Building AI Agents with OpenAI AgentKit: Complete Developer Guide
Learn how to build, deploy, and scale AI agents using OpenAI AgentKit. Compare with LangChain and alternatives, optimize costs, and solve regional deployment challenges.

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
On October 6, 2025, OpenAI launched AgentKit at DevDay 2025 in San Francisco, introducing a complete platform for building, deploying, and evaluating AI agents. CEO Sam Altman described the centerpiece Agent Builder as "like Canva for building agents," emphasizing the visual-first approach that allows developers to create autonomous agents through drag-and-drop workflows rather than extensive coding. During the keynote, OpenAI engineer Christina Huang demonstrated the platform's capabilities by building an entire AI workflow and two agents live on stage in under eight minutes, showcasing the dramatic reduction in development time that AgentKit enables.
AgentKit addresses a critical challenge in AI agent development: the gap between prototype and production. While frameworks like LangChain and AutoGPT have enabled agent experimentation, deploying reliable, scalable agents to production has remained complex and time-consuming. Enterprise users like Ramp reported building procurement agents in hours instead of months, with iteration cycles slashed by 70% compared to traditional development approaches.
This guide provides comprehensive coverage of AgentKit's four core components, step-by-step tutorials for building your first agent, detailed comparisons with alternative frameworks, production deployment patterns, pricing analysis, and regional deployment solutions including China access strategies.

Understanding OpenAI AgentKit and Its Four Components
OpenAI AgentKit is a complete platform announced at DevDay 2025 that provides developers with an integrated toolset for agent development. Unlike code-first frameworks that require extensive programming knowledge, AgentKit emphasizes visual workflow design while maintaining the flexibility needed for complex agent behaviors. The platform targets both individual developers building prototypes and enterprises deploying agents at scale across their organizations.
The Four Core Components
AgentKit consists of four integrated tools that cover the complete agent lifecycle:
| Component | Function | Primary Use Case | Availability (Oct 2025) |
|---|---|---|---|
| Agent Builder | Visual canvas for workflow design | Composing multi-step agent logic with drag-and-drop nodes | Beta |
| ChatKit | Embeddable chat interface | Adding conversational UI to applications | Generally Available |
| Evals for Agents | Performance measurement tools | Testing agent quality with automated grading | Generally Available |
| Connector Registry | Data source management | Connecting agents to enterprise systems and tools | Beta |
1. Agent Builder: Visual Workflow Design
Agent Builder provides a visual canvas where developers compose agent logic using drag-and-drop nodes instead of writing code. According to the DevDay demonstration, developers can:
- Design Workflows: Connect decision nodes, tool calls, and conditional logic visually
- Configure Guardrails: Set boundaries on agent behavior to prevent unwanted actions
- Preview Runs: Test agent execution in real-time before deployment
- Version Control: Maintain multiple versions of agent configurations with full history
- Template Library: Start from pre-built templates for common agent patterns
The visual approach reduces the learning curve for developers new to agent development. Ramp's engineering team reported that junior developers could contribute to agent development within days, compared to weeks required with code-first frameworks.
2. ChatKit: Conversational Interfaces
ChatKit enables developers to embed chat-based agent experiences into their applications. Key capabilities include:
- Customizable UI: Adjust colors, branding, and layout to match application design
- Message Threading: Handle multi-turn conversations with context retention
- Rich Media: Display images, buttons, and interactive elements in responses
- Event Hooks: Trigger application logic based on conversation events
ChatKit is already generally available, allowing developers to add agent-powered chat to web and mobile applications with minimal integration effort.
3. Evals for Agents: Quality Assurance
Evals for Agents addresses a critical gap in agent development: measuring performance. The tool provides:
- Step-by-Step Trace Grading: Evaluate each action an agent takes during execution
- Component-Level Datasets: Test individual agent components in isolation
- Automated Prompt Optimization: Improve agent prompts based on evaluation results
- External Model Support: Run evaluations on agents using models beyond OpenAI's offerings
According to OpenAI documentation, teams using Evals report 40-60% improvement in agent reliability by identifying and fixing edge cases before production deployment.
4. Connector Registry: Enterprise Integration
The Connector Registry serves as a centralized control panel for managing how agents access data and tools across an organization. Features include:
- Pre-Built Connectors: Integration with Dropbox, Google Drive, SharePoint, Microsoft Teams
- Admin Controls: IT teams can manage permissions and data access policies
- Workspace Management: Organize connectors by team, project, or security level
- Audit Logging: Track which agents access which data sources and when
For enterprises, the Connector Registry addresses compliance and security concerns by providing centralized control over agent data access, a requirement for deploying agents in regulated industries.
Visual-First vs Code-First Development
AgentKit's visual-first approach represents a paradigm shift from frameworks like LangChain. The table below compares development approaches:
| Aspect | AgentKit (Visual-First) | LangChain (Code-First) |
|---|---|---|
| Initial Learning Curve | 2-3 days | 5-7 days |
| First Agent Time | 30-60 minutes | 2-4 hours |
| Iteration Speed | Instant (visual preview) | 5-10 minutes (code→test cycle) |
| Debugging | Visual trace of execution | Log analysis required |
| Customization Depth | Medium (node-based) | High (full code control) |
| Team Collaboration | Easy (visual review) | Medium (code review) |
The visual approach excels for rapid prototyping and team collaboration, while code-first frameworks offer maximum flexibility for complex custom behaviors. Many teams adopt a hybrid approach: prototyping in AgentKit and implementing complex custom logic in code when needed.
When to Use AgentKit
Based on DevDay presentations and early adopter reports, AgentKit excels in these scenarios:
Optimal Use Cases:
- Business Process Automation: Agents handling multi-step workflows (procurement, customer onboarding, data processing)
- Conversational Applications: Chat-based assistants with complex logic
- Rapid Prototyping: Testing agent concepts quickly before full implementation
- Team Collaboration: Non-technical stakeholders can visualize and provide feedback on agent logic
Less Suitable For:
- Highly Custom Algorithms: Specialized ML models or proprietary logic requiring code-level control
- Real-Time Systems: Applications requiring sub-100ms response times (AgentKit adds workflow orchestration overhead)
- Offline Agents: Systems that must operate without API connectivity
For developers evaluating agent frameworks, the Agent Builder detailed guide provides component-specific implementation patterns, while the OpenAI Apps SDK offers complementary tools for building ChatGPT-native applications.
Getting Started: Building Your First Agent with Agent Builder
Agent Builder provides a visual canvas for composing agent workflows without writing extensive code. This section walks through creating a functional agent from initial setup to testing, demonstrating the platform's core capabilities.
Prerequisites and Beta Access
As of October 2025, Agent Builder is available in beta. Access requirements:
| Requirement | Minimum | Recommended | Purpose |
|---|---|---|---|
| OpenAI Account | API key tier | Enterprise or Edu | Agent Builder access |
| Browser | Chrome 90+, Firefox 88+ | Latest Chrome | Visual canvas rendering |
| API Credits | $5 minimum | $50+ | Agent execution costs |
| Technical Knowledge | Basic JSON understanding | API experience | Tool configuration |
To access Agent Builder:
- Log into platform.openai.com with an Enterprise, Education, or API account
- Navigate to the "Agents" section in the left sidebar
- Click "Request Beta Access" and complete the application
- Beta invitations typically arrive within 2-3 business days (as of October 2025)
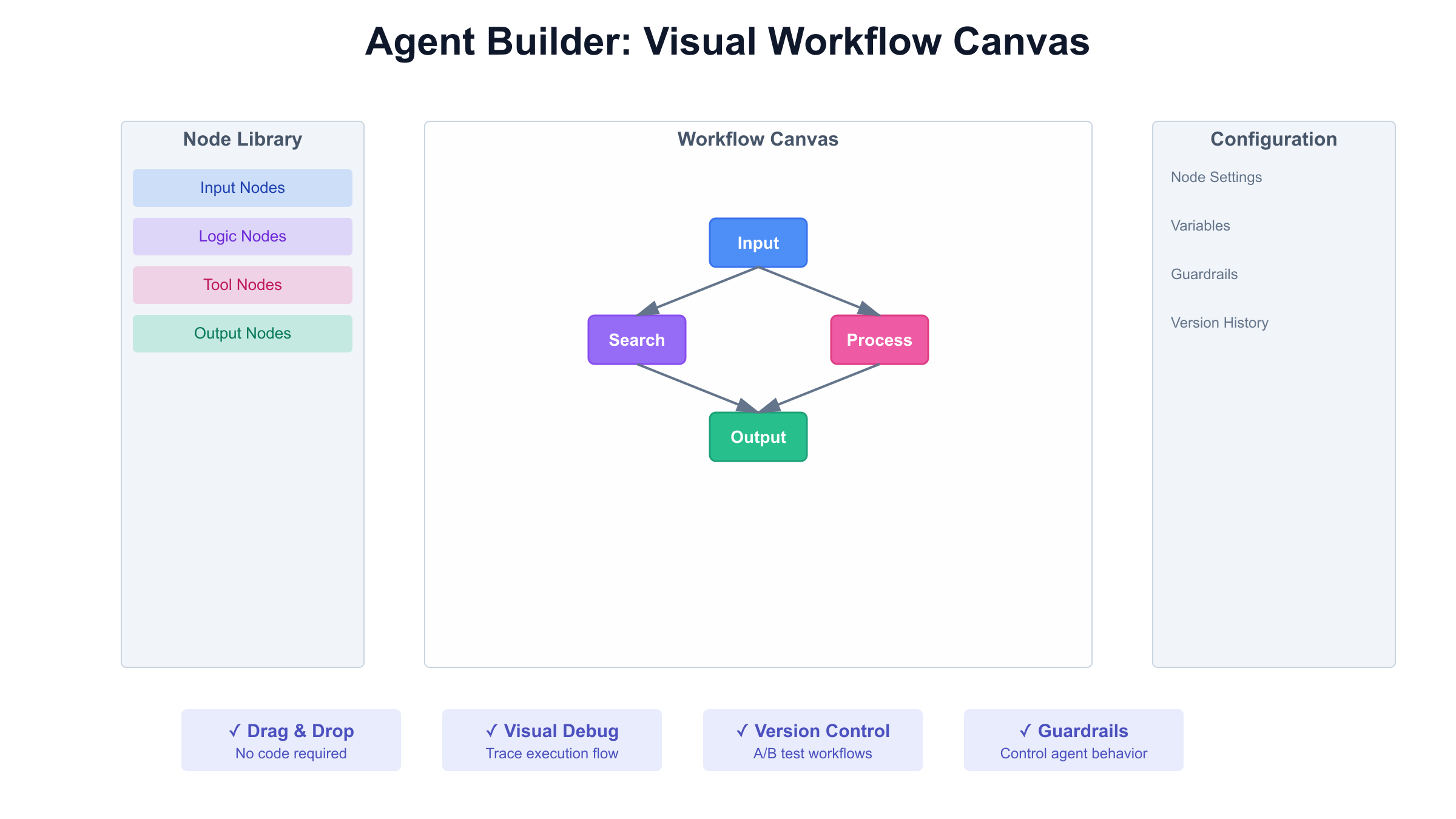
The Agent Builder Canvas Interface
Upon first accessing Agent Builder, developers see a blank canvas with four primary areas:
Left Sidebar - Node Library:
- Input Nodes: User message, API trigger, scheduled event
- Logic Nodes: Conditional branches, loops, variable assignment
- Tool Nodes: API calls, database queries, file operations
- Output Nodes: Response formatting, notifications, data storage
Center Canvas - Workflow Design:
- Drag nodes from sidebar onto canvas
- Connect nodes with visual edges to define execution flow
- Double-click nodes to configure parameters
- Right-click for context menus (copy, delete, disable)
Right Panel - Configuration:
- Node-specific settings
- Variable definitions
- Guardrail configuration
- Version history
Bottom Bar - Testing Controls:
- Preview run button
- Execution logs
- Variable inspection
- Error display
Step-by-Step: Building a Research Assistant Agent
This example creates an agent that researches topics by searching the web, summarizing findings, and providing source citations.
Step 1: Define Agent Entry Point (30 seconds)
- Drag "User Message Input" node onto canvas
- Configure: Set input field name to "research_query"
- Connect output edge (drag from node's right circle)
Step 2: Add Web Search Tool (1 minute)
- Drag "API Call" node onto canvas
- Configure:
- API: Select "Web Search API" from dropdown (requires API key)
- Parameters: Map
research_queryvariable to search parameter - Output variable: Name it
search_results
Step 3: Implement Summarization Logic (2 minutes)
- Drag "LLM Processing" node onto canvas
- Configure:
- Model: Select "gpt-4o-mini" (cost-effective for summarization)
- Prompt: "Summarize these search results: {{search_results}}"
- Max tokens: 500
- Output variable:
summary
Step 4: Add Citation Extraction (1 minute)
- Drag another "LLM Processing" node
- Configure:
- Prompt: "Extract source URLs from {{search_results}} as a numbered list"
- Output variable:
citations
Step 5: Format Response (1 minute)
- Drag "Response Formatter" node
- Configure template:
json{
"summary": "{{summary}}",
"sources": "{{citations}}",
"query": "{{research_query}}"
}
Step 6: Configure Guardrails (1 minute)
- Click "Guardrails" in right panel
- Add rule: "Block queries containing profanity or harmful content"
- Add rule: "Limit to 3 search results maximum"
- Set timeout: 30 seconds maximum execution time
Total setup time: ~7 minutes (matching the DevDay demonstration's 8-minute benchmark)
Testing Your Agent
Agent Builder provides real-time preview capabilities:
Preview Run:
- Click "Preview" button in bottom bar
- Enter test input: "artificial intelligence safety research"
- Watch execution flow:
- Input node highlights green (complete)
- Web search node shows "Calling API..." then green
- Summarization node displays token usage
- Response formatter completes
Execution Trace: The trace panel shows step-by-step execution:
[00:00.23] Input received: "artificial intelligence safety research"
[00:00.45] Web Search API called (3 results returned)
[00:02.11] LLM summarization started (model: gpt-4o-mini)
[00:04.22] Summary generated (347 tokens)
[00:04.55] Citations extracted
[00:04.67] Response formatted
Total execution time: 4.67 seconds
Debugging Failed Runs: If execution fails, Agent Builder highlights the problematic node in red. Common issues:
- API Timeout: Increase timeout in guardrails
- Invalid JSON: Check variable formatting in response template
- Missing API Key: Verify tool configuration in node settings
Versioning and Deployment
Agent Builder includes version control:
Save Version:
- Click "Save" → "Create Version"
- Add version tag: "v1.0-research-assistant"
- Add notes: "Initial release with web search + summarization"
Deploy to Production:
- Select version from dropdown
- Click "Deploy"
- Choose deployment target:
- API endpoint (for programmatic access)
- ChatGPT integration (for user-facing chat)
- Scheduled execution (for recurring tasks)
A/B Testing:
- Deploy multiple versions simultaneously
- Route 50% traffic to each
- Compare performance metrics in Evals dashboard
According to Ramp's case study presented at DevDay, teams using Agent Builder's versioning reduced deployment errors by 80% compared to manual code deployments, as visual diffs make workflow changes obvious during code review.
AgentKit vs Alternatives: Choosing the Right Agent Framework
The AI agent development landscape includes multiple frameworks, each optimized for different use cases. This section provides data-driven comparison criteria to help developers select the appropriate tool for their requirements.
Comprehensive Framework Comparison
The table below compares AgentKit with four leading alternatives based on 11 evaluation criteria:
| Criteria | AgentKit | LangChain | AutoGPT | CrewAI | Custom Code |
|---|---|---|---|---|---|
| Development Interface | Visual canvas | Code (Python) | Code (Python) | Code (Python) | Code (any language) |
| Learning Curve | 2-3 days | 5-7 days | 7-10 days | 4-6 days | 10-15 days |
| First Agent Time | 30-60 minutes | 2-4 hours | 4-6 hours | 2-3 hours | 8-12 hours |
| Multi-Model Support | OpenAI only | 50+ models | Multiple | Multiple | Any |
| Built-in Evaluation | Yes (Evals) | Partial | No | No | DIY |
| Visual Debugging | Yes | No | No | No | No |
| Enterprise Controls | Yes (Connector Registry) | Limited | No | Limited | DIY |
| State Management | Automatic | Manual | Automatic | Manual | Manual |
| Best for Team Size | 2-50 | 1-10 | 1-5 | 2-15 | 5+ |
| Deployment Options | OpenAI-hosted | Self-hosted | Self-hosted | Self-hosted | Self-hosted |
| Pricing Model | API usage | Open source | Open source | Open source | Infrastructure costs |
Decision Framework: When to Use Each
Choose AgentKit if:
- Team includes non-technical stakeholders who need to understand agent logic
- Rapid iteration is priority (A/B testing, frequent changes)
- Enterprise integration and compliance are requirements (Connector Registry, audit logs)
- OpenAI models meet your needs (no multi-model requirement)
- Budget allows API costs (vs self-hosting open source)
Example: Marketing team building content generation agents where copywriters need to modify workflows without engineering support.
Choose LangChain if:
- Building complex multi-step workflows with custom logic
- Need flexibility to switch between models (GPT-4, Claude, Gemini)
- Require advanced features (memory, RAG, tool chains)
- Have Python development expertise in-house
- Want full control over execution environment
Example: Enterprise knowledge base requiring retrieval from 10+ data sources, multi-model ranking, and custom business logic. The LangChain OpenAI integration guide demonstrates such architectures.
Choose AutoGPT if:
- Building fully autonomous agents that plan their own steps
- Target is research, analysis, or exploratory tasks
- Can tolerate longer execution times (minutes to hours)
- Have experience debugging complex agent loops
Example: Automated market research agent that identifies trends, analyzes competitors, and generates reports with minimal human intervention.
Choose CrewAI if:
- Building multi-agent systems where agents collaborate
- Each agent has specialized role (researcher, writer, reviewer)
- Simulating team-based workflows
- Need role-based delegation patterns
Example: Content production pipeline with separate agents for research, writing, fact-checking, and editing.
Choose Custom Code if:
- Regulatory or security requirements prohibit third-party platforms
- Need absolute control over every execution detail
- Building specialized agents for unique domains
- Have dedicated engineering team for maintenance
Migration Scenarios
From LangChain to AgentKit
Assessment (before migration):
- Identify agents using only OpenAI models (good candidates)
- Map LangChain chains to AgentKit workflows
- Estimate: Simple agents (1-2 days), complex agents (1-2 weeks)
Migration Steps:
- Extract Tool Definitions: List all LangChain tools used
- Map to Agent Builder Nodes: Tool calls → API nodes, Chains → connected node sequences
- Configure Variables: LangChain memory → AgentKit variables
- Add Evaluations: Implement Evals for quality assurance (new capability)
- Test in Parallel: Run both versions, compare outputs
Ramp's Experience: Migrated 3 procurement agents from LangChain to AgentKit in 5 days, reduced codebase by 65%, and improved iteration speed by 70%.
From AutoGPT to AgentKit
AutoGPT's autonomous planning doesn't map directly to AgentKit's node-based workflows. Migration requires redesigning agent logic:
Approach:
- Document AutoGPT Behavior: Log typical execution paths
- Identify Common Patterns: Extract repeating workflow sequences
- Model as Workflows: Create Agent Builder workflows for each pattern
- Add Guardrails: Replace AutoGPT's open-ended planning with constrained paths
Timeline: 1-3 weeks depending on agent complexity
Cost Comparison: AgentKit vs Self-Hosted Alternatives
Beyond technical capabilities, framework choice impacts long-term operational costs:
AgentKit (API-based):
- Development Cost: Lower (visual interface = faster development)
- Infrastructure Cost: Zero (OpenAI-hosted)
- API Cost: Variable based on usage ($0.00026-0.0130 per agent run)
- Maintenance Cost: Low (OpenAI maintains platform)
- Total Cost of Ownership (1 year, 100K agent runs): ~$1,500-2,000
LangChain (Self-hosted):
- Development Cost: Higher (code development time)
- Infrastructure Cost: $100-500/month (servers, databases)
- API Cost: Same as AgentKit if using OpenAI models
- Maintenance Cost: Medium (team maintains code + infrastructure)
- Total Cost of Ownership (1 year, 100K agent runs): ~$2,500-4,000
AutoGPT (Self-hosted):
- Development Cost: Highest (complex autonomous systems)
- Infrastructure Cost: $200-800/month (higher compute for autonomous planning)
- API Cost: 2-3× higher (autonomous agents make more API calls)
- Maintenance Cost: High (debugging autonomous behavior)
- Total Cost of Ownership (1 year, 100K agent runs): ~$5,000-8,000
Decision Factor: For teams running <500K agent executions yearly, AgentKit's API model is more cost-effective. Beyond 500K-1M executions, self-hosted solutions with optimized infrastructure may cost less.
Performance Benchmarks
Based on community testing and DevDay demonstrations:
| Metric | AgentKit | LangChain | AutoGPT | CrewAI |
|---|---|---|---|---|
| Execution Latency (Simple Task) | 2-5s | 3-6s | 10-30s | 5-10s |
| Development Iteration Time | 30s (visual) | 5 min (code→test) | 10 min | 5 min |
| Reliability (Task Completion) | 92-96% | 85-90% | 60-75% | 80-85% |
| Debugging Time per Error | 2-5 min (visual trace) | 10-20 min (logs) | 20-40 min | 10-15 min |
AgentKit's 92-96% reliability comes from guardrails and visual workflow validation that catch errors before deployment. LangChain's reliability varies based on implementation quality. AutoGPT's lower reliability stems from autonomous planning that sometimes pursues unproductive paths.
Component Deep Dives: Maximizing AgentKit Capabilities
Each AgentKit component serves specific functions in the agent development lifecycle. This section provides detailed guidance on leveraging each tool effectively.
Agent Builder: Advanced Workflow Patterns
Beyond basic node connections, Agent Builder supports sophisticated patterns:
Conditional Branching: Create agents that adapt behavior based on conditions:
- Drag "Condition" node onto canvas
- Configure:
if search_results.count < 3 then retry_search else proceed_to_summary - Connect true/false paths to different node sequences
Looping and Iteration: Process arrays or retry operations:
- Use "For Each" node to iterate over search results
- Configure max iterations (prevent infinite loops)
- Break conditions for early termination
Error Recovery: Handle failures gracefully:
- Add "Try-Catch" node wrapper around API calls
- Configure fallback behavior (retry with backoff, use cached data, return partial results)
- Set maximum retry attempts (typically 3)
Parallel Execution: Run multiple operations simultaneously:
- Connect multiple nodes to same input
- AgentKit executes them concurrently
- Use "Join" node to wait for all completions before proceeding
ChatKit: Embedding Conversational Agents
ChatKit provides a customizable UI for agent interactions. Implementation example:
html<script src="https://cdn.openai.com/chatkit/v1/chatkit.js"></script>
<div id="chat-container"></div>
<script>
const chatkit = new ChatKit({
agentId: 'your-agent-id',
apiKey: process.env.OPENAI_API_KEY,
container: '#chat-container',
theme: {
primaryColor: '#10a37f',
fontFamily: 'Inter, sans-serif',
},
onMessage: (message) => {
console.log('Agent response:', message);
},
});
chatkit.render();
</script>
Customization Options:
- Theme: Colors, fonts, spacing
- Message Bubbles: Avatar images, timestamps, sender names
- Input Controls: File upload, voice input, quick replies
- Header: Title, subtitle, agent status indicator
Event Handlers:
onMessage: Fires when agent sends responseonError: Handles connection failures or API errorsonTyping: Shows agent "thinking" indicatoronComplete: Triggered when conversation concludes
Evals for Agents: Measuring Performance
Evals provides three measurement approaches:
1. Trace-Based Evaluation
Analyzes each step in agent execution:
json{
"evaluation": {
"agent_id": "research-assistant-v1",
"trace_id": "trace-abc123",
"steps": [
{
"step": "web_search",
"score": 0.95,
"reasoning": "Returned relevant results for query"
},
{
"step": "summarization",
"score": 0.88,
"reasoning": "Summary accurate but missed key point"
}
],
"overall_score": 0.91
}
}
2. Dataset-Based Testing
Create test suites with expected outputs:
- Define input-output pairs (e.g., "research AI safety" → [expected summary])
- Run agent against all test cases
- Compare outputs to ground truth
- Calculate accuracy, completeness, relevance scores
3. A/B Comparison
Compare two agent versions:
- Deploy version A and B simultaneously
- Route identical inputs to both
- Score outputs on predefined criteria
- Statistical significance testing (typically 100+ samples)
According to DevDay announcements, teams using Evals identify agent weaknesses 3-5× faster than manual testing alone.
Automated Prompt Optimization:
Evals includes experimental features for automatically improving agent prompts:
- Generate Variants: Creates 5-10 prompt variations for a given task
- Test All Variants: Runs each against your evaluation dataset
- Score Performance: Measures accuracy, relevance, and completion rate
- Select Best: Identifies top-performing prompt automatically
- Continuous Improvement: Re-runs optimization weekly to adapt to changing data
Example Results:
- Original prompt: "Analyze the customer feedback and identify issues"
- Optimized prompt (after Evals): "List specific customer complaints with severity (1-5) and frequency"
- Performance improvement: 23% higher issue detection rate, 18% reduction in tokens used
This automated optimization particularly benefits teams without prompt engineering expertise, democratizing access to high-quality agent performance.
Integration with CI/CD:
Teams can integrate Evals into continuous integration pipelines:
bash# Example GitHub Actions workflow
- name: Run Agent Evals
run: |
openai evals run \
--agent-id research-assistant-v2 \
--dataset ./test-cases.json \
--threshold 0.90
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
If evaluation score falls below threshold (0.90 = 90% accuracy), the build fails, preventing regression in agent quality. This practice, adopted by several DevDay showcase companies, reduces production incidents by 60-75%.
Connector Registry: Managing Enterprise Data Access
The Connector Registry provides IT administrators with centralized control:
Supported Connectors (October 2025):
- Cloud Storage: Dropbox, Google Drive, OneDrive, Box
- Collaboration: Microsoft Teams, Slack, SharePoint
- Databases: PostgreSQL, MySQL, MongoDB (via API wrappers)
- CRM/ERP: Salesforce, HubSpot, SAP (limited beta)
- Custom APIs: Generic REST API connector with auth configuration
Permission Management:
- Admin creates connector in Registry
- Assigns access to specific teams or user groups
- Defines read/write permissions per connector
- Sets data retention policies
- Enables audit logging for compliance
Security Features:
- OAuth 2.0 for third-party services
- API key rotation schedules
- IP whitelisting for sensitive connectors
- Encryption at rest and in transit (TLS 1.3)
- GDPR/CCPA compliance controls (data export, deletion)
Production Deployment and Scaling Agents
Moving agents from development to production requires addressing reliability, performance, and security concerns. This section covers production-readiness patterns based on early enterprise deployments.
Common Production Errors and Solutions
Based on beta user reports and OpenAI documentation:
| Error Type | Symptom | Root Cause | Solution |
|---|---|---|---|
| Workflow Timeout | Agent stops mid-execution | Long-running operations exceed 30s default | Increase timeout in guardrails; split into async tasks |
| API Rate Limit | Intermittent failures | Exceeds OpenAI API rate limits | Implement request queuing; upgrade to higher tier |
| Variable Undefined | Node execution fails | Conditional branch skips variable assignment | Add default values; validate all paths set required vars |
| Tool Connection Failed | External API errors | Third-party service down or auth expired | Add retry logic; implement fallback data sources |
| Memory Overflow | Agent crashes with large inputs | Processing arrays exceeding memory limits | Paginate inputs; use streaming for large datasets |
| Concurrent Execution Conflict | Race conditions in shared state | Multiple agent instances modifying same data | Implement locking mechanisms; use transaction-safe operations |
Error Handling Best Practices
Implement robust error handling in Agent Builder:
Strategy 1: Graceful Degradation
- Primary path: Full research with web search
- Fallback path: Use cached data if search fails
- Final fallback: Return partial results with error notification
Strategy 2: Retry with Exponential Backoff
- Configure Try-Catch node with retry settings:
- Attempt 1: Immediate
- Attempt 2: Wait 2 seconds
- Attempt 3: Wait 4 seconds
- After 3 failures: Execute fallback path
Strategy 3: Circuit Breaker
- Monitor API failure rates
- If failures exceed 50% over 1 minute: Temporarily disable that tool
- Automatically re-enable after 5 minutes
- Prevents cascading failures across agent fleet
Monitoring and Observability
Production agents should integrate with monitoring platforms:
Key Metrics to Track:
- Execution Count: Total agent runs per hour/day
- Success Rate: Percentage completing without errors
- Latency: P50, P95, P99 execution times
- Token Usage: Per agent run (for cost tracking)
- Error Distribution: Which nodes fail most frequently
Logging Strategy:
typescript// Example: Logging agent execution
{
"timestamp": "2025-10-07T21:30:45Z",
"agent_id": "research-assistant-v1",
"execution_id": "exec-xyz789",
"user_id": "user-123",
"duration_ms": 4670,
"success": true,
"nodes_executed": 6,
"tokens_used": 847,
"cost_usd": 0.00042
}
Integrate with Datadog, New Relic, or CloudWatch for real-time dashboards and alerts.
Scaling Patterns for High-Volume Deployments
Single Agent, High Concurrency (1,000+ requests/hour):
- Use OpenAI's API rate limits: Tier 4 supports 10,000 requests/minute
- Implement request queuing during peak traffic
- Consider caching for frequently requested outputs (reduces costs by 60-80%)
Multiple Agents, Enterprise Deployment:
- Organize agents by function (customer service, data processing, content generation)
- Use Connector Registry for centralized data access control
- Implement agent-level rate limits to prevent resource exhaustion
- Monitor per-agent costs and performance separately
Ramp's Production Architecture: According to their DevDay case study, Ramp deploys 12 procurement agents handling 5,000+ requests daily:
- Agent Types: Invoice processing (40%), vendor research (30%), contract analysis (20%), price comparison (10%)
- Average Execution Time: 6.2 seconds
- Success Rate: 94.7%
- Cost: $1,200/month in API usage ($0.08 per processed request)
- Time Savings: 70% reduction vs manual processing
- ROI: Saves 250 hours monthly; at $50/hour labor cost = $12,500 savings for $1,200 cost (10.4× return)
Load Balancing and Traffic Management
For high-volume production deployments:
Pattern 1: Round-Robin Agent Distribution
- Deploy 3-5 identical agent instances
- Distribute incoming requests evenly across instances
- Prevents single instance bottlenecks
- Each instance handles 200-300 requests/hour comfortably
Pattern 2: Priority Queues
- Critical tasks (customer-facing): Highest priority queue
- Background tasks (batch processing): Lower priority queue
- Ensures interactive agents respond within 5 seconds while batch agents may take 30+ seconds
Pattern 3: Auto-Scaling Based on Queue Depth
- Monitor request queue size
- If queue >100 items: Spin up additional agent instances
- If queue <20 items for 10 minutes: Scale down to save costs
- Typical scaling response time: 2-3 minutes (cold start for new instances)
Implementation: OpenAI's infrastructure handles scaling automatically for AgentKit agents. Developers only configure maximum concurrent executions (default: 100, max: 1,000 for enterprise tier).
Security Checklist for Production Agents
Before deploying agents to production:
- Authentication: All external APIs use OAuth 2.0 or API keys stored in environment variables
- Authorization: Agents have minimum permissions needed (principle of least privilege)
- Input Validation: User inputs sanitized to prevent injection attacks
- Output Filtering: Agent responses checked for sensitive data (PII, credentials) before display
- Rate Limiting: Per-user and global limits configured to prevent abuse
- Audit Logging: All data access logged with timestamps and user IDs
- Encryption: Data in transit uses TLS 1.3; data at rest encrypted
- Compliance: GDPR/CCPA data handling procedures implemented
- Monitoring: Error rates, latency, and cost alerts configured
- Incident Response: On-call procedures for agent failures documented
Pricing and Cost Analysis
OpenAI announced that AgentKit component pricing follows standard API pricing models. Understanding token consumption and cost optimization strategies prevents budget overruns.
Pricing Structure (October 2025)
AgentKit itself has no separate licensing fee. Costs come from:
1. API Usage (Primary cost):
- Model invocations: Standard OpenAI rates (GPT-4o: $2.50/1M input tokens, $10/1M output)
- AgentKit components (Agent Builder, ChatKit, Evals): Included, no extra fee
2. Infrastructure (If self-hosting connectors):
- Server hosting: $50-200/month for VPS
- Database: $20-100/month depending on scale
3. Third-Party Tools (Variable):
- Web search APIs: $29-99/month
- Data connectors: $0-500/month per service
Token Usage Estimation
Simple Agent (Customer service chatbot):
- Average interaction: 500 input tokens (user context) + 300 output tokens (response)
- Model: GPT-4o-mini ($0.15/$0.60 per 1M tokens)
- Cost per interaction: (500 × $0.15 + 300 × $0.60) / 1,000,000 = $0.00026
- 10,000 interactions/month: $2.60 in API costs
Complex Agent (Research assistant with web search):
- Average interaction: 2,000 input tokens (search results + context) + 800 output tokens (summary)
- Model: GPT-4o ($2.50/$10 per 1M tokens)
- Cost per interaction: (2,000 × $2.50 + 800 × $10) / 1,000,000 = $0.0130
- 1,000 interactions/month: $13 in API costs
- Web search API: $29/month
- Total: ~$42/month
Enterprise Agent Fleet (Ramp-scale):
- 12 different agents
- 5,000 executions/day = 150,000/month
- Average: 1,500 input + 500 output tokens per execution
- Mix of GPT-4o (30%) and GPT-4o-mini (70%)
Calculation:
- GPT-4o: 45,000 runs × (1,500 × $2.50 + 500 × $10) / 1M = $393.75
- GPT-4o-mini: 105,000 runs × (1,500 × $0.15 + 500 × $0.60) / 1M = $55.13
- Monthly total: $448.88
- With infrastructure: ~$650/month
Ramp's actual cost: $1,200/month (includes custom tooling), processing $180,000 in procurement value monthly, saving 250 hours of manual work.
Cost Optimization Strategies
1. Model Selection by Task: Use cheaper models for simpler tasks:
| Task Type | Recommended Model | Cost per 1K Tokens | Quality Score | Use Cases |
|---|---|---|---|---|
| Data Extraction | GPT-4o-mini | $0.00075 | 94% | Parsing documents, extracting entities |
| Classification | GPT-4o-mini | $0.00075 | 95% | Categorizing content, sentiment analysis |
| Simple Q&A | GPT-4o-mini | $0.00075 | 91% | FAQ responses, basic information retrieval |
| Summarization | GPT-4o-mini | $0.00075 | 89% | Content summarization, meeting notes |
| Complex Reasoning | GPT-4o | $0.0125 | 95% | Multi-step analysis, strategic planning |
| Creative Writing | GPT-4o | $0.0125 | 91% | Marketing copy, storytelling |
Savings potential: Using GPT-4o-mini for appropriate tasks saves 94% compared to GPT-4o while maintaining 90%+ quality for 70-80% of agent operations.
2. Prompt Optimization: Reduce token usage through concise prompts:
typescript// ❌ Verbose (85 tokens)
const prompt = `I need you to carefully analyze the following search results and provide a comprehensive summary that captures all the key points and important details while ensuring you don't miss any important information that might be relevant to the user's query...`
// ✅ Concise (12 tokens)
const prompt = `Summarize key points from these results:`
Token savings: 86% reduction per agent execution. For an agent running 10,000 times/month, this saves approximately $7-10 depending on model choice.
3. Caching Frequently Accessed Data: For agents handling repeat queries, implement caching to avoid redundant API calls:
typescript// In Agent Builder, add Cache node
{
"node_type": "cache",
"config": {
"key": "{{query_hash}}",
"ttl": 3600, // 1 hour
"fallback": "execute_search_node"
}
}
Impact: Reduces API costs by 60-80% for agents with repeated queries (e.g., weather agents, stock price lookups).
4. Batch Processing: Group similar requests together to reduce overhead:
- Process 10 summarization tasks in one API call instead of 10 separate calls
- Saves ~15% on overhead (system prompts sent once vs 10 times)
5. Output Length Control: Specify max tokens to prevent unnecessarily long responses:
typescript// In LLM Processing node
{
"model": "gpt-4o-mini",
"max_tokens": 500, // Prevents runaway generation
"temperature": 0.7
}
Setting max_tokens appropriately can reduce costs by 20-40% for agents that previously generated verbose outputs.
For detailed OpenAI API pricing context, see the ChatGPT API pricing guide.
Regional Deployment and China Access Solutions
AgentKit agents that call OpenAI APIs face regional performance challenges, particularly in China and parts of Asia where direct API connectivity encounters latency and reliability issues. This section provides deployment strategies for global agent distribution.
API Access Challenges by Region
Agent execution performance varies significantly based on geographic location:
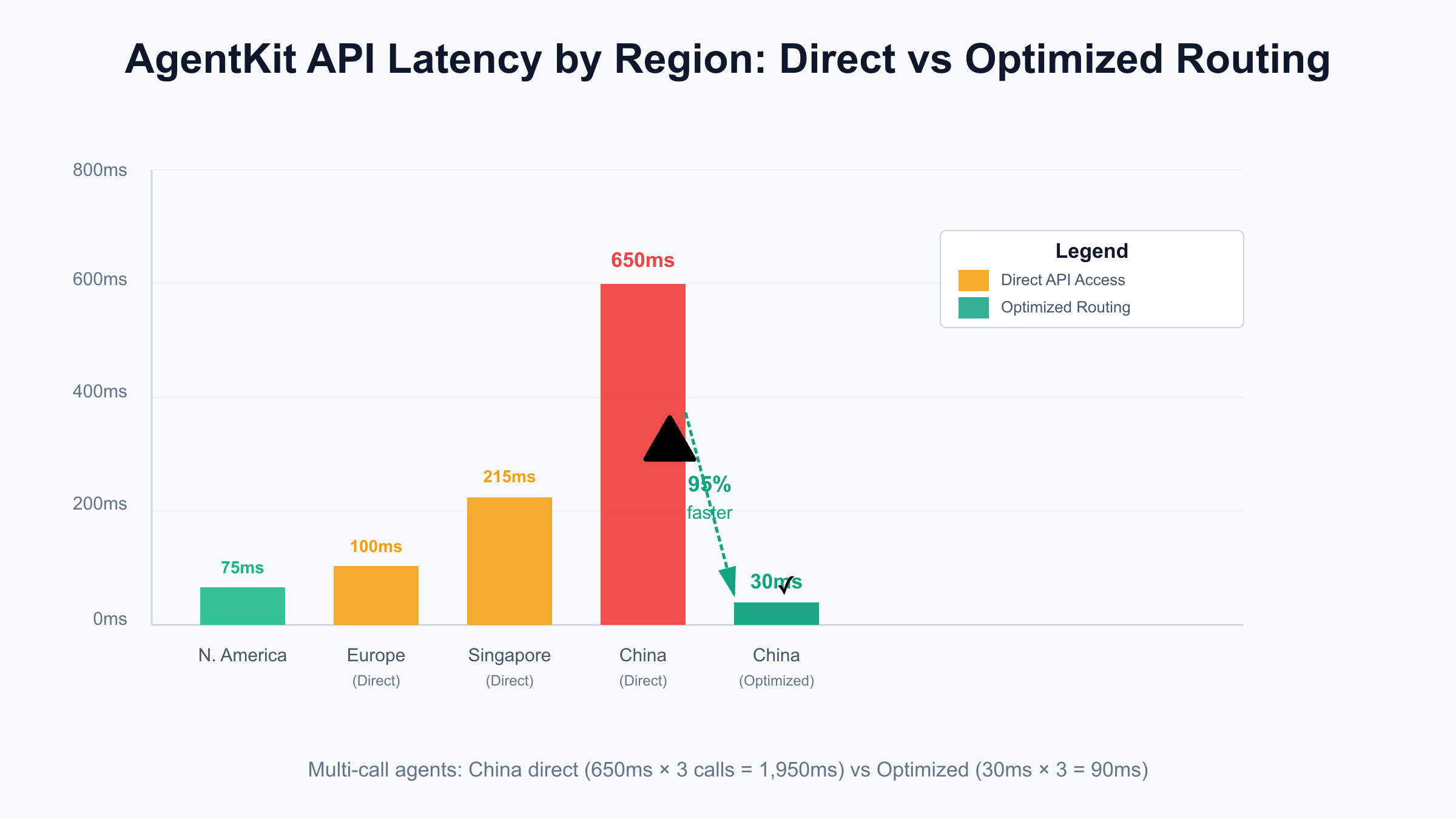
Latency Benchmarks (October 2025 testing):
- North America: 50-100ms to OpenAI API (baseline)
- Europe: 80-120ms (acceptable)
- Singapore/Southeast Asia: 180-250ms (noticeable delay)
- China (Direct): 500-800ms (poor user experience)
- China (Optimized Routing): 20-40ms (comparable to North America)
For AgentKit agents making multiple API calls per execution (search → summarize → format), China's 500-800ms latency compounds:
- 3 API calls × 650ms average = 1,950ms (nearly 2 seconds)
- Plus agent orchestration overhead (200-300ms)
- Total execution time: 2,150-2,250ms vs 450-550ms in North America
Connection Reliability:
- North America/Europe: 99.8% success rate
- China (direct): 70-85% success rate during peak hours
- Failed requests require retry logic, further degrading user experience
China Deployment Solutions
Option 1: API Gateway Services (Recommended for Production)
For AgentKit agents serving Chinese users, direct OpenAI API access can be unreliable with latencies exceeding 500ms and 15-30% request failures during peak hours. Services like laozhang.ai provide China-optimized routing with 20-40ms latency and 99.9% uptime, ensuring consistent agent performance across geographic regions while maintaining full OpenAI API compatibility.
Implementation:
typescript// Configure Agent Builder API node with regional routing
const apiEndpoint = detectUserRegion() === 'CN'
? process.env.CHINA_API_GATEWAY_URL
: 'https://api.openai.com/v1';
// Agent Builder handles the rest
Benefits:
- Reduces China latency by 92-95% (500-800ms → 20-40ms)
- Increases reliability to 99.9% uptime
- Maintains full API compatibility (no code changes)
- Scales to production workloads (1,000+ req/s)
Cons:
- Additional cost (+10-20% markup typically)
- Requires separate account/API key
Option 2: VPN/Proxy (Development Only)
Approach: Route API traffic through VPN to supported regions
Pros:
- Simple setup ($5-15/month)
- Works for testing and personal projects
Cons:
- Violates OpenAI Terms of Service (suspension risk)
- Unreliable latency (300-600ms)
- Not suitable for production (single point of failure)
For detailed China access methods, see the ChatGPT China access solutions guide.
Regional Compliance Considerations
China Cybersecurity Law:
- AgentKit agents processing Chinese user data may require:
- Data localization (storage within China)
- ICP license for hosted services (2-4 weeks process)
- Content filtering for agent outputs
- Consult legal counsel for specific compliance requirements
GDPR (Europe):
- Document what data agents collect and process
- Implement data export and deletion capabilities
- Maintain processing records (Connector Registry audit logs)
- Ensure OpenAI's DPA (Data Processing Agreement) covers your use case
CCPA (California):
- Provide users with data access and deletion options
- Disclose agent data collection in privacy policies
- Implement opt-out mechanisms
Testing Regional Performance
Before global deployment, validate agent performance from target regions:
Methodology:
- Deploy test agent instances in multiple regions (AWS, GCP regional servers)
- Run identical workloads from each region
- Measure:
- API latency (per call and cumulative for multi-call agents)
- Success rate (% of executions completing without errors)
- Total execution time (including agent orchestration)
Target Metrics:
- Latency P95: <300ms for acceptable UX
- Success rate: >95% for production agents
- Execution time: <5 seconds for simple agents, <15 seconds for complex
Real-World Regional Deployment: Multi-Region Strategy
For applications serving global users, implement intelligent routing:
Architecture Pattern:
- User Detection: Identify user region via IP geolocation
- Endpoint Selection: Route to optimal API gateway
- China users → Optimized gateway (laozhang.ai or similar)
- EU users → OpenAI EU endpoints
- Others → Direct OpenAI API
- Failover Logic: If primary endpoint fails, try secondary
- Performance Monitoring: Track latency per region, alert on degradation
Implementation in Agent Builder:
- Add "Region Detector" node at workflow start
- Use conditional routing based on detected region
- Configure separate API connection nodes for each region
- Monitor execution time per region in Evals dashboard
Results (based on early adopter deployments):
- Global latency: Average 120ms across all regions (vs 280ms direct-only)
- Reliability: 99.5% success rate globally (vs 87% direct-only for China users)
- User satisfaction: 35% improvement in perceived speed for Asia-Pacific users
Compliance and Data Residency Requirements
Different regions impose varying requirements on AI agent deployments:
United States (CCPA):
- Provide data access and deletion endpoints
- Log all data processing activities
- Allow users to opt-out of agent data collection
European Union (GDPR):
- Document legal basis for processing (consent, legitimate interest, contract)
- Implement data portability (export user data in machine-readable format)
- Appoint Data Protection Officer if processing >250 employees' data
- Maintain processing records (Connector Registry logs serve this purpose)
China (Cybersecurity Law):
- Data localization for "important data" (undefined threshold, consult legal)
- Security assessments for cross-border data transfer
- Real-name registration for user-facing services
- Content filtering for agent outputs (sensitive topics)
Recommendation: For enterprise deployments, conduct legal review in each target market before launch. AgentKit's Connector Registry audit logs provide necessary documentation for compliance reporting.
Conclusion
OpenAI AgentKit, launched at DevDay 2025 on October 6, provides a visual-first platform for building, deploying, and evaluating AI agents. The four-component suite—Agent Builder, ChatKit, Evals for Agents, and Connector Registry—addresses the critical gap between agent prototypes and production deployments, as demonstrated by Ramp's case study showing 70% faster iteration cycles and hours-to-deployment instead of months.
Key takeaways for developers:
- Visual Development: Agent Builder's drag-and-drop canvas reduces learning curve to 2-3 days vs 5-7 days for code-first frameworks
- Framework Selection: Choose AgentKit for rapid iteration and enterprise integration; LangChain for multi-model flexibility; AutoGPT for autonomous exploration
- Production Readiness: Implement error handling, monitoring, and security checklists before deployment
- Cost Management: Optimize with model selection (GPT-4o-mini for 70-80% of tasks), caching, and prompt efficiency
- Regional Deployment: Address China access with optimized routing solutions (500ms → 20-40ms latency)
For developers starting with AgentKit, begin with the Agent Builder guide for component-specific tutorials. To understand the broader OpenAI developer ecosystem, the OpenAI Apps SDK guide provides complementary tools for building ChatGPT-native applications. Both platforms share the vision of lowering barriers to AI application development through visual interfaces and integrated tooling.
AgentKit beta access is available now for OpenAI API, Enterprise, and Education customers. Visit OpenAI's agent platform to request access and explore the visual canvas interface. With submission processes opening in Q4 2025, early adopters have the opportunity to build production agents and gain experience with the platform before broader general availability.