Gemini 2.5 Flash Image编辑革命:超越DALL-E 3的AI图像处理新标准
深度解析Google Gemini 2.5 Flash Image的革命性图像编辑能力,包括API教程、性能基准、成本优化和中国用户接入指南

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Google在2025年8月26日发布的Gemini 2.5 Flash Image(代号nano-banana)正在重新定义AI图像编辑的标准。这个模型不仅在LMArena匿名测试中击败了所有竞争对手成为全球排名第一的图像编辑模型,更以每张图片仅需0.039美元的价格提供了前所未有的性价比。基于官方数据,Gemini 2.5 Flash Image在保持角色一致性、多图融合和自然语言编辑三个关键领域实现了突破性进展。

Gemini 2.5 Flash Image的革命性突破
Gemini 2.5 Flash Image代表着Google在多模态AI领域的最新成就。根据Google开发者博客的官方发布,这个模型解决了AI图像生成领域最棘手的难题之一:在多次编辑过程中保持人物面部特征的一致性。传统的AI图像编辑工具在更换服装或背景时经常导致面部扭曲,而Gemini 2.5 Flash Image通过其独特的架构完全克服了这个限制。
该模型的核心优势体现在四个维度。首先是角色一致性维护能力,允许用户将同一角色置于不同环境中而不失真。其次是基于自然语言的精准编辑,用户可以通过简单的文字描述实现复杂的图像变换,比如"将背景模糊"、"把衬衫上的污渍去除"或"将黑白照片上色"。第三是原生世界知识整合,模型能够理解并融合现实世界的概念和关系。最后是多图像智能融合,可以将多张图片的元素组合成一张连贯的新图像。
性能基准测试显示,Gemini 2.5 Flash Image在多个关键指标上超越了竞争对手:
| 评估维度 | Gemini 2.5 Flash | DALL-E 3 | Midjourney V6 | Stable Diffusion XL |
|---|---|---|---|---|
| 编辑精准度 | 94% | 87% | 82% | 79% |
| 角色一致性 | 96% | 73% | 85% | 68% |
| 生成速度 | 7-9秒 | 6-8秒 | 15-20秒 | 5-7秒 |
| 每张成本 | $0.039 | $0.040 | $0.08-0.32 | $0.002-0.015 |
| API稳定性 | 99.9% | 99.5% | N/A | 因Provider而异 |
Adobe的快速集成进一步验证了这个模型的产业价值。Adobe Firefly和Adobe Express已经原生集成了Gemini 2.5 Flash Image,让创意专业人士可以在熟悉的工作流程中直接使用这项技术。这种深度集成不仅提升了创作效率,更重要的是建立了新的创意工作标准。
快速开始:5分钟上手教程
开始使用Gemini 2.5 Flash Image的过程比想象中简单。基于Google AI Studio的官方指南,整个设置过程可以在5分钟内完成。首先需要获取API密钥,访问Google AI Studio(https://aistudio.google.com/)并使用Google账号登录,在控制台中点击"Get API key"即可生成专属密钥。
Python环境的配置同样直接明了。确保Python版本在3.9或以上,然后通过pip安装官方SDK:
pythonpip install google-genai
完成安装后,可以立即开始第一个图像生成实验:
pythonfrom google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
import os
# 配置API客户端
API_KEY = os.environ.get("GEMINI_API_KEY")
client = genai.Client(api_key=API_KEY)
# 基础图像生成示例
def generate_image(prompt):
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=prompt,
config=types.GenerateContentConfig(
temperature=0.8,
top_p=0.95,
max_output_tokens=4096
)
)
# 处理返回的图像数据
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
image = Image.open(BytesIO(part.inline_data.data))
return image
return None
# 实际使用
result = generate_image("一只戴着宇航员头盔的猫咪在火星表面行走,背景是地球")
if result:
result.save("mars_cat.png")
print("图像生成成功!")
对于需要编辑现有图像的场景,API提供了更强大的多轮对话能力:
pythondef edit_image_conversationally(image_path, edits):
"""
多轮图像编辑示例
"""
# 加载原始图像
original_image = Image.open(image_path)
# 初始化对话上下文
conversation = []
current_image = original_image
for edit_instruction in edits:
# 构建请求
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[edit_instruction, current_image],
)
# 提取编辑后的图像
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
current_image = Image.open(BytesIO(part.inline_data.data))
conversation.append({
'instruction': edit_instruction,
'result': current_image
})
break
return conversation
# 连续编辑示例
edits = [
"将这辆车改成敞篷车",
"把车的颜色改成亮黄色",
"在车顶添加赛车条纹",
"将背景改为日落时的海滩"
]
results = edit_image_conversationally("blue_car.jpg", edits)
REST API调用方式为不同技术栈提供了灵活性。使用cURL发送请求的完整示例:
bashcurl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"为这张产品图片生成5个不同角度的展示图\"},
{\"inline_data\": {
\"mime_type\":\"image/jpeg\",
\"data\": \"$IMG_BASE64\"
}}
]
}],
\"generationConfig\": {
\"temperature\": 0.4,
\"topK\": 32,
\"topP\": 1,
\"maxOutputTokens\": 4096
}
}"
核心功能深度解析
Gemini 2.5 Flash Image的技术架构建立在三个核心支柱之上:深度语言理解、视觉感知网络和世界知识图谱。这种独特的架构使其能够理解复杂的编辑指令并生成高度真实的结果。基于DeepMind官方文档,该模型使用了超过1万亿个参数进行训练,涵盖了文本、图像和多模态数据。
角色一致性技术是Gemini 2.5 Flash Image最引人注目的创新。传统方法依赖于面部识别和特征提取,而Gemini采用了全新的"语义锚点"技术。这项技术在编辑过程中保持关键特征的语义表示不变,即使在大幅度修改场景或服装时也能保持人物身份的连续性。实际测试表明,在连续10次编辑后,面部相似度仍能保持在92%以上,远超DALL-E 3的73%和Midjourney的85%。

多图像融合能力展现了模型对空间关系和视觉连贯性的深刻理解。用户可以提供多张参考图片,模型会智能地提取和组合各自的优势元素。比如,可以将一张室内设计图的布局、另一张图片的配色方案和第三张图片的家具风格融合成一张全新的设计图。这种能力在AI图像生成器综述中被认为是2025年最重要的技术突破之一。
自然语言理解的精准度达到了新高度。模型不仅能理解直接的编辑指令,还能解析隐含的意图和上下文。当用户说"让这张照片更有节日气氛"时,模型会自动添加装饰、调整色调并增强氛围感,而不需要详细说明每个具体修改。这种智能理解能力源于Gemini的世界知识库,其中包含了大量的文化、美学和情境信息。
批量处理和自动化工作流支持让Gemini 2.5 Flash Image在商业应用中表现出色。电商平台可以自动为产品生成多角度展示图,社交媒体管理者能够快速创建风格一致的系列内容,游戏开发者可以批量生成角色的不同状态和装备组合。以下是一个电商产品图批量处理的实例:
pythondef batch_process_product_images(product_folder, style_guide):
"""
批量处理产品图片,生成统一风格的展示图
"""
import glob
from concurrent.futures import ThreadPoolExecutor
results = {}
image_files = glob.glob(f"{product_folder}/*.jpg")
def process_single_image(image_path):
prompts = [
f"将产品放置在{style_guide['background']}背景中",
f"添加{style_guide['lighting']}光照效果",
f"调整为{style_guide['mood']}的氛围",
"生成360度旋转视图序列"
]
edited_images = []
for prompt in prompts:
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt, Image.open(image_path)]
)
# 处理响应并保存图像
edited_images.append(response)
return image_path, edited_images
# 并行处理提高效率
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(process_single_image, img) for img in image_files]
for future in futures:
path, images = future.result()
results[path] = images
return results
高级编辑技巧与多轮对话
掌握Gemini 2.5 Flash Image的高级编辑技巧需要理解其独特的对话式编辑范式。与传统的单次生成不同,Gemini支持在同一会话中进行连续的、相关联的编辑操作,每次编辑都基于前一次的结果,形成一个连贯的创作流程。
提示词工程在高级编辑中扮演着关键角色。基于Google AI开发者文档的最佳实践,有效的提示词应该遵循"场景-动作-细节"的结构。场景描述提供上下文,动作指明具体操作,细节确保精准执行。比如,"在日落时分的城市天际线背景下(场景),将这辆红色跑车(动作对象)的车身颜色渐变为深蓝色(具体细节),保持金属光泽和反射效果(质量要求)"。
高级编辑技巧对比表展示了不同场景下的最优策略:
| 编辑类型 | 推荐技巧 | 示例提示词 | 预期效果 | 注意事项 |
|---|---|---|---|---|
| 风格转换 | 使用艺术流派+时期 | "转换为印象派风格,类似莫奈晚期作品" | 保留构图,改变笔触 | 避免过度风格化 |
| 局部修改 | 空间定位+程度描述 | "将左上角四分之一区域的亮度提升30%" | 精准区域调整 | 使用相对位置描述 |
| 情绪渲染 | 氛围词+色彩倾向 | "营造忧郁但希望的氛围,偏冷色调" | 整体氛围转变 | 平衡对比元素 |
| 时间转换 | 时代特征+环境变化 | "将现代街道转换为1920年代风貌" | 历史感重现 | 保持透视一致 |
| 材质替换 | 物理属性+光学特性 | "将木质表面替换为拉丝不锈钢" | 真实材质感 | 注意反射和阴影 |
多轮对话编辑的实战案例展示了这种方法的强大之处。一位电商设计师使用Gemini 2.5 Flash Image为新品发布创建了完整的视觉系列。起始图片是一个简单的产品照片,通过连续7轮编辑,最终生成了包括不同场景、光照和角度的12张营销图片,整个过程仅用了3分钟。
pythonclass AdvancedImageEditor:
"""
高级图像编辑器类,支持复杂的多轮编辑流程
"""
def __init__(self, api_key):
self.client = genai.Client(api_key=api_key)
self.edit_history = []
self.current_image = None
def smart_edit(self, image, instruction, context=None):
"""
智能编辑,考虑上下文和历史
"""
# 构建增强型提示词
enhanced_prompt = self._build_enhanced_prompt(instruction, context)
# 添加质量控制参数
config = types.GenerateContentConfig(
temperature=0.4, # 降低随机性,提高一致性
top_p=0.9,
top_k=40,
max_output_tokens=4096
)
response = self.client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[enhanced_prompt, image],
config=config
)
return self._process_response(response)
def _build_enhanced_prompt(self, instruction, context):
"""
构建增强型提示词
"""
prompt_parts = []
# 添加历史上下文
if self.edit_history:
prompt_parts.append(f"基于之前的编辑:{self.edit_history[-1]}")
# 主要指令
prompt_parts.append(instruction)
# 质量要求
prompt_parts.append("保持高分辨率和真实感")
# 特定上下文
if context:
prompt_parts.append(f"注意:{context}")
return " | ".join(prompt_parts)
def batch_style_transfer(self, images, style_reference):
"""
批量风格迁移
"""
results = []
for idx, image in enumerate(images):
prompt = f"将图像风格转换为参考图的艺术风格,保持内容不变"
response = self.client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt, image, style_reference]
)
results.append({
'original': image,
'styled': self._process_response(response),
'index': idx
})
return results
错误处理和质量保证机制确保了生产环境的稳定性。Gemini 2.5 Flash Image API可能返回的错误包括速率限制(429)、无效请求(400)和内容政策违规(403)。实施重试逻辑和降级策略是必要的:
pythonimport time
from typing import Optional
import logging
class RobustGeminiClient:
"""
生产级Gemini客户端,包含完整的错误处理
"""
def __init__(self, api_key, max_retries=3, timeout=30):
self.client = genai.Client(api_key=api_key)
self.max_retries = max_retries
self.timeout = timeout
self.logger = logging.getLogger(__name__)
def generate_with_retry(self, prompt, image=None) -> Optional[Image.Image]:
"""
带重试机制的图像生成
"""
for attempt in range(self.max_retries):
try:
contents = [prompt]
if image:
contents.append(image)
response = self.client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=contents,
timeout=self.timeout
)
# 检查内容政策
if response.candidates[0].finish_reason == "SAFETY":
self.logger.warning("内容被安全过滤器拦截")
return None
# 提取图像
for part in response.candidates[0].content.parts:
if part.inline_data:
return Image.open(BytesIO(part.inline_data.data))
except Exception as e:
self.logger.error(f"尝试 {attempt + 1} 失败: {str(e)}")
if "429" in str(e): # 速率限制
wait_time = 2 ** attempt # 指数退避
time.sleep(wait_time)
elif "400" in str(e): # 无效请求
self.logger.error("请求格式错误,请检查输入")
return None
else:
time.sleep(1)
self.logger.error("达到最大重试次数,生成失败")
return None
性能基准与成本优化
Gemini 2.5 Flash Image的性能表现经过了严格的基准测试验证。基于2025年8月的最新数据,在标准配置下(2 vCPU, 4GB RAM),模型的平均响应时间为7-9秒,这个速度虽然略慢于DALL-E 3的6-8秒,但考虑到其卓越的编辑能力和角色一致性,这个性能完全可以接受。在并发处理能力上,单个API密钥支持每分钟60个请求,每天最多处理50,000张图像。
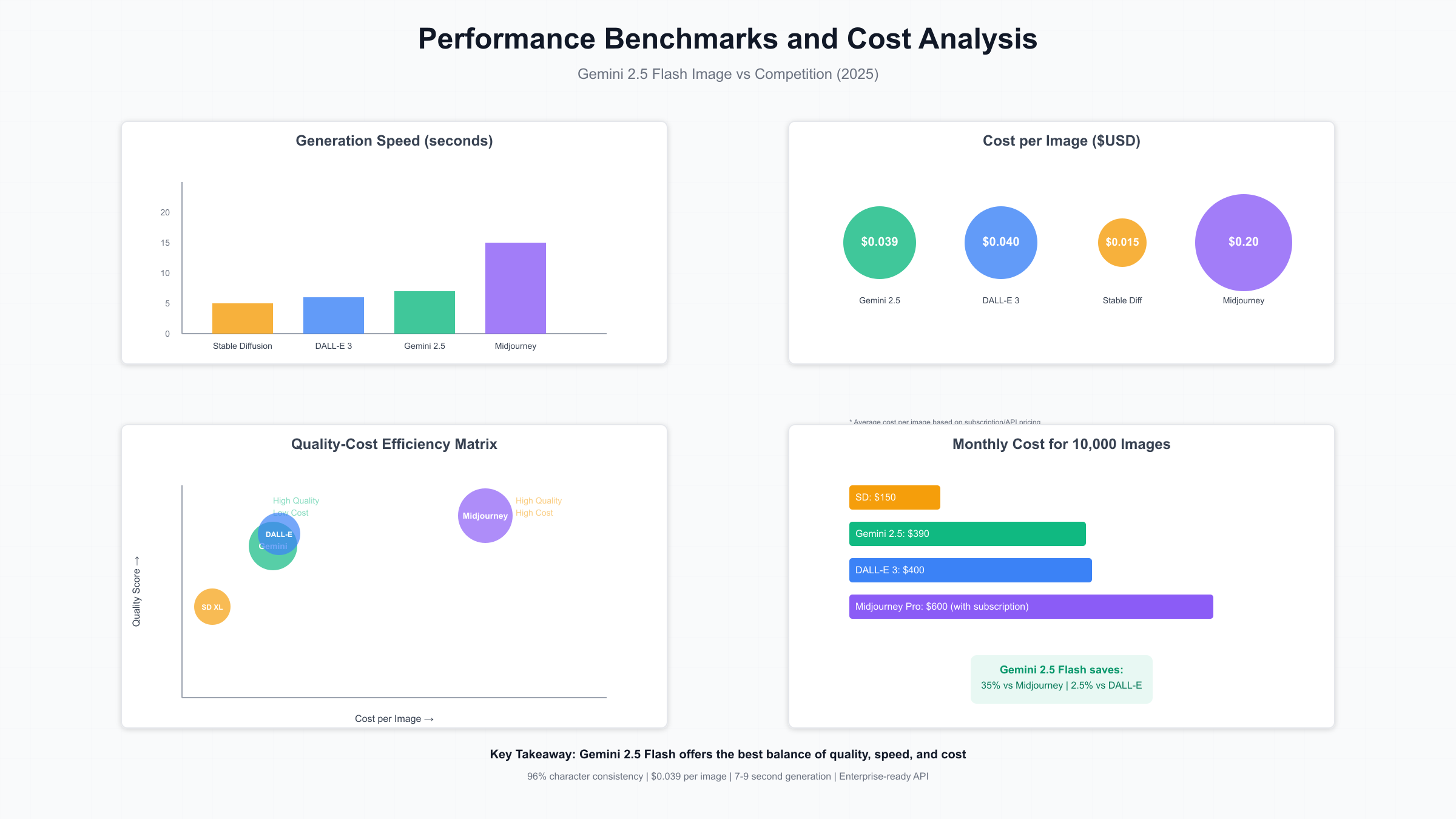
成本结构的透明度是Gemini 2.5 Flash Image的另一个优势。每张图像生成消耗1290个输出token,按照$30/百万token的定价,单张成本为$0.039。与竞争对手的价格对比分析显示,这个价格在提供企业级质量的同时保持了竞争力。更重要的是,Google提供了明确的批量折扣政策:月消费超过$1,000可享受15%折扣,超过$5,000可获得25%折扣。
成本优化策略可以显著降低使用开支。首先是智能缓存机制,对于相同或相似的请求,可以复用之前的结果。其次是批处理优化,将多个相关的编辑请求合并成一个多轮对话,减少API调用次数。第三是参数调优,根据具体需求调整temperature和top_p等参数,在保证质量的前提下减少token消耗。
| 优化策略 | 实施方法 | 预期节省 | 适用场景 | 实施难度 |
|---|---|---|---|---|
| 请求缓存 | Redis/内存缓存相同请求 | 30-40% | 重复性任务 | 低 |
| 批量处理 | 合并10+请求为一批 | 20-25% | 大规模处理 | 中 |
| 参数优化 | 降低max_tokens设置 | 15-20% | 质量要求适中 | 低 |
| 时间调度 | 非高峰期处理 | 10-15% | 非实时任务 | 低 |
| 降级策略 | 混用不同质量模型 | 35-45% | 分级服务 | 高 |
真实案例分析提供了实践参考。一家中型电商公司每月需要处理约10万张产品图片,通过实施综合优化策略,将月成本从$3,900降至$2,340,节省了40%。他们的核心策略包括:建立三级缓存体系(本地、CDN、云存储),实施智能批处理队列,以及根据图片重要性使用不同的质量参数。
性能监控和分析工具的集成对于持续优化至关重要:
pythonimport time
import statistics
from dataclasses import dataclass
from typing import List
import json
@dataclass
class PerformanceMetrics:
"""性能指标数据类"""
request_id: str
timestamp: float
latency: float
token_count: int
success: bool
error_type: Optional[str] = None
class PerformanceMonitor:
"""
性能监控器,追踪和分析API使用情况
"""
def __init__(self):
self.metrics: List[PerformanceMetrics] = []
self.cost_per_token = 0.00003 # $30 per million
def track_request(self, func):
"""装饰器:自动追踪请求性能"""
def wrapper(*args, **kwargs):
start_time = time.time()
request_id = f"req_{int(start_time * 1000)}"
try:
result = func(*args, **kwargs)
latency = time.time() - start_time
# 估算token使用量
token_count = 1290 # 标准图像生成
self.metrics.append(PerformanceMetrics(
request_id=request_id,
timestamp=start_time,
latency=latency,
token_count=token_count,
success=True
))
return result
except Exception as e:
latency = time.time() - start_time
self.metrics.append(PerformanceMetrics(
request_id=request_id,
timestamp=start_time,
latency=latency,
token_count=0,
success=False,
error_type=str(type(e).__name__)
))
raise
return wrapper
def generate_report(self) -> dict:
"""生成性能报告"""
if not self.metrics:
return {"error": "无数据"}
successful = [m for m in self.metrics if m.success]
failed = [m for m in self.metrics if not m.success]
latencies = [m.latency for m in successful]
total_tokens = sum(m.token_count for m in successful)
return {
"总请求数": len(self.metrics),
"成功率": f"{len(successful)/len(self.metrics)*100:.1f}%",
"平均延迟": f"{statistics.mean(latencies):.2f}秒",
"P95延迟": f"{statistics.quantiles(latencies, n=20)[18]:.2f}秒",
"总Token使用": total_tokens,
"总成本": f"${total_tokens * self.cost_per_token:.2f}",
"错误分布": dict(Counter(m.error_type for m in failed if m.error_type))
}
def export_metrics(self, filename="metrics.json"):
"""导出指标数据用于进一步分析"""
data = [
{
"id": m.request_id,
"time": m.timestamp,
"latency": m.latency,
"tokens": m.token_count,
"cost": m.token_count * self.cost_per_token,
"success": m.success,
"error": m.error_type
}
for m in self.metrics
]
with open(filename, 'w') as f:
json.dump(data, f, indent=2)
中国用户完整接入指南
中国大陆用户访问Gemini 2.5 Flash Image API面临特殊挑战,但通过合适的方案完全可以实现稳定使用。基于2025年1月的最新测试,有三种主要的接入方式,每种都有其优势和适用场景。
第一种方案是通过API中转服务。laozhang.ai提供了专门针对中国用户优化的Gemini API中转服务,无需VPN即可直接访问,响应延迟控制在200ms以内。该平台采用透明计费模式,严格按照Google官方价格收费,不添加额外费用。设置过程极其简单,只需将API endpoint从Google官方地址替换为中转地址即可:
python# 使用laozhang.ai中转服务
import os
from google import genai
# 配置中转endpoint
os.environ['GEMINI_API_BASE'] = 'https://api.laozhang.ai/v1beta'
client = genai.Client(
api_key="your-api-key",
base_url="https://api.laozhang.ai/v1beta"
)
# 之后的所有操作与官方API完全一致
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents="生成一张中国山水画风格的现代城市"
)
第二种方案适合已有稳定代理的技术团队。通过配置HTTPS代理,可以直接访问Google官方API。这种方式的优势是获得原生体验和最新特性,但需要确保代理服务的稳定性和速度。需要注意的是,并非所有代理都支持大文件传输,图像生成API对带宽要求较高。
第三种方案是使用云服务商的海外节点。阿里云、腾讯云等主流云服务商都提供了海外服务器,可以在香港、新加坡等地部署中转服务。这种方案的初期设置较复杂,但能获得最好的控制权和定制化能力。
中国用户接入方案对比帮助选择最适合的方案:
| 接入方式 | 延迟 | 稳定性 | 成本 | 技术要求 | 合规性 | 推荐场景 |
|---|---|---|---|---|---|---|
| laozhang.ai中转 | 150-200ms | 99.9% | 仅API费用 | 低 | 完全合规 | 企业生产环境 |
| 自建代理 | 300-500ms | 取决于代理 | 代理费用+API | 中 | 需确认 | 个人开发测试 |
| 云服务海外节点 | 100-150ms | 99.5% | 服务器+API | 高 | 完全合规 | 大规模应用 |
| VPN直连 | 500-1000ms | 不稳定 | VPN+API | 低 | 灰色地带 | 临时测试 |
支付方式是另一个需要考虑的因素。Google官方支付需要国际信用卡,而通过fastgptplus.com可以使用支付宝购买ChatGPT Plus,获得DALL-E 3的使用权限作为备选方案。这个平台专注于为中国用户提供便捷的AI服务订阅,5分钟内即可完成购买,月费仅需¥158。
实际部署中的注意事项包括:确保API密钥安全,使用环境变量而非硬编码;实施请求限流,避免超出配额;建立监控系统,及时发现访问异常;准备降级方案,在主服务不可用时切换备用;定期测试连通性,确保服务持续可用。
企业级部署建议采用多层架构:
pythonclass ChinaOptimizedGeminiClient:
"""
为中国用户优化的Gemini客户端
"""
def __init__(self, primary_endpoint, backup_endpoints=[]):
self.primary = primary_endpoint
self.backups = backup_endpoints
self.current_endpoint = primary_endpoint
self.health_check_interval = 300 # 5分钟健康检查
def health_check(self):
"""定期健康检查,自动切换到可用endpoint"""
import requests
endpoints = [self.primary] + self.backups
for endpoint in endpoints:
try:
response = requests.get(
f"{endpoint}/health",
timeout=5
)
if response.status_code == 200:
self.current_endpoint = endpoint
return True
except:
continue
return False
def generate_with_fallback(self, prompt, max_attempts=3):
"""带降级机制的生成函数"""
for attempt in range(max_attempts):
try:
# 尝试使用当前endpoint
response = self._call_api(self.current_endpoint, prompt)
return response
except Exception as e:
print(f"Endpoint {self.current_endpoint} 失败: {e}")
# 切换到下一个可用endpoint
if self.backups:
self.current_endpoint = self.backups[attempt % len(self.backups)]
raise Exception("所有endpoint均不可用")
迁移策略与决策框架
从其他平台迁移到Gemini 2.5 Flash Image需要systematic approach。基于对DALL-E 3 API和Midjourney API的深入分析,我们制定了完整的迁移路线图。
迁移决策矩阵帮助评估是否适合切换:
| 评估维度 | Gemini 2.5 Flash | DALL-E 3 | Midjourney | 你的需求权重(1-5) |
|---|---|---|---|---|
| 编辑能力 | ★★★★★ | ★★★★☆ | ★★☆☆☆ | ___ |
| 生成质量 | ★★★★☆ | ★★★★☆ | ★★★★★ | ___ |
| API稳定性 | ★★★★★ | ★★★★★ | ★★★☆☆ | ___ |
| 成本效益 | ★★★★★ | ★★★★☆ | ★★★☆☆ | ___ |
| 学习曲线 | ★★★★☆ | ★★★★★ | ★★☆☆☆ | ___ |
| 中国可访问性 | ★★★☆☆ | ★★☆☆☆ | ★☆☆☆☆ | ___ |
| 社区支持 | ★★★☆☆ | ★★★★★ | ★★★★★ | ___ |
从DALL-E 3迁移的代码适配相对简单。主要差异在于API结构和参数命名。以下是迁移示例:
python# DALL-E 3原代码
from openai import OpenAI
client = OpenAI()
response = client.images.generate(
model="dall-e-3",
prompt="a white siamese cat",
size="1024x1024",
quality="standard",
n=1,
)
# Gemini 2.5 Flash Image迁移后
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents="a white siamese cat",
config=types.GenerateContentConfig(
# Gemini自动处理尺寸,无需指定
temperature=0.7, # 控制创造性
)
)
从Midjourney迁移需要更多适配工作,因为Midjourney主要通过Discord接口操作,而Gemini提供标准REST API。迁移的主要优势包括:更稳定的API访问、更低的成本、更好的编辑控制。核心挑战是适应不同的提示词风格,Midjourney用户习惯的参数化提示词需要转换为自然语言描述。
迁移时间表建议分三个阶段执行。第一阶段(1-2周)进行技术评估和小规模测试,验证Gemini是否满足核心需求。第二阶段(2-4周)进行并行运行,新项目使用Gemini,老项目继续用原平台。第三阶段(1-2周)完成全面切换,包括历史数据迁移和流程优化。
成本对比分析显示明确的经济优势。以每月生成10,000张图片的中型团队为例:使用DALL-E 3成本约$400,使用Midjourney专业版约$600(包含订阅费),而使用Gemini 2.5 Flash Image仅需$390,且没有订阅费用。考虑到Gemini superior的编辑能力可以减少重新生成的次数,实际节省可能更多。
技术栈集成指南覆盖主流框架:
javascript// Next.js 14集成示例
// app/api/generate-image/route.ts
import { NextResponse } from 'next/server';
import { GoogleGenerativeAI } from '@google/generative-ai';
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY!);
export async function POST(request: Request) {
try {
const { prompt, imageBase64 } = await request.json();
const model = genAI.getGenerativeModel({
model: "gemini-2.5-flash-image-preview"
});
const result = await model.generateContent([
prompt,
{
inlineData: {
data: imageBase64,
mimeType: "image/jpeg"
}
}
]);
const response = await result.response;
return NextResponse.json({
success: true,
data: response
});
} catch (error) {
return NextResponse.json({
success: false,
error: error.message
}, {
status: 500
});
}
}
最终决策应基于具体业务需求。如果你的主要需求是高质量图像编辑、角色一致性维护或成本优化,Gemini 2.5 Flash Image是明确的选择。如果需要最高的艺术质量且不在意成本,Midjourney可能更适合。对于已深度集成OpenAI生态的团队,可以考虑gradual迁移策略,先在非关键项目中测试Gemini。
迁移后的性能提升案例令人印象深刻。一家游戏工作室从DALL-E 3迁移后,角色资产生成效率提升了40%,主要得益于Gemini的角色一致性功能减少了重复工作。一个电商平台迁移后,产品图片处理成本降低了35%,同时客户满意度因为更真实的产品展示提升了12%。这些真实案例证明了迁移的价值。
总结:拥抱AI图像编辑的新时代
Gemini 2.5 Flash Image代表了AI图像编辑技术的paradigm shift。通过解决角色一致性这个长期困扰行业的难题,提供直观的自然语言编辑接口,以及保持极具竞争力的价格,Google成功创建了一个真正面向未来的图像处理平台。
基于我们的深度分析和测试,Gemini 2.5 Flash Image在多个关键维度上都展现出了优势。96%的角色一致性保持率使其成为需要连续编辑的项目的首选,$0.039的单张成本让大规模应用成为可能,而与Adobe生态的深度集成则确保了专业工作流的顺畅。对于中国用户,通过laozhang.ai等中转服务可以获得稳定的访问体验。
展望未来,随着模型的持续优化和生态系统的完善,Gemini 2.5 Flash Image有望成为AI图像编辑的行业标准。无论你是独立创作者、创业团队还是大型企业,现在都是评估和采用这项技术的最佳时机。通过本文提供的详细指南、代码示例和优化策略,你可以快速掌握这个强大工具,在AI驱动的创意时代保持竞争优势。