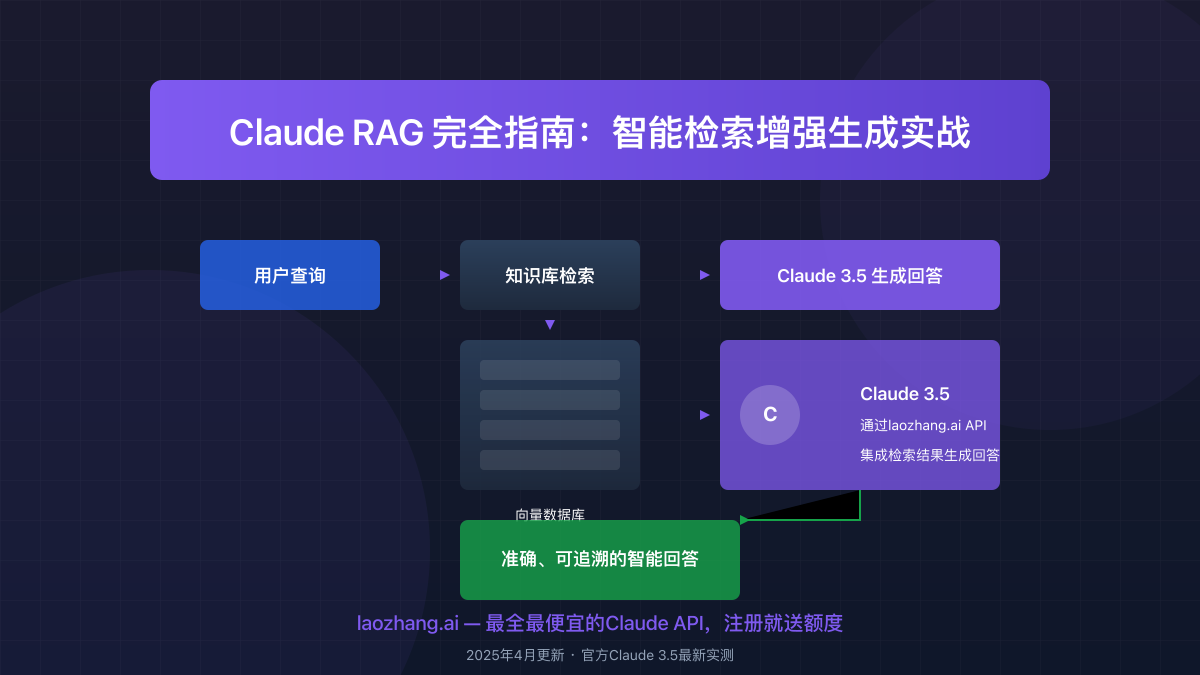
如果你现在还在搜“Claude RAG 指南”,大概率不是还缺一篇把 PyPDFLoader + Chroma + RetrievalQA 从头抄一遍的教程,而是已经准备把 PDF、帮助中心、内部 SOP 或知识库接进产品,卡在一个更现实的问题上:在 Claude 现在这套能力边界下,你到底该不该先做传统向量 RAG。
这个问题之所以比 2024 年更难回答,不是因为选择变少了,而是因为选择变多了。Anthropic 现在已经把长上下文、prompt caching、PDF support、citations、search result content blocks 这些能力摆到台面上;如果你还默认“文档问答 = 一定要先切块、建向量库、做 RetrievalQA”,很多项目会过早走进更重的系统设计。
这篇文章不打算继续把“能跑一个 demo”写成“适合上线的架构”。我会先给你一张三路决策矩阵,回答什么时候直接用长上下文就够,什么时候需要基础向量检索,什么时候才值得上 Contextual Retrieval + reranking。只有这个判断先做对,后面的模型、成本和代码示例才不会跑偏。
TL;DR
- 如果你的知识库总量还在约
200,000 tokens以内,且问题更偏总结、解释、抽取而不是复杂跨文档精确定位,先试长上下文 + prompt caching + citations,不要一上来就做向量 RAG(Anthropic Contextual Retrieval,2026-03-19 验证)。 - 如果你的知识库开始持续增长,问题里经常出现产品名、错误码、政策条款、版本号这类需要精准定位的标识符,再进入基础向量 RAG 阶段更合理。
- 如果你已经做了向量检索,但仍频繁遇到“明明文档里有,系统就是召回不到”或“召回到了,但相关块排不到前面”,再考虑
Contextual Retrieval + BM25 + reranking;Anthropic 公布的实验里,这套升级能把 top-20 failed retrieval 再明显压低(Anthropic Contextual Retrieval,2026-03-19 验证)。 - Claude 当前模型主语境已经不是旧教程里的
Claude 3.5。如果你现在还把claude-3-5-sonnet-20240620当默认起点,判断已经落后了一代;Anthropic 当前公开主语境是Claude Opus 4.6 / Sonnet 4.6 / Haiku 4.5(Anthropic Choosing a model,2026-03-19 验证)。 - 做 Claude 文档问答时,别把“OpenAI-compatible 能回字”误当成“原生能力完全等价”。真正要验的是:你依赖的引用、PDF 处理、缓存、检索质量和回退路径有没有真的成立。
为什么今天做 Claude 文档问答,先别急着上向量库
很多旧文章会把 RAG 写成一个固定套路:先切 chunk,再做 embedding,再上向量库,最后拼个回答链。这条路线当然没有错,但它现在已经不再是所有 Claude 文档问答项目的默认起点。Anthropic 在自己的 Contextual Retrieval 文章里明确写到,如果知识库小于约 200,000 tokens,很多场景可以先直接把知识放进 prompt,而不一定先做 RAG(Anthropic Contextual Retrieval,2026-03-19 验证)。
这句话的含义,不是“向量检索没用了”,而是架构顺序变了。以前你为了把文档塞进上下文窗口,不得不尽快做检索层;现在 Claude 的长上下文和缓存能力,把一部分中小知识库场景从“必须先建索引”变成了“可以先直接答,再看是否真的需要检索系统”。如果你做的是内部问答、产品文档解释、政策摘要、培训资料助手,这种顺序变化很重要,因为它能直接减少第一版系统复杂度。
另一个被旧教程低估的变化,是 Claude 现在原生支持 citations,并且对 PDF 文档有更好的原生处理路径(Anthropic Citations / PDF support,2026-03-19 验证)。这意味着你要做的不是简单地“把文档灌进去”,而是重新判断:当前场景最缺的是大规模召回,还是可信引用和可解释回答。如果你最在意的是“模型别编造,最好能指出依据”,原生引用能力常常比你先自建一整套复杂链路更值得优先落地。
还有一点经常被忽略。Anthropic 当前还提供 search result content blocks,官方文档明确把它描述成特别适合 RAG 的能力,因为它天然带 source attribution,更容易把引用和回答一起组织清楚(Anthropic Search results,2026-03-19 验证)。这再次说明,今天做 Claude 文档问答,不该只从“怎么召回”出发,而应该先从“我的用户到底需要总结、引用还是精确定位”出发。
所以我更推荐你把 Claude 文档问答拆成三个连续问题:
- 我的问题规模,真的已经逼我进入检索系统了吗?
- 我的主要风险,是召回不到,还是回答不可信?
- 我现在缺的是工程能力,还是决策能力?
只有这三个问题先回答清楚,后面你选择长上下文、基础向量 RAG 还是上下文化 RAG 才会更稳。
Claude 文档问答的三条架构路线怎么选
先给结论。现在做 Claude 文档问答,最实用的不是问“RAG 好不好”,而是先判断你属于下面哪一条路线。
第一条路线是 直接长上下文 + prompt caching + citations。这条路线最适合知识库还不算大、问题偏总结解释、并且你特别在意回答可信度的项目。它的优势是系统简单、上线快、排障边界清晰。它的代价是当文档继续膨胀、问题越来越像“请在数百份文件里定位某个极具体条款”时,模型再强也不该硬扛全部召回工作。
第二条路线是 基础向量 RAG。当你的知识库规模持续增长,用户问题越来越依赖跨文档查找、版本比对、错误码定位、精确段落检索时,向量检索就重新变成必需层。它不是“更高级”的象征,而是把“先缩小候选范围”这件事交给检索系统完成,避免模型直接在过大上下文里盲搜。
第三条路线是 上下文化 RAG + BM25 + reranking。这条路线不是给所有人准备的,而是给那些已经做过基础 RAG、却还在被召回质量拖后腿的团队准备的。Anthropic 官方对 Contextual Retrieval 的描述很明确:传统 RAG 的一个大问题,是 chunk 一旦脱离原文上下文,就可能在检索时丢掉足够的信息;他们公开的实验里,Contextual Embeddings 与 Contextual BM25 可以把 failed retrieval 明显压低,叠加 reranking 后收益进一步扩大(Anthropic Contextual Retrieval,2026-03-19 验证)。

下面这张矩阵可以直接拿去做第一轮架构评审:
| 路线 | 什么时候优先选 | 当前最关键的 Claude 能力 | 什么时候别选 | 升级信号 |
|---|---|---|---|---|
| 直接长上下文 | 知识库仍偏小;问题偏总结、解释、抽取;强依赖引用 | Prompt Caching、Citations、PDF support | 文档持续扩张;问题开始依赖精确跨库定位 | 上下文塞不下、定位变慢、回答开始受召回不足影响 |
| 基础向量 RAG | 文档数量明显增加;需要先缩小候选范围;查询经常带产品名、版本号、错误码 | Claude 做回答与综合,外部检索做初筛 | 你还没确认长上下文路线是否已足够 | 经常“召回到了但排不准”,或 exact match 问题表现差 |
| 上下文化 RAG | 已做基础 RAG;召回率和排序仍不足;文档块离开原文就丢语义 | Claude 参与 chunk contextualization,配合 BM25、reranking | 你连基础 RAG 质量都还没摸清 | 检索日志里高频出现 false negative 或相关块排不进 top-K |
如果你只记住一句话,就记这句:别一开始就做最重的方案。 Claude 时代的文档问答,不再是“做不做 RAG”的二选一,而是“先从哪一层开始,再在什么信号下升级”的分层决策。
路线一:什么时候直接用长上下文 + prompt caching
这一条路线最容易被低估,因为它听起来不像“正规架构”,更像“先偷懒试试”。但很多团队第一次做知识库问答,真正需要的不是高度复杂的检索系统,而是一个能在有限知识范围里稳定回答、能引用依据、并且能被业务快速试用的第一版系统。
如果你的知识库还在中小规模,查询也更偏“解释一下这个流程”“总结这份文档的核心变化”“从这份 PDF 里抽取关键结论”,那么直接长上下文往往更省事。Anthropic 官方明确指出,小于约 200,000 tokens 的知识库可以先直接进 prompt(Anthropic Contextual Retrieval,2026-03-19 验证)。这不是拍脑袋的经验,而是官方已经把它写进对 RAG 的方法建议里。
这条路线的关键,不是“什么都不做”,而是把重点从检索工程转到上下文组织。你需要做的通常是:
- 先控制知识输入的边界,而不是盲目把所有文档都塞进来。
- 让系统对回答保持引用能力,而不是只追求回答流畅。
- 利用 prompt caching,让那些反复复用的系统指令、文档底稿或长上下文不要每次都完整重算。
Anthropic 当前的 prompt caching 价格结构也让这条路线更实际了。官方文档给出的规则是:缓存读取按基准输入价的 0.1x 计费,5 分钟缓存写入按 1.25x,1 小时缓存写入按 2x(Anthropic Prompt caching,2026-03-19 验证)。这意味着如果你的知识上下文会被频繁复用,直接长上下文不一定像旧印象里那样“注定贵得离谱”。
但这条路线也有清晰边界。它不适合文档持续滚雪球增长的场景,也不适合用户经常问“请找到第 17 版发布说明里关于某个错误码的原句”这种定位型问题。长上下文最擅长的是“把你已经给它的东西综合清楚”,而不是替代一套成熟的索引系统。你如果把它用到错误场景里,问题不是 Claude 不够强,而是你把检索责任塞给了不该承担这一步的层。
我自己的建议是:如果你在第一周就能把一个带引用的、回答稳定的长上下文版本交给业务试用,那通常比第一周就卷进 embedding 选型、向量库 schema 和 reranking 参数更有价值。先让团队知道“这个项目值不值得继续”,再决定要不要升级到下一层。
路线二:什么时候该做基础向量 RAG
当你开始发现长上下文已经不再稳定,基础向量 RAG 就该登场了。最典型的信号有三个:第一,知识库规模继续增长,单次请求不再适合直接带全量上下文;第二,用户问题越来越依赖精确定位,而不是宽泛总结;第三,你需要控制响应延迟和成本,不希望每次都把大段长文扔给模型。
基础向量 RAG 的本质,不是“把文档做成向量”这么简单,而是把系统拆成两个更合理的责任层:检索层先负责缩小候选范围,Claude 再负责基于候选材料做综合、归纳和表达。你做对了,系统会比长上下文路线更轻、更快,也更适合知识库持续增长的现实情况。
但这里也有一个常见误区:很多人一进入向量 RAG,就开始沉迷于“更换向量库”“调 chunk_size”“换 embedding 模型”这些局部优化,却忘了最先要回答的是“我的问题到底更像语义搜索,还是更像精确匹配”。如果用户经常问的是 SKU、版本号、错误码、法规条款编号,单纯依赖向量相似度本来就容易失手,因为它最擅长的是“意思相近”,不是“字符串完全命中”。
这也是为什么我更建议你把基础向量 RAG 看成一个过渡层,而不是终局设计。它适合:
- 你已经确认长上下文路线不够用。
- 你需要把候选文档先缩窄到一个合理范围。
- 你暂时还没有充分证据证明必须上更重的 contextual retrieval。
至于 embedding 方案,Anthropic 当前并不提供自有 embedding model(Anthropic Embeddings,2026-03-19 验证)。这意味着你在做基础向量 RAG 时,必须把“回答模型”和“embedding 方案”分开评估。Anthropic 文档把 Voyage AI 点成一个可参考的 embedding provider,但你最终仍应该在自己的中文语料上做小规模验证,而不是把任何一套英文博客里的 embedding 选型直接搬进生产。
如果你正在用 LangChain 或其他编排框架,也别把框架范式当成架构结论。框架能帮助你更快搭起 indexing 和 retrieval/generation 两层,但它不会替你判断是不是已经到了该做检索系统的时候。这一步判断,必须回到你的文档规模、问题类型和失败日志,而不是回到某个教程的默认模板。
路线三:什么时候升级到 Contextual Retrieval + reranking
很多团队在基础向量 RAG 上会遇到一个很烦的阶段:系统“不是完全不能用”,但就是不够稳。你明明知道答案在文档里,却经常召回不到;或者召回到了,但真正关键的 chunk 总排不到前几名。这时如果你只是继续调 k 值、继续换 chunk 大小,收益往往越来越小。
Anthropic 给出的 Contextual Retrieval 思路,正好是为了解决这类问题。它瞄准的是传统 chunking 的根本弱点:文档一旦被切成独立块,很多块会失去足够的上下文,导致 embedding 虽然捕捉到了某些语义,却捕不到那个块在整篇文档里的具体身份。Anthropic 的方法是让每个 chunk 在被 embedding 和做 BM25 之前,先被加上一段解释这个 chunk 所在文档上下文的“定位文本”(Anthropic Contextual Retrieval,2026-03-19 验证)。
这套方法的意义,不是神奇地让 Claude 变得更聪明,而是让检索层拿到的信息更完整。Anthropic 公开的实验结果里,Contextual Embeddings 加 Contextual BM25 能把 top-20 failed retrieval 从 5.7% 压到 2.9%;再叠加 reranking,可以进一步压到 1.9%(Anthropic Contextual Retrieval,2026-03-19 验证)。这些数字最重要的启发不是“你也一定能拿到同样结果”,而是它证明了一个方向:当你已经卡在检索质量,而不是回答质量时,升级检索前处理和排序机制,通常比继续堆回答 prompt 更有效。
但我不建议把这条路线提前默认化。Contextual Retrieval 不是“更高级的基础配置”,而是当你已经确认基础 RAG 不够稳时的定向升级。它会带来更多预处理、更多索引成本、更多评估工作,也会让系统更依赖你对检索日志和失败样本的理解。如果你连第一版失败模式都还没看清,这时就上 reranking 和 contextualization,很容易把系统做重,却不知道到底解决了什么问题。
所以升级到第三条路线前,我会要求团队先回答两个问题:
第一,你能不能用日志和样例清楚指出基础 RAG 是“召回不到”还是“排序不准”?
第二,你有没有一批能稳定复现的失败问题,可以用来做改造前后的对照评估?
如果这两个问题都答不出来,那你现在更需要的是评估和诊断,而不是继续加层。
一个当前可落地的 Claude 文档问答实现蓝图
真正能落地的实现蓝图,不该从“选哪个向量库”开始,而应该从“先选哪条架构路线”开始。我更建议按下面这个顺序推进。
第一步:先做架构分流
先用一张很朴素的判断表,把项目放进路线 1、路线 2 或路线 3。你至少要写清楚:
- 当前知识库总量大概多大。
- 用户问题更偏总结解释,还是更偏精确定位。
- 上线第一版最在意的是快上线、可引用,还是跨库高召回。
- 如果第一版做错了,最贵的代价是性能不够、成本过高,还是回答不可信。
第二步:把“回答可信”作为第一目标
无论走哪条路线,Claude 文档问答的第一版都不该只追求“回答像真人”。你真正要优先保住的是:回答能不能指出依据、能不能回到文档、能不能在回答不确定时明确收缩。对很多业务团队来说,这个优先级比“回答是否足够顺滑”更重要。
第三步:在需要向量 RAG 时,再单独做 embedding 评估
Anthropic 不提供自有 embedding model(Anthropic Embeddings,2026-03-19 验证),所以一旦你进入路线 2 或路线 3,就必须明确把 embedding 评估独立出来。别把“Claude 用得很好”错误地外推成“任何 embedding 方案都不会拖后腿”。
下面这个极简伪代码,比一上来贴整套框架代码更接近你真正该写的第一层逻辑:
pythondef choose_architecture(total_tokens, query_style, need_precise_lookup, retrieval_failures):
if total_tokens <= 200_000 and query_style in {"summary", "explain", "extract"}:
return "direct_context"
if need_precise_lookup and retrieval_failures == "not_measured":
return "basic_vector_rag"
if retrieval_failures in {"miss_relevant_chunks", "ranking_is_unstable"}:
return "contextual_rag"
return "basic_vector_rag"
它看起来简单,但它逼你先回答路线问题,而不是先沉迷于工具问题。
如果你需要把它进一步落成工程动作,我建议的最小执行顺序是:
- 先用
Claude Sonnet 4.6做第一版回答模型起点,因为它通常比 Opus 更均衡,也比 Haiku 更适合做复杂文档综合(Anthropic Choosing a model / Pricing,2026-03-19 验证)。 - 如果走路线 1,优先做引用、缓存和文档边界控制。
- 如果走路线 2,优先做检索日志和失败样本收集,而不是先做过度优化。
- 如果走路线 3,先用清晰评估集验证 contextual retrieval 与 reranking 是否真的带来收益。
你会发现,这个顺序比“先搭一套最全系统”更慢吗?通常恰恰相反。它更快,因为它少做了很多暂时不需要的层。
成本、模型和接入路径怎么判断
先把模型代际说清楚。Anthropic 当前公开主语境是 Claude Opus 4.6 / Claude Sonnet 4.6 / Claude Haiku 4.5,而不是很多旧教程反复出现的 Claude 3.5(Anthropic Choosing a model,2026-03-19 验证)。对应价格结构,官方定价页当前列出的主档位是:Opus 输入 $5 / 输出 $25、Sonnet 输入 $3 / 输出 $15、Haiku 输入 $1 / 输出 $5,单位均为每百万 token(Anthropic Pricing,2026-03-19 验证)。
对大多数文档问答项目,我更建议把模型选择理解成“你在哪一层省钱”,而不是“永远挑最便宜的那个”。如果你的主要成本来自大段上下文复用,先看 prompt caching 往往比先把回答模型一口气降档更有效;如果你的主要成本来自错误召回导致的反复重试,那你最该优化的也不是模型单价,而是检索路径。
接入路径也别只看“哪个 base URL 更方便”。如果你需要的是 Anthropic 官方原生能力和最清晰的排障边界,优先走官方文档与原生接口;如果你还在比较多模型接入、统一余额和国内团队协作效率,那么第三方聚合层才更像工程效率工具,而不是默认真理。
以 LaoZhang 当前公开文档为例,它现在公开强调的是 https://api.laozhang.ai/v1 这一统一入口、/v1/models 作为模型目录接口、pay-as-you-go 和 200+ AI models(LaoZhang Index / Models API,2026-03-19 验证)。这些信息足以支持“把它当作统一接入层来评估”,但不足以支持“所有 Claude RAG 场景统一省 65%”这种绝对化结论。所以这篇文章不会再把“省多少钱”写成 thesis,而是把它降回一条接入判断。
如果你接下来要单独看价格、限流和接入路径,可以继续补下面几篇:
这些文章和本文的关系应该是分工,而不是替代。本文先帮你做架构分流,接入和计费细节再由各自文章继续展开。
上线前要验哪 6 件事
一套 Claude 文档问答系统能在演示环境里回出一段文字,不代表它已经适合上线。真正值得你在交付前逐项确认的,是下面这 6 件事。
第一,文档规模到底有没有把你推到错误路线。如果你明明还在中小知识库阶段,却已经上了完整向量检索和多层 reranking,先别急着庆祝“架构先进”,先问自己是不是跳过了最该节省的复杂度。
第二,你要的到底是引用,还是召回。很多团队混淆这两个目标,结果一边在补检索,一边又抱怨回答不可信。实际上,这往往是两个不同层级的问题:检索层解决“有没有找到”,引用层解决“回答凭什么可信”。
第三,embedding 方案是不是单独验证过。只要你进入路线 2 或路线 3,这一步就不能偷懒。你的回答模型再好,也不会替 embedding 方案自动兜底。
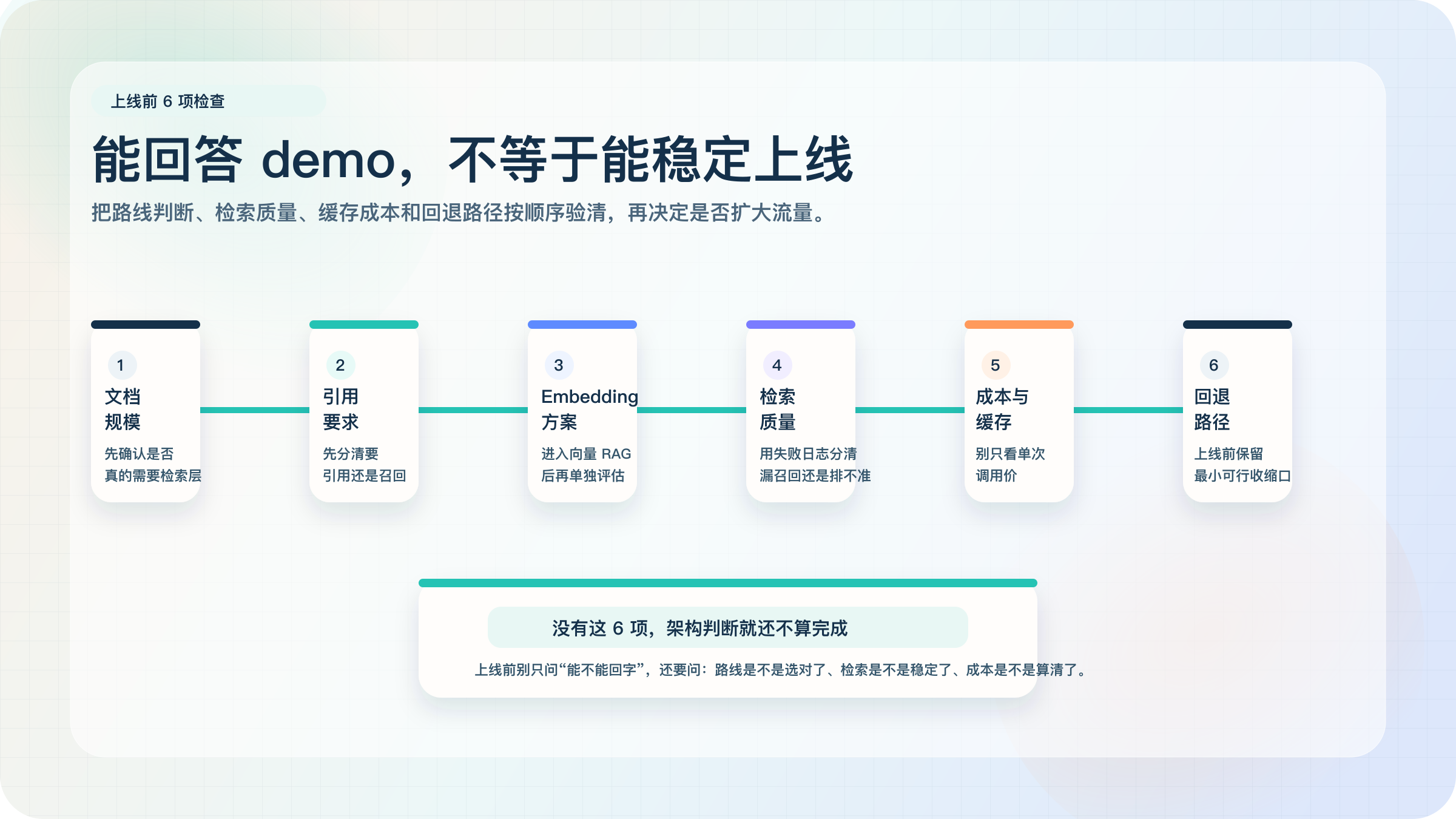
第四,检索质量有没有被日志化。不要只听主观感受说“有时候不准”,而要能回到失败样本,判断到底是召回不到、排序不准,还是回答链把已召回信息用坏了。
第五,成本与缓存有没有拆开算。缓存能显著影响长上下文路线的真实成本,而检索失败导致的重试也会改变向量 RAG 路线的真实花费。如果你把这些都混成“每次调用单价”,成本判断会非常粗糙。
第六,回退路径有没有预先留好。即使你最终决定上聚合层或更重的 RAG 架构,也应该保留一条最小可行的回退入口。真正可上线的系统,不是从不出错的系统,而是出错后仍有收缩路径的系统。
如果你把这 6 件事都验过,再来谈“我的 Claude RAG 架构成熟了”,这句话才更有分量。
常见问题
现在做 Claude 文档问答,还需要向量库吗?
不一定。关键不在于“Claude 强不强”,而在于你的知识库规模和问题类型。如果知识库仍在约 200,000 tokens 以内,而且问题偏总结、解释、抽取,Anthropic 官方已经明确给出过“可以先直接进 prompt”的判断(Anthropic Contextual Retrieval,2026-03-19 验证)。这时你更该优先做好的是上下文组织、引用和缓存,而不是默认先上向量库。
Citations 和传统 source_documents 思路有什么本质区别?
传统教程里的 source_documents 更像“我把检索块顺便回给你看”,而 Claude 当前原生的 citations 更接近“模型在回答内部就携带依据关系”(Anthropic Citations,2026-03-19 验证)。对上线系统来说,这个区别很重要。前者更像调试信息,后者更像面向终端用户的可信回答结构。你如果真正关心“用户能不能看懂回答依据”,原生引用能力通常比简单附上一堆 chunk 更有产品价值。
Anthropic 不提供 embedding model,我该怎么做向量 RAG?
做法不是换一个回答模型,而是把 embedding 评估独立出来。Anthropic 当前文档明确写明它不提供自有 embedding model,并把 Voyage AI 作为一个可参考的候选提供方(Anthropic Embeddings,2026-03-19 验证)。但这不意味着你应该机械照抄某个 provider。更稳的动作是:拿你自己的中文语料做小样本验证,重点看召回率、错误码类问题的 exact match 表现,以及升级到 reranking 前的基线质量。
Prompt Caching 会不会只是“看起来便宜”,实际没什么用?
这要看你的上下文是不是会被重复使用。Anthropic 当前公开规则里,cache read 按基准输入价的 0.1x 计费,5 分钟缓存写入按 1.25x,1 小时缓存写入按 2x(Anthropic Prompt caching,2026-03-19 验证)。如果你的系统提示词、文档底稿或长期对话上下文会频繁复用,这个能力能显著改善长上下文路线的成本和延迟;如果你的每次请求上下文都完全不同,它的价值就会弱得多。
我已经做了基础向量 RAG,什么时候才值得上 Contextual Retrieval?
当你能够用失败样本清楚证明:系统不是“偶尔答不好”,而是“经常漏召回关键块”或“相关块排不到前面”。Anthropic 公布的实验结果说明,Contextual Retrieval 更像检索层升级,而不是回答层调参(Anthropic Contextual Retrieval,2026-03-19 验证)。所以它值不值得上,不取决于它听起来多先进,而取决于你是否已经识别到典型检索失效模式。
中国团队做 Claude 文档问答,应该一开始就用聚合层吗?
也不该默认。一条更稳的原则是:先决定你的架构路线,再决定你的接入路径。如果你当前只是想快速评估多模型、统一接入、降低协作摩擦,那么像 LaoZhang 这种公开提供 https://api.laozhang.ai/v1 和 /v1/models 的聚合层可以进入候选(LaoZhang Index / Models API,2026-03-19 验证)。但如果你的项目强依赖 Anthropic 原生能力和官方排障边界,那聚合层就不该因为“更方便”而自动升级成默认答案。接入层应该服务架构,而不是反过来绑架架构。