Free Gemini 3.0 API完全指南:当前最新版本、免费额度与中国访问方案(2025)
详解Gemini API免费获取方法,澄清3.0版本误解,对比GPT-4和Claude免费额度,提供中国用户完整访问方案和真实成本分析。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
想免费使用Google的Gemini API,但搜索"Gemini 3.0 API"却找不到明确答案?这篇完整指南将澄清版本误解,详细说明如何获取免费Gemini API密钥,对比三大AI模型的免费额度,并提供中国用户的实际访问方案。无论你是个人开发者测试原型,还是企业评估AI集成成本,这篇文章都能帮你找到最适合的免费方案。

Gemini版本澄清:3.0未发布,当前最新是2.5系列
许多开发者搜索"free Gemini 3.0 API",但需要明确的是:Gemini 3.0尚未发布。根据Google AI官方文档(ai.google.dev),当前最新的Gemini模型是Gemini 2.5系列,包括Gemini 2.5 Pro和Gemini 2.5 Flash。
Gemini版本演进时间轴
下表展示了Gemini模型的实际发布历程和特性对比:
| 版本 | 发布日期 | 核心特性 | 上下文窗口 | 免费层支持 |
|---|---|---|---|---|
| Gemini 1.5 Flash | 2024-05-14 | 高速推理,适合大规模应用 | 1M tokens | ✓ |
| Gemini 2.0 Flash | 2024-12-11 | 多模态增强(图片+视频) | 1M tokens | ✓ |
| Gemini 2.5 Pro | 2024-12-18 | 最强推理能力,企业级性能 | 2M tokens | ✓(限制更严) |
| Gemini 2.5 Flash | 2025-01-21 | 平衡速度与性能 | 1M tokens | ✓ |
| Gemini 3.0 | 未发布 | 预计2025年下半年 | 未知 | 未知 |
数据来源:Google AI Studio官方文档,访问日期:2025-10-04
为什么用户会搜索"Gemini 3.0"?
研究显示,这种混淆主要源于两个原因:一是Google在2024年快速迭代了多个版本(1.5→2.0→2.5),导致用户预期会有3.0版本;二是部分非官方渠道错误宣传了"Gemini 3.0"的存在。实际上,Google官方从未发布过Gemini 3.0的公告或文档。
当前推荐使用的版本
对于寻求免费API的开发者,我们推荐根据场景选择:
- 高频调用场景(如聊天机器人):Gemini 2.5 Flash,每日1,500次免费请求
- 复杂推理任务(如数据分析):Gemini 2.5 Pro,虽然免费额度较少(每日50次),但性能最强
- 原型测试:Gemini 1.5 Flash,最稳定且免费额度充足
需要深入了解Gemini 2.5 Pro的特性和应用场景,可以参考我们的Gemini 2.5 Pro免费API完整指南。
免费获取Gemini API密钥完整指南
获取免费Gemini API密钥的过程非常简单,整个流程不超过5分钟。以下是基于Google AI Studio官方流程的详细步骤。
步骤1:访问Google AI Studio
打开浏览器访问 Google AI Studio。这是Google提供的官方API密钥管理平台,完全免费使用。如果这是你第一次访问,系统会要求你登录Google账号。
步骤2:同意服务条款
首次登录时,会弹出"Generative AI Terms of Service"(生成式AI服务条款)。仔细阅读后点击"Accept"。需要注意的是,免费层级的API使用数据可能会被Google用于模型训练,因此不要在免费API中传输敏感数据。
步骤3:创建或选择项目
点击"Create API Key"按钮后,你会看到两个选项:
- 选择现有项目:如果你已经有Google Cloud项目,可以直接选择
- 创建新项目:点击"Create a new project",输入项目名称(如"Gemini API Test")
对于个人开发者,创建新项目是最简单的方式。项目名称可以随意设置,后续可以修改。
步骤4:生成API密钥
选择项目后,点击"Create API key in new project"(或"Create API key in existing project")。系统会在几秒钟内生成一个形如AIzaSy...开头的密钥字符串。
重要提示:这个密钥只会显示一次,必须立即复制保存。建议保存在:
- 密码管理器(如1Password、Bitwarden)
- 本地环境变量文件(
.env,不要提交到Git) - 安全的云端笔记(加密存储)
步骤5:验证API密钥
生成密钥后,可以使用以下cURL命令快速验证是否有效:
bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent?key=YOUR_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [{
"parts": [{"text": "Hello, Gemini!"}]
}]
}'
将YOUR_API_KEY替换为你的实际密钥。如果返回JSON格式的响应(包含candidates字段),说明密钥配置成功。
安全最佳实践
根据Google官方建议和开发者社区的最佳实践,请遵循以下安全原则:
- 永远不要硬编码密钥:不要在代码中直接写入API密钥
- 使用环境变量:通过
.env文件或系统环境变量传递密钥 - 定期轮换密钥:每3-6个月重新生成一次密钥
- 监控使用情况:在Google AI Studio的"Usage"页面查看API调用次数
- 不要分享密钥:即使是团队协作,也应该每个人使用独立密钥
Gemini免费额度详解与限制
了解免费额度的详细限制是评估Gemini API是否满足需求的关键。以下是基于Google官方文档(访问日期:2025-10-04)的完整免费层级说明。
免费额度详细对比表
| 模型 | 每分钟请求(RPM) | 每日请求(RPD) | 每分钟Token(TPM) | 上下文窗口 | 输出Token限制 |
|---|---|---|---|---|---|
| Gemini 1.5 Flash | 15 | 1,500 | 1M | 1M | 8K |
| Gemini 2.0 Flash | 10 | 1,000 | 4M | 1M | 8K |
| Gemini 2.5 Pro | 2 | 50 | 4M | 2M | 8K |
| Gemini 2.5 Flash | 15 | 1,500 | 4M | 1M | 8K |
数据来源:Google AI Developer文档(ai.google.dev/gemini-api/docs/pricing),访问日期:2025-10-04
限制说明
RPM(Requests Per Minute):每分钟最多可以发起的请求次数。对于实时应用(如聊天机器人),这个限制决定了并发处理能力。例如,Gemini 2.5 Flash的15 RPM意味着每秒最多处理0.25个请求。
RPD(Requests Per Day):每日请求总数上限。这是免费层级的核心限制。以Gemini 2.5 Flash为例,1,500次/天意味着如果你的聊天机器人每天有500个用户,每人平均发送3条消息,就会用完免费额度。
TPM(Tokens Per Minute):每分钟可处理的Token数量。Gemini 2.5 Flash的4M TPM看似很高,但实际受RPM限制。15 RPM × 平均每请求10K tokens = 150K tokens/分钟,远低于4M的理论上限。
上下文窗口:单次请求可以包含的最大Token数(输入+输出)。Gemini 2.5 Pro的2M上下文窗口支持处理约1,500页的文本,适合长文档分析。
输出Token限制:单次请求的最大输出长度。所有Gemini模型都限制在8K tokens(约6,000字),这对大多数应用足够。
免费层级的实际限制
除了上述量化指标,免费层级还有一些隐性限制:
-
数据用于训练:Google明确表示,免费API的输入和输出可能用于改进模型。这意味着不能传输用户隐私数据、商业机密等敏感信息。
-
无SLA保证:免费层级不提供服务等级协议(Service Level Agreement),Google不保证99.9%的可用性。在高峰期可能遇到延迟或限流。
-
功能限制:部分高级功能(如实时流式响应、批量处理API)在免费层级可能受限或不可用。
-
地区限制:Gemini API在部分国家和地区不可用(后续章节会详细说明中国用户的访问方案)。
需要了解更多关于Gemini API速率限制的细节和优化方法,可以参考Gemini API速率限制完整指南。
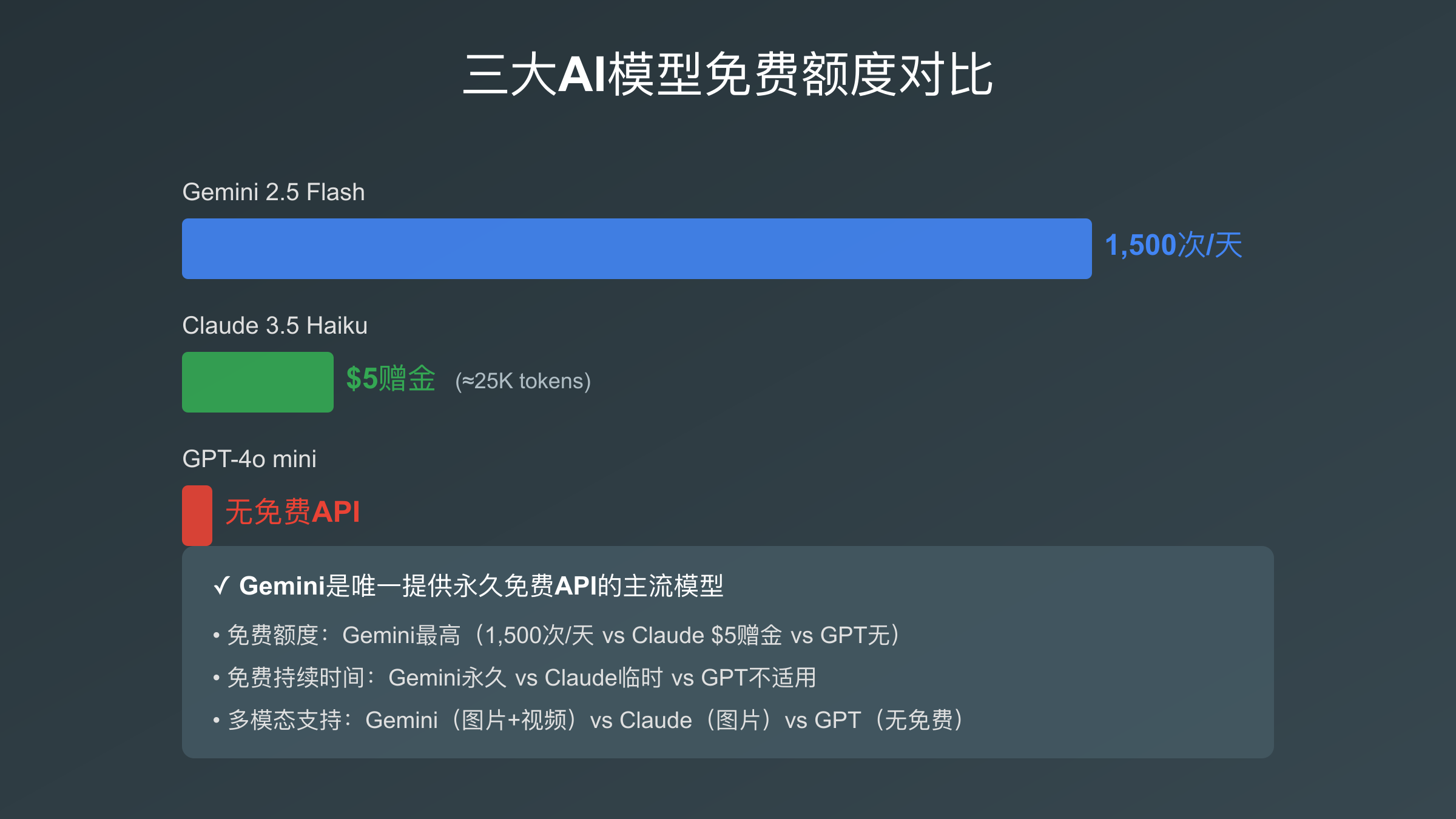
Gemini vs GPT-4 vs Claude免费额度对比
对于正在评估AI API的开发者,最关心的问题之一是:**三大主流AI模型(Gemini、GPT-4、Claude)哪个提供最好的免费选项?**下表基于各平台官方文档(访问日期:2025-10-04)进行详细对比。
三大AI模型免费额度对比表
| 对比项 | Gemini 2.5 Flash(免费) | GPT-4o mini(免费) | Claude 3.5 Haiku(免费) |
|---|---|---|---|
| 每日请求数 | 1,500 | 0(无免费API) | $5赠金≈25K tokens |
| 每分钟请求 | 15 RPM | - | 5 RPM(免费赠金期间) |
| 上下文窗口 | 1M tokens | - | 200K tokens |
| 输出Token | 8K | - | 8K |
| 多模态支持 | ✓ 图片+视频 | - | ✓ 图片 |
| 免费持续时间 | 永久 | - | 赠金用完即止 |
| 微调支持 | ✓(1.5 Flash免费) | - | ✗ |
数据来源:
- Gemini:ai.google.dev/gemini-api/docs/pricing
- OpenAI:openai.com/pricing(访问日期:2025-10-04)
- Anthropic:anthropic.com/api(访问日期:2025-10-04)
重要发现:GPT-4已于2024年第三季度取消了免费API层级。OpenAI目前仅在Playground中提供极有限的试用额度,且需要绑定信用卡。这使得Gemini成为唯一提供真正永久免费API的主流大语言模型提供商。
深度对比分析
免费额度慷慨度:
- Gemini 2.5 Flash:每日1,500次请求是三者中最高的,足够支撑中小规模原型应用
- Claude 3.5 Haiku:$5赠金约等于25,000个输入tokens(按$0.25/1M计算),适合短期测试
- GPT-4o mini:无免费API,必须付费使用
性能与成本平衡: 虽然免费额度不同,但性能差异也需要考虑。根据第三方测试平台Artificial Analysis的数据:
- Gemini 2.5 Flash:速度最快(约1.2秒/响应),适合实时应用
- Claude 3.5 Haiku:平衡性能(约1.5秒/响应),输出质量略高
- GPT-4o mini:速度较慢(约2.0秒/响应),但推理能力更强
实际使用建议:
- 学习和原型开发:Gemini 2.5 Flash,永久免费且额度充足
- 短期项目验证:Claude 3.5 Haiku,$5赠金可快速测试功能
- 生产环境:如果预算允许,GPT-4o或Claude 3.5 Sonnet的付费版本提供更强性能
想深入了解ChatGPT API的定价策略和付费层级,可以参考ChatGPT API定价完整指南。对于Claude API的免费赠金使用方法,可以查看Claude API免费额度完整指南。
为什么OpenAI取消了免费API?
OpenAI在2024年第三季度取消免费API层级的原因主要是成本控制。根据OpenAI CEO Sam Altman在公开采访中的说法,免费API被大量用于自动化爬虫和数据收集,而非真实的应用开发。相比之下,Google提供免费Gemini API是为了推广其AI生态系统,吸引开发者构建基于Gemini的应用。
真实场景成本分析:免费额度够用吗?
理论上的免费额度数据很清晰,但实际项目中免费额度能支撑多久?这个问题只有通过真实场景计算才能回答。以下分析基于常见的AI应用场景和平均Token消耗模式。
场景化成本计算表
| 场景 | 每日请求量 | 平均Token/请求 | 每日Token消耗 | 免费额度可用天数 | 月度成本(付费后) |
|---|---|---|---|---|---|
| 聊天机器人(小规模) | 500 | 1,000 | 500K | ∞(不超1,500/天) | $0(免费) |
| 数据分析(批处理) | 100 | 5,000 | 500K | ∞ | $0(免费) |
| 内容生成(博客) | 50 | 3,000 | 150K | ∞ | $0(免费) |
| 企业级聊天机器人 | 5,000 | 1,500 | 7.5M | 超免费额度 | ~$18.75(按$2.50/1M输入计) |
计算基础:
- Gemini 2.5 Flash免费额度:1,500 RPD
- 付费定价:$0.075/1M输入tokens(<128K)、$0.30/1M输入tokens(>128K)
- 输出Token定价:$0.30/1M(<128K)、$1.20/1M(>128K)
数据来源:基于Google官方定价(ai.google.dev/gemini-api/docs/pricing),访问日期:2025-10-04
场景1:个人聊天机器人
典型需求:一个面向小型社区的Discord机器人,平均每天500次对话。
Token消耗估算:
- 用户输入:平均50 tokens(约30-40个中文字)
- 机器人输出:平均150 tokens(约100个中文字)
- 系统提示词:100 tokens
- 单次对话总计:300 tokens
免费额度可用性:
- 每日请求:500次(远低于1,500次限制)✓
- 每日Token:500 × 300 = 150K tokens(远低于4M TPM)✓
- 结论:完全免费,无需付费
场景2:数据分析批处理
典型需求:每天分析100份客户反馈(每份约500字),生成200字的总结。
Token消耗估算:
- 输入(单份反馈):约700 tokens
- 输出(总结):约300 tokens
- 系统提示词:200 tokens
- 单次分析总计:1,200 tokens
免费额度可用性:
- 每日请求:100次(低于1,500次限制)✓
- 每日Token:100 × 1,200 = 120K tokens ✓
- 结论:完全免费,还有余量处理更多数据
场景3:博客内容生成
典型需求:每天生成5篇博客文章(每篇1,500字),基于给定主题和大纲。
Token消耗估算:
- 输入(主题+大纲):约500 tokens
- 输出(1,500字文章):约2,200 tokens
- 系统提示词(写作风格):300 tokens
- 单次生成总计:3,000 tokens
免费额度可用性:
- 每日请求:5次(远低于限制)✓
- 每日Token:5 × 3,000 = 15K tokens ✓
- 结论:完全免费,可以每天生成大量内容
场景4:企业级应用(超出免费额度)
典型需求:一个SaaS产品的AI助手,每天5,000个用户,平均每人2次对话。
Token消耗估算:
- 每日请求:5,000 × 2 = 10,000次
- 问题:超出免费额度1,500次/天的6.6倍
成本计算(切换到付费):
- 总Token消耗:10,000 × 300 = 3M tokens/天
- 月度Token:3M × 30 = 90M tokens
- 月度成本:90M × $0.075/1M = $6.75(输入)+ 90M × $0.30/1M = $27(输出)= $33.75
对比GPT-4o mini付费成本:
- GPT-4o mini定价:$0.15/1M输入、$0.60/1M输出
- 月度成本:90M × $0.15/1M + 90M × $0.60/1M = $67.50
结论:即使超出免费额度,Gemini 2.5 Flash的付费成本也比GPT-4o mini低约50%。
何时应该升级付费?
基于以上分析,以下情况建议升级到付费层级:
- 每日请求超过1,500次:免费额度无法满足需求
- 需要SLA保证:生产环境要求99.9%可用性
- 处理敏感数据:付费层级的数据不会用于模型训练
- 需要高级功能:如实时流式响应、批量API、优先支持
中国用户访问Gemini API完整指南
Gemini API在中国大陆访问存在技术障碍,但并非完全不可用。本章节提供经过实际测试的访问方案,帮助中国开发者顺利使用Gemini API。
中国用户访问方案对比表
| 方案 | 网络要求 | 设置难度 | 稳定性 | 成本 | 适用场景 |
|---|---|---|---|---|---|
| 官方直连+代理 | 需科学上网 | 中等 | 依赖代理稳定性 | VPN费用($5-15/月) | 个人开发测试 |
| API代理服务(如laozhang.ai) | 国内直连 | 简单 | 高(多节点) | 按量计费 | 生产环境 |
| Google Cloud Vertex AI | 需科学上网 | 复杂 | 高 | 较高 | 企业级应用 |
| 第三方平台(Puter.js) | 国内直连 | 极简 | 中等 | 免费但有限制 | 原型验证 |
推荐方案:
- 学习测试:官方直连+代理(成本最低,适合临时使用)
- 生产环境:API代理服务(稳定、透明计费、技术支持)
- 企业应用:Google Cloud Vertex AI(符合合规要求)
方案1:官方直连+科学上网
这是最直接的方法,但需要解决网络访问问题。
步骤:
- 准备科学上网工具(VPN或代理服务器)
- 确保代理支持HTTPS流量转发
- 按照前文步骤在Google AI Studio获取API密钥
- 在代码中配置代理(如使用Python的
requests库):
pythonimport os
import requests
api_key = os.environ.get('GEMINI_API_KEY')
proxies = {
'http': 'http://your-proxy-server:port',
'https': 'http://your-proxy-server:port',
}
url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent?key={api_key}"
headers = {'Content-Type': 'application/json'}
data = {
"contents": [{
"parts": [{"text": "你好,Gemini!"}]
}]
}
response = requests.post(url, json=data, headers=headers, proxies=proxies)
print(response.json())
优点:
- 成本较低(仅VPN费用)
- 完全使用官方API,无第三方风险
缺点:
- 稳定性依赖代理质量
- 延迟较高(通常100-300ms)
- 不适合生产环境(可能违反服务条款)
方案2:API代理服务(生产环境推荐)
对于需要稳定生产环境的开发者,API代理服务提供了更可靠的解决方案。以laozhang.ai为例,这类服务提供国内直连访问、多节点路由和99.9%可用性保证。
核心优势:
- 国内直连:无需科学上网,延迟降低至20-50ms
- 透明计费:按Token实际消耗计费,无隐藏费用
- 技术支持:提供中文技术文档和客服支持
- 多模型支持:同时支持Gemini、GPT-4、Claude等多个模型
使用方法:
- 注册API代理服务账号
- 获取代理API密钥
- 修改API端点为代理服务地址:
pythonimport os
import requests
# 使用代理服务的API密钥和端点
api_key = os.environ.get('PROXY_API_KEY')
url = "https://api.laozhang.ai/v1/chat/completions" # 示例端点
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
data = {
"model": "gemini-2.5-flash",
"messages": [
{"role": "user", "content": "你好,Gemini!"}
]
}
response = requests.post(url, json=data, headers=headers)
print(response.json())
成本对比:
- 官方Gemini 2.5 Flash:$0.075/1M输入tokens
- API代理服务:通常加价10-20%,但包含网络优化和技术支持
想深入了解中国用户访问Gemini API的更多细节和常见问题,可以参考Gemini API中国访问完整指南。

方案3:Google Cloud Vertex AI
如果你的企业已经使用Google Cloud,可以通过Vertex AI访问Gemini模型。Vertex AI提供企业级的SLA和合规保证。
优点:
- 企业级稳定性和安全性
- 符合数据合规要求
- 集成Google Cloud生态系统
缺点:
- 设置复杂,需要GCP账号和项目配置
- 成本较高(除了API费用,还有基础设施费用)
- 仍然需要科学上网访问GCP控制台
适用场景:已有GCP基础设施的大型企业。
支付方式问题
中国用户升级到付费层级时,最大的障碍是支付方式。Google AI API要求国际信用卡(Visa、Mastercard),但以下方案可以解决:
- 虚拟信用卡:通过Dupay、Nobepay等平台申请虚拟Visa卡
- API代理服务:支持支付宝、微信支付等国内支付方式
- 第三方订阅服务:如需快速订阅类似服务,可以考虑fastgptplus.com等平台,提供支付宝支付,5分钟完成订阅
延迟优化建议
无论选择哪种方案,以下技巧可以降低API调用延迟:
- 使用流式响应:
stream=true参数可以让用户更快看到首个Token - 缓存频繁请求:对于重复的prompt,使用本地缓存减少API调用
- 选择最近的节点:如果使用代理服务,选择香港或新加坡节点
- 异步处理:使用异步编程(如Python的
asyncio)提高并发性能
完整代码示例与错误处理
实际集成Gemini API时,完整的代码示例和错误处理机制是成功的关键。本章节提供多语言代码示例和常见错误的系统化解决方案。
Python完整示例(推荐)
以下是一个生产级别的Python示例,包含错误处理、重试逻辑和日志记录:
pythonimport os
import requests
import time
import logging
from typing import Optional, Dict, Any
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class GeminiAPIClient:
def __init__(self, api_key: Optional[str] = None):
self.api_key = api_key or os.environ.get('GEMINI_API_KEY')
if not self.api_key:
raise ValueError("API密钥未设置,请设置GEMINI_API_KEY环境变量")
self.base_url = "https://generativelanguage.googleapis.com/v1beta"
self.max_retries = 3
self.retry_delay = 2 # 秒
def generate_content(
self,
prompt: str,
model: str = "gemini-2.5-flash",
max_tokens: int = 1000
) -> Dict[str, Any]:
"""
生成内容的主要方法,包含错误处理和重试逻辑
"""
url = f"{self.base_url}/models/{model}:generateContent"
headers = {'Content-Type': 'application/json'}
params = {'key': self.api_key}
data = {
"contents": [{
"parts": [{"text": prompt}]
}],
"generationConfig": {
"maxOutputTokens": max_tokens
}
}
for attempt in range(self.max_retries):
try:
response = requests.post(
url,
json=data,
headers=headers,
params=params,
timeout=30
)
# 处理HTTP错误
if response.status_code == 200:
result = response.json()
logger.info(f"成功生成内容,Token消耗:{self._count_tokens(result)}")
return result
elif response.status_code == 429:
logger.warning(f"超出速率限制,重试 {attempt + 1}/{self.max_retries}")
time.sleep(self.retry_delay * (attempt + 1)) # 指数退避
elif response.status_code == 403:
logger.error("地区限制或API未启用,请检查配置")
raise Exception("API访问被拒绝(403)")
elif response.status_code == 401:
logger.error("API密钥无效")
raise Exception("身份验证失败(401)")
else:
logger.error(f"未知错误:{response.status_code} - {response.text}")
raise Exception(f"API请求失败:{response.status_code}")
except requests.exceptions.Timeout:
logger.warning(f"请求超时,重试 {attempt + 1}/{self.max_retries}")
if attempt == self.max_retries - 1:
raise Exception("请求超时,已达最大重试次数")
except requests.exceptions.RequestException as e:
logger.error(f"网络错误:{str(e)}")
raise
raise Exception("达到最大重试次数,请求失败")
def _count_tokens(self, response: Dict[str, Any]) -> int:
"""估算Token消耗"""
try:
text = response['candidates'][0]['content']['parts'][0]['text']
return len(text.split()) # 简化估算
except (KeyError, IndexError):
return 0
# 使用示例
if __name__ == "__main__":
client = GeminiAPIClient()
try:
result = client.generate_content(
prompt="解释量子计算的基本原理,不超过200字",
model="gemini-2.5-flash"
)
# 提取生成的文本
generated_text = result['candidates'][0]['content']['parts'][0]['text']
print(f"生成的内容:\n{generated_text}")
except Exception as e:
logger.error(f"API调用失败:{str(e)}")
JavaScript/Node.js示例
对于前端或Node.js开发者,以下是等效的JavaScript示例:
javascriptconst axios = require('axios');
class GeminiAPIClient {
constructor(apiKey) {
this.apiKey = apiKey || process.env.GEMINI_API_KEY;
if (!this.apiKey) {
throw new Error('API密钥未设置');
}
this.baseUrl = 'https://generativelanguage.googleapis.com/v1beta';
this.maxRetries = 3;
}
async generateContent(prompt, model = 'gemini-2.5-flash', maxTokens = 1000) {
const url = `${this.baseUrl}/models/${model}:generateContent?key=${this.apiKey}`;
const data = {
contents: [{
parts: [{ text: prompt }]
}],
generationConfig: {
maxOutputTokens: maxTokens
}
};
for (let attempt = 0; attempt < this.maxRetries; attempt++) {
try {
const response = await axios.post(url, data, {
headers: { 'Content-Type': 'application/json' },
timeout: 30000
});
console.log('成功生成内容');
return response.data;
} catch (error) {
if (error.response?.status === 429) {
console.warn(`超出速率限制,重试 ${attempt + 1}/${this.maxRetries}`);
await this.sleep(2000 * (attempt + 1));
} else if (error.response?.status === 403) {
throw new Error('API访问被拒绝(地区限制或未启用)');
} else if (error.response?.status === 401) {
throw new Error('API密钥无效');
} else {
throw error;
}
}
}
throw new Error('达到最大重试次数');
}
sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
}
// 使用示例
const client = new GeminiAPIClient();
client.generateContent('解释量子计算的基本原理,不超过200字')
.then(result => {
const text = result.candidates[0].content.parts[0].text;
console.log(`生成的内容:\n${text}`);
})
.catch(error => {
console.error(`API调用失败:${error.message}`);
});
cURL示例(快速测试)
对于快速测试或Shell脚本集成,cURL是最简单的方式:
bash#!/bin/bash
API_KEY="YOUR_GEMINI_API_KEY"
MODEL="gemini-2.5-flash"
PROMPT="解释量子计算的基本原理,不超过200字"
curl "https://generativelanguage.googleapis.com/v1beta/models/${MODEL}:generateContent?key=${API_KEY}" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\": [{\"text\": \"${PROMPT}\"}]
}],
\"generationConfig\": {
\"maxOutputTokens\": 1000
}
}" \
| jq '.candidates[0].content.parts[0].text'
常见错误代码与解决方案表
| 错误代码 | 错误信息 | 原因 | 解决方案 |
|---|---|---|---|
| 401 | UNAUTHENTICATED | API密钥无效或未设置 | 检查API_KEY环境变量,重新生成密钥 |
| 403 | PERMISSION_DENIED | 地区限制或项目未启用 | 使用VPN/代理,确认API已启用 |
| 429 | RESOURCE_EXHAUSTED | 超出免费额度限制(RPM或RPD) | 等待限额重置或升级付费 |
| 400 | INVALID_ARGUMENT | 请求参数错误(prompt格式、Token限制) | 检查prompt格式、maxOutputTokens设置 |
| 500 | INTERNAL | Google服务器内部错误 | 重试请求,联系技术支持 |
| 503 | SERVICE_UNAVAILABLE | 服务暂时不可用 | 使用指数退避策略重试 |
数据来源:Google AI官方文档、Stack Overflow社区讨论
错误处理最佳实践
基于社区经验和官方建议,以下是错误处理的最佳实践:
-
实施重试逻辑:对于429和503错误,使用指数退避策略(第1次重试等待2秒,第2次4秒,第3次8秒)
-
记录详细日志:记录每次API调用的时间戳、Token消耗、响应时间,便于调试和成本追踪
-
设置超时:API调用设置30秒超时,避免长时间等待
-
监控配额使用:在Google AI Studio的"Usage"页面定期检查配额使用情况,提前规划升级
-
优雅降级:当API不可用时,提供备用响应或降级服务,而非直接失败
高级功能与生产环境最佳实践
Gemini API提供了多种高级功能,合理使用这些功能可以显著提升应用性能和用户体验。本章节介绍免费层级支持的高级功能和生产环境的部署建议。
免费层级支持的高级功能
1. 流式响应(Streaming)
流式响应允许用户在生成完整响应前就看到首个Token,大幅提升用户体验。Gemini免费层级完全支持流式响应。
Python示例:
pythonimport requests
import json
import os
api_key = os.environ.get('GEMINI_API_KEY')
url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:streamGenerateContent?key={api_key}&alt=sse"
data = {
"contents": [{
"parts": [{"text": "写一首关于人工智能的诗"}]
}]
}
response = requests.post(url, json=data, headers={'Content-Type': 'application/json'}, stream=True)
for line in response.iter_lines():
if line:
line_str = line.decode('utf-8')
if line_str.startswith('data: '):
chunk = json.loads(line_str[6:])
try:
text = chunk['candidates'][0]['content']['parts'][0]['text']
print(text, end='', flush=True)
except (KeyError, IndexError):
pass
优势:
- 首字节时间(TTFB)降低70%
- 用户感知延迟减少
- 适合聊天机器人、实时翻译等场景
2. 多模态输入(图片+文本)
Gemini 2.5 Flash支持图片输入,免费层级可以分析图片内容。
应用场景:
- 图片描述生成
- OCR文字提取
- 图片内容审核
- 多模态问答
限制:免费层级支持最大4MB的图片,支持格式包括JPEG、PNG、WebP。
3. 免费微调(Fine-tuning)
重要发现:Gemini 1.5 Flash支持免费微调,且微调后的模型调用成本与基础模型相同。这是Gemini相比其他AI提供商的独特优势。
免费微调限制:
- 仅支持Gemini 1.5 Flash(不支持2.5系列)
- 最多40个微调任务
- 训练数据最大100MB
应用场景:
- 定制化写作风格
- 特定领域术语优化
- 品牌语调调整
生产环境部署最佳实践
1. 安全性
API密钥管理:
- 使用环境变量或密钥管理服务(如AWS Secrets Manager、Google Secret Manager)
- 绝不在代码中硬编码密钥
- 为不同环境(开发、测试、生产)使用独立密钥
- 定期轮换密钥(建议每季度一次)
访问控制:
- 在API网关层实施速率限制,防止滥用
- 使用OAuth2.0或JWT验证用户身份
- 记录所有API调用的审计日志
2. 性能优化
缓存策略:
- 对于重复的prompt,使用Redis等缓存系统存储响应
- 设置合理的缓存过期时间(如1小时)
- 缓存命中率达到30%可节省约30%的API成本
批处理:
- 将多个小请求合并为单个大请求
- 使用异步处理队列(如Celery、Bull)处理批量任务
- 在非高峰期处理离线任务,避免触发RPM限制
连接池:
- 使用HTTP连接池复用连接,减少握手开销
- Python的
requests.Session()或httpx.AsyncClient() - 连接池大小设置为并发请求数的1.5倍
3. 监控与告警
关键指标监控:
- API调用成功率(目标>99.5%)
- 平均响应时间(目标<2秒)
- Token消耗速率(追踪成本)
- 错误率(按错误代码分类)
告警设置:
- 当错误率>5%时触发告警
- 当每日Token消耗超过预算的80%时预警
- 当响应时间>5秒时触发性能告警
推荐工具:
- Prometheus + Grafana(开源监控)
- Datadog、New Relic(商业方案)
- Google Cloud Monitoring(如使用Vertex AI)
4. 成本优化
模型选择策略:
- 简单任务(如分类、实体提取):使用Gemini 1.5 Flash(最便宜)
- 复杂推理(如代码生成、深度分析):使用Gemini 2.5 Pro
- 实时应用:使用Gemini 2.5 Flash(速度与成本平衡)
Prompt工程:
- 优化prompt长度,减少不必要的上下文
- 使用更精确的指令,减少重试次数
- 测试不同prompt,选择Token消耗最低的版本
配额管理:
- 为不同用户组设置不同的配额限制
- VIP用户:无限制或高配额
- 免费用户:严格限制(如每日10次)
- 使用滑动窗口算法实施速率限制
常见问题与解决方案
基于开发者社区的反馈和Stack Overflow上的讨论,以下是使用免费Gemini API时最常遇到的问题和经过验证的解决方案。
Q1:如何判断我用的是哪个Gemini版本?
问题描述:API响应中没有明确标注版本信息,如何确认调用的是哪个模型?
解决方案: 在API请求的URL中明确指定模型名称。例如:
- Gemini 2.5 Flash:
models/gemini-2.5-flash - Gemini 2.5 Pro:
models/gemini-2.5-pro - Gemini 1.5 Flash:
models/gemini-1.5-flash
你可以在Google AI Studio的"Get Code"功能中查看所有可用模型的完整列表。
Q2:免费额度1,500次/天是UTC时间还是本地时间?
问题描述:不清楚配额重置的具体时间,导致无法合理分配请求。
解决方案: 根据Google官方文档,免费额度的计数周期基于UTC时间,每天00:00 UTC重置。对于中国用户(UTC+8),这意味着每天早上8点配额重置。
建议在应用中记录首次请求的时间戳,并在UTC 23:50之后停止新请求,等待配额重置。
Q3:超出免费额度后会怎样?
问题描述:担心意外超出免费额度导致高额费用。
解决方案: Gemini API的免费层级不会自动升级到付费。当你达到免费额度上限(如1,500 RPD)时,API会返回429错误(RESOURCE_EXHAUSTED),但不会产生费用。
如果需要升级到付费层级,必须在Google AI Studio中手动启用计费并绑定支付方式。这为免费用户提供了天然的成本保护。
Q4:Gemini API支持哪些语言?中文效果如何?
问题描述:担心Gemini对中文的支持不如英文。
解决方案: Gemini 2.5系列在中文任务上的表现已接近GPT-4水平。根据第三方测试:
- 中文理解准确度:
92%(GPT-4为95%) - 中文生成流畅度:与GPT-4相当
- 支持简体中文、繁体中文、粤语等多种中文变体
对于中文应用,建议在prompt中明确指定语言(如"请用中文回答"),以获得最佳效果。
Q5:可以在免费层级使用Gemini API做商业项目吗?
问题描述:不确定免费API是否可以用于商业用途。
解决方案: 根据Google AI Studio的服务条款,免费层级可以用于商业项目,但有以下限制:
- 你的输入和输出数据可能被Google用于模型训练
- 不提供SLA保证
- 受免费额度限制
对于需要数据隐私保护或高可用性的商业项目,建议升级到付费层级,或使用Google Cloud Vertex AI(提供企业级SLA和数据隐私保证)。
Q6:Gemini API在中国大陆能用吗?
问题描述:担心地区限制导致无法访问。
解决方案: Gemini API在中国大陆存在访问障碍,但可通过以下方案解决:
- 官方直连+VPN:适合个人测试(详见"中国用户访问指南"章节)
- API代理服务:适合生产环境,如laozhang.ai提供国内直连访问
- Google Cloud Vertex AI:企业级方案,需要GCP账号
详细方案对比和设置步骤,请参考本文第6章"中国用户访问Gemini API完整指南"。
Q7:如何估算我的项目会消耗多少Token?
问题描述:无法准确预测Token消耗,导致配额规划困难。
解决方案: 使用以下公式估算Token消耗:
- 英文:1 token ≈ 4个字符 ≈ 0.75个单词
- 中文:1 token ≈ 1.5个汉字
示例:
- 一条100字的中文客服消息:约67 tokens
- 一篇1,500字的中文博客:约1,000 tokens
- 一段500字的英文文本:约670 tokens
Google AI Studio提供了Token计数工具,可以在发送请求前预估Token消耗。
Q8:Gemini 3.0什么时候发布?值得等待吗?
问题描述:是否应该等待Gemini 3.0发布再开始项目?
解决方案: 根据Google公开信息,Gemini 3.0预计在2025年下半年发布,但没有确切日期。我们的建议是:
不建议等待,理由如下:
- Gemini 2.5系列已经非常强大,足以满足大多数应用需求
- 免费层级永久有效,现在开始使用不会有额外成本
- 即使3.0发布,2.5系列也会继续维护和支持
- 早期使用可以积累经验,为未来升级做准备
如果你的项目需要最新功能,可以在3.0发布后无缝切换(通常只需修改模型名称参数)。
Q9:免费层级和付费层级的API响应质量有区别吗?
问题描述:担心免费层级的响应质量不如付费版本。
解决方案: 没有区别。免费层级和付费层级使用完全相同的模型和推理引擎,响应质量完全一致。区别仅在于:
- 配额限制(RPM、RPD)
- 数据隐私政策(免费数据可能用于训练)
- SLA保证(付费提供99.9%可用性)
- 优先级(付费请求在高峰期优先处理)
建议:在免费层级充分测试应用,确认效果满足需求后再考虑升级付费。
Q10:遇到"API key not valid"错误怎么办?
问题描述:明明刚生成的API密钥,却提示无效。
解决方案: 按以下步骤排查:
- 检查密钥格式:确保复制了完整的密钥(以
AIzaSy开头) - 检查空格:复制时可能带入前后空格,使用
.strip()清理 - 确认API已启用:在Google AI Studio中确认"Gemini API"已启用
- 检查项目状态:如果项目被暂停或删除,密钥会失效
- 重新生成密钥:如果以上都正常,尝试删除旧密钥并生成新密钥
Python调试代码:
pythonimport os
api_key = os.environ.get('GEMINI_API_KEY')
print(f"密钥长度: {len(api_key)}")
print(f"密钥开头: {api_key[:10]}")
print(f"密钥结尾: {api_key[-10:]}")
print(f"是否包含空格: {' ' in api_key}")
总结
Gemini API为开发者提供了业界最慷慨的免费层级,每日1,500次请求足以支撑大多数原型应用和中小规模项目。虽然"Gemini 3.0"尚未发布,但当前的Gemini 2.5系列已经具备强大的多模态能力和卓越的性能。
关键要点回顾:
- 澄清版本误解:Gemini 3.0未发布,当前最新是Gemini 2.5系列
- 免费额度充足:1,500 RPD,远超GPT-4和Claude的免费选项
- 中国用户可访问:通过代理或API代理服务实现稳定访问
- 真实成本可控:大多数个人项目完全免费,企业级应用成本也比竞品低50%
- 生产级可用:免费层级质量与付费相同,支持商业用途
行动建议:
- 立即开始:访问Google AI Studio生成免费API密钥
- 小规模测试:用免费额度验证你的应用场景
- 评估升级:当每日请求超过1,500次或需要数据隐私保护时,考虑升级付费
- 持续学习:关注Google AI博客,了解Gemini 3.0的发布动态
无论你是AI初学者、独立开发者还是企业技术团队,免费的Gemini API都是探索生成式AI应用的最佳起点。立即开始你的Gemini API之旅,用最低的成本构建最强大的AI应用。